9.DataFrame拼接数据
.append()拼接(该方法可能无法使用)
注意,.append()方法可能被移除
.append()方法可以支持两个Series或DataFrame之间的拼接,拼接后,返回一个新的对象,被用来拼接的两个对象原本的Index与列标签仍然被保留,可以通过添加参数(ignore_index=True),为新生成的对象使用默认的从0开始的数字Index(忽略原来的Index)
示例:s1.append(s2)
如果两个DataFrame的列标签不一样,仍然会得到包含两个DataFrame所有列标签的DataFrame,只不过缺失的Index位置的值会被NaN填充
需要注意的是,拼接只是将一个DataFrame或Series的内容,直接插入另一个对象的末尾,如果想要将两个对象相同位置的数据相加,直接使用df1+df2这样的方法即可
pd.concat()
concat()是pandas库里的一个函数,因此一般被写作【pd.concat()】,会返回一个新的对象
pd.concat()比.append()运行速度更快,同时提供了更多的可选参数
连接两张表的基本语法格式是:【pd.concat([df1,df2])】注意被合并的两张表要放入方括号内
新创建的DataFrame也会保留之前被DataFrame中所有原来的的列标签与Index,效果与.append()方法相同,同时也可以添加【ignore_index=True】参数,为新生成的对象使用默认的从0开始的数字Index(忽略原来的Index)【默认重行不重列,相同列标签的保留成一列】
pd.concat()有个axis参数,默认axis=0,如果设置axis=1,就可以实现从左到右的合并,这时候相同index的内容都会放在同一行,同时可能出现多个相同的列标签(与axis=0时相反),缺失的位置会被填充NaN【重列不重行,相同Index的保留成一行】
如果只希望新创建的对象保留两张DataFrame都有的列标签和Index的内容,需要设置参数【join=’inner’】,相当于在重列不重行或重行不重列的的基础上加了新的规则【不重者删除】,
也就是让两张表使用“内连接”的方法合并,(默认外连接,即保留所有的行列),只保留 在两张DataFrame中都存在的Index和列标签的内容
设置inner相当于取两个数据集的交集,否则就是两个数据集的并集(outer)
在axis=0的情况下,只保留两张DataFrame都有的列标签的内容,其他列标签会被删除,在axis=1的情况下,只保留两张DataFrame都有的Index的行,其他行都被删除
Outer Join:
A B C
x 1.0 3.0 NaN
y 2.0 4.0 NaN
y 5.0 NaN 7.0
z 6.0 NaN 8.0
Inner Join:
A
x 1
y 2
y 5
z 6
10.merge方法连接数据
可以理解为将不同的数据表根据某个列标签来连接在一起
merge()是pandas中的一个库函数,所以使用时一般写【pd.merge()】
它的效果与Excel中的vlookup类似,但更强大,它的作用是,根据两张(或更多)数据表中,一个活多个共有的键(列标签或Index)来合并两张数据表,然后返回一个新的DataFrame
重要的是,合并结果中,另一张DataFrame中的行的顺序会被改变,因为与前一张DataFrame中的行进行了匹配
merge()返回的新df会丢失原来的索引,用自动生成的从0开始的数字替代
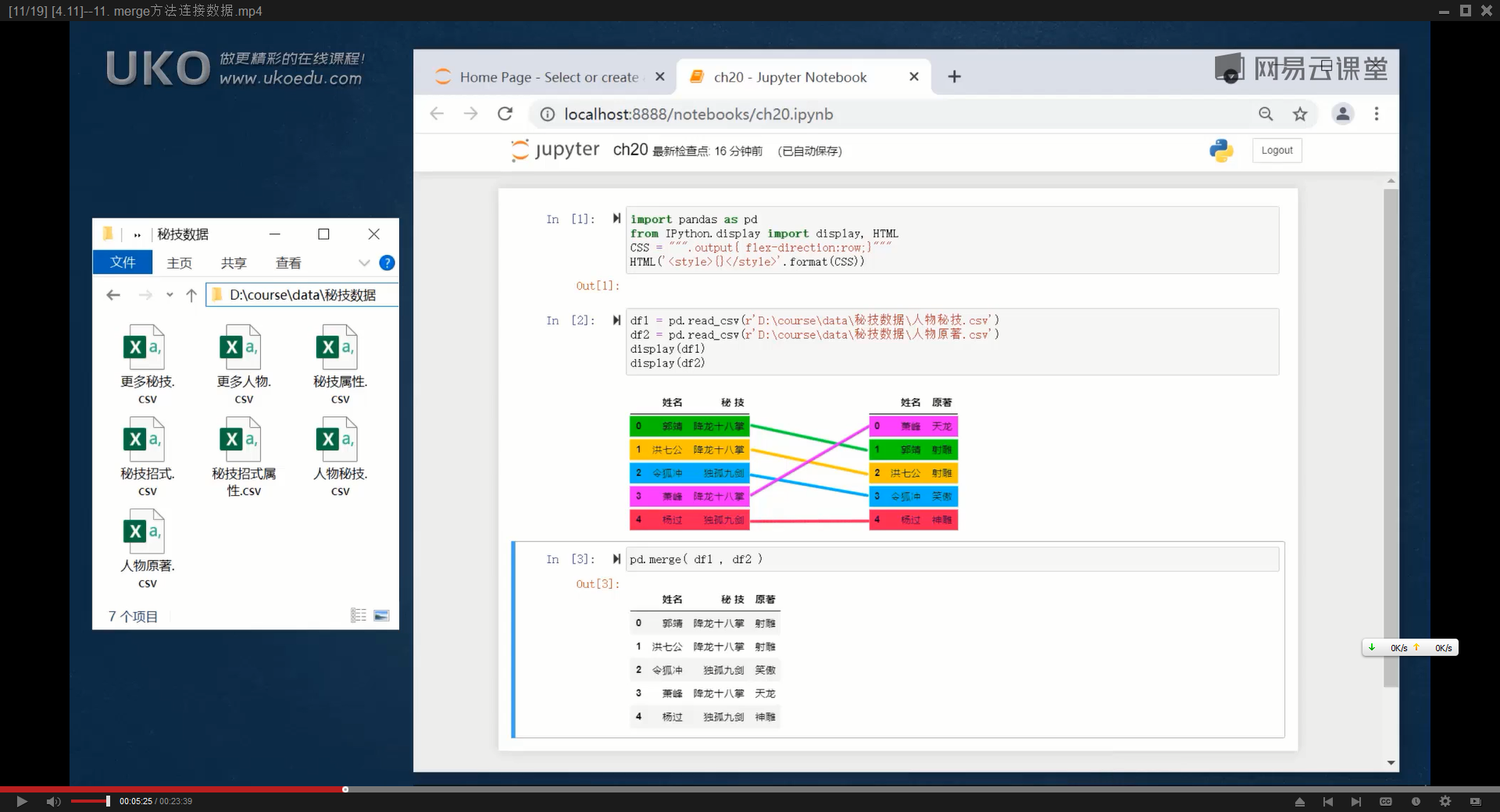
如果两张DataFrame中的行数不一致,merge()方法还能够进行‘复制补全’操作
(一对多关系)
比如第一张数据表中两列分别是姓名和性别,有10行,
第二张数据表中只有性别列和“位置”列(随便想的),只有男/女两行,pd.merge(df1,df2)得到的合并结果,依然是10行,并且每一个姓名都根据‘性别’列匹配到了‘位置’
import pandas as pd
df1 = pd.DataFrame({'姓': ['李', '黄', '陈','ve','cos'], '技能': ['x', 'y', 'z','x','y']})
df2 = pd.DataFrame({'伤害': [3, 2, 1], '技能': ['z', 'y', 'x'], '功能': ['c', 'b', 'a']})
#merged_df = pd.merge(df1, df2, left_on=['列标签1', '列标签2'], right_on=['列标签1', '列标签2'])
merged_df = pd.merge(df1, df2)
print(merged_df)
'''
姓 技能 伤害 功能
0 李 x 1 a
1 ve x 1 a
2 黄 y 2 b
3 cos y 2 b
4 陈 z 3 c'''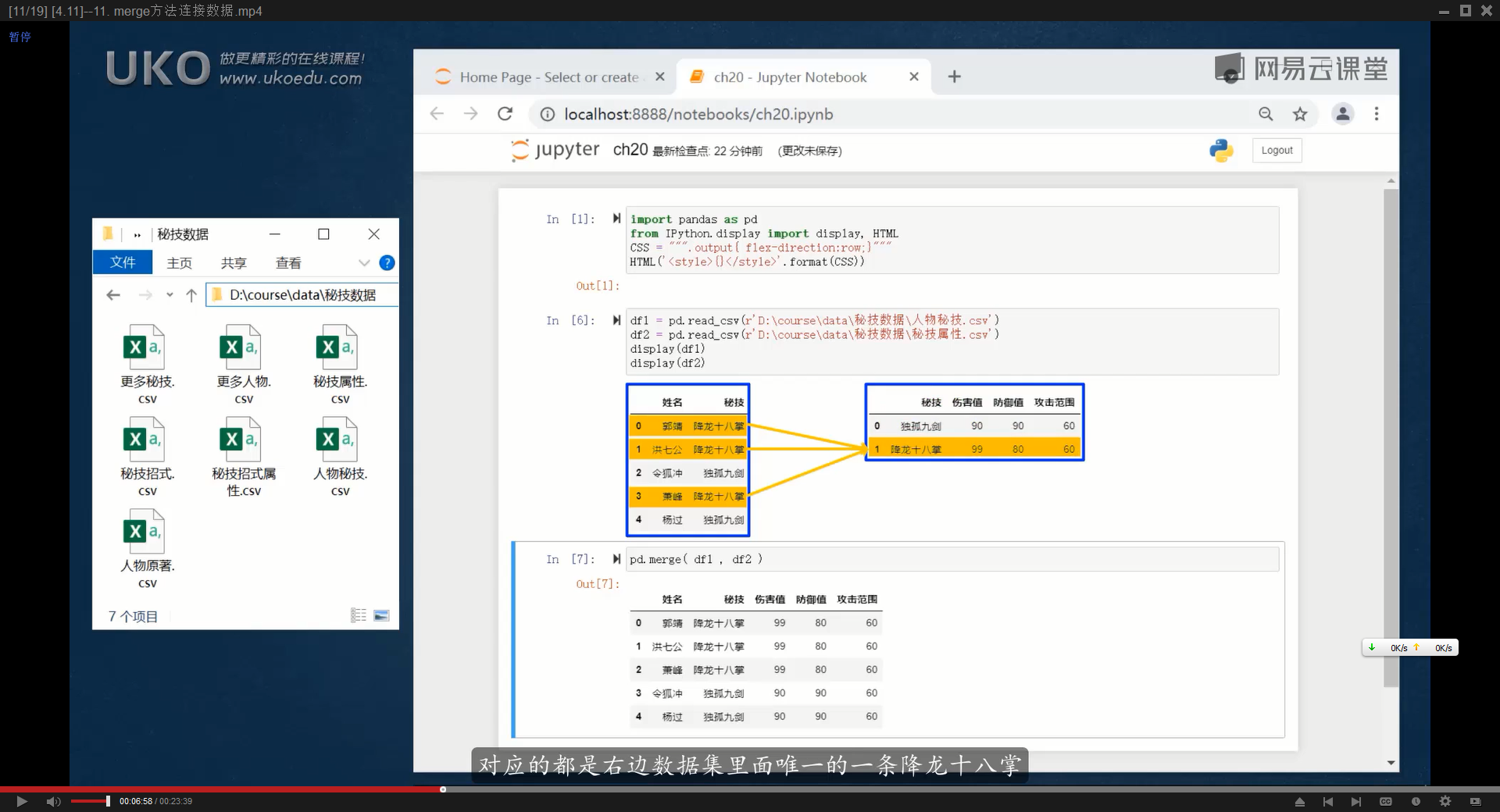
(多对多关系)类似于vlookup中,一个关键词能匹配到多个结果,但vlookup永远只直返第一个结果,而pd.merge()方法是,如果一个关键词能匹配到多个结果,就复制多行
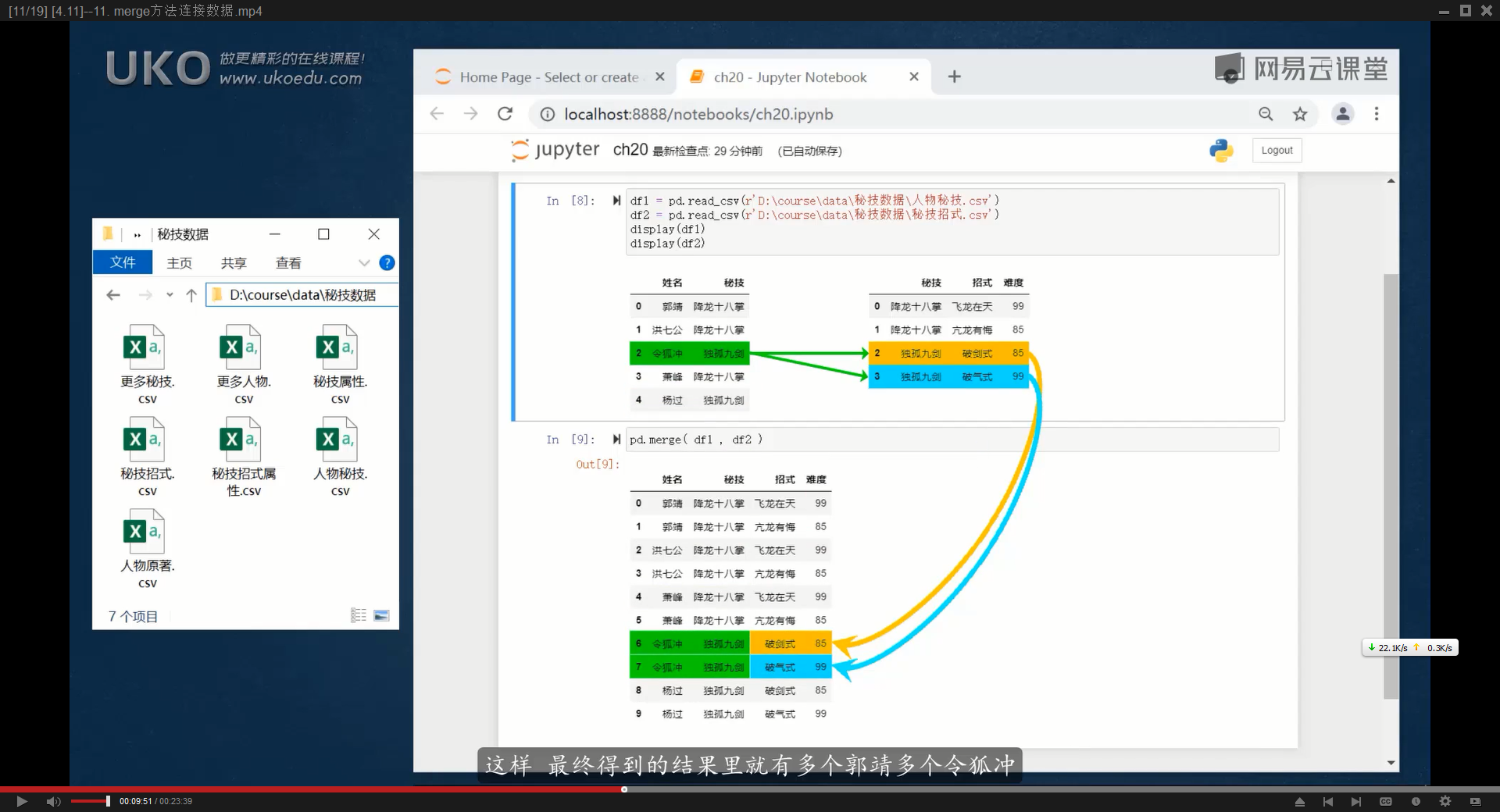
默认情况下,取两个DataFrame的交集,更繁琐的解释是:
如果两个DataFrame中有两个相同的列标签,那么pd.merge(df1,df2)默认会查找两个DataFrame中相同的列标签,然后进行匹配,匹配结果中,只有两个列标签下相同关键字都一致,这一行的内容才会出现在匹配结果,否则就不会出现在返回结果中
简单来说,就是把这两个列标签作为匹配的关键词,如果另一个DataFrame中并没有某一行同时存在两个相同的词,匹配不到,就不会出现在返回结果中
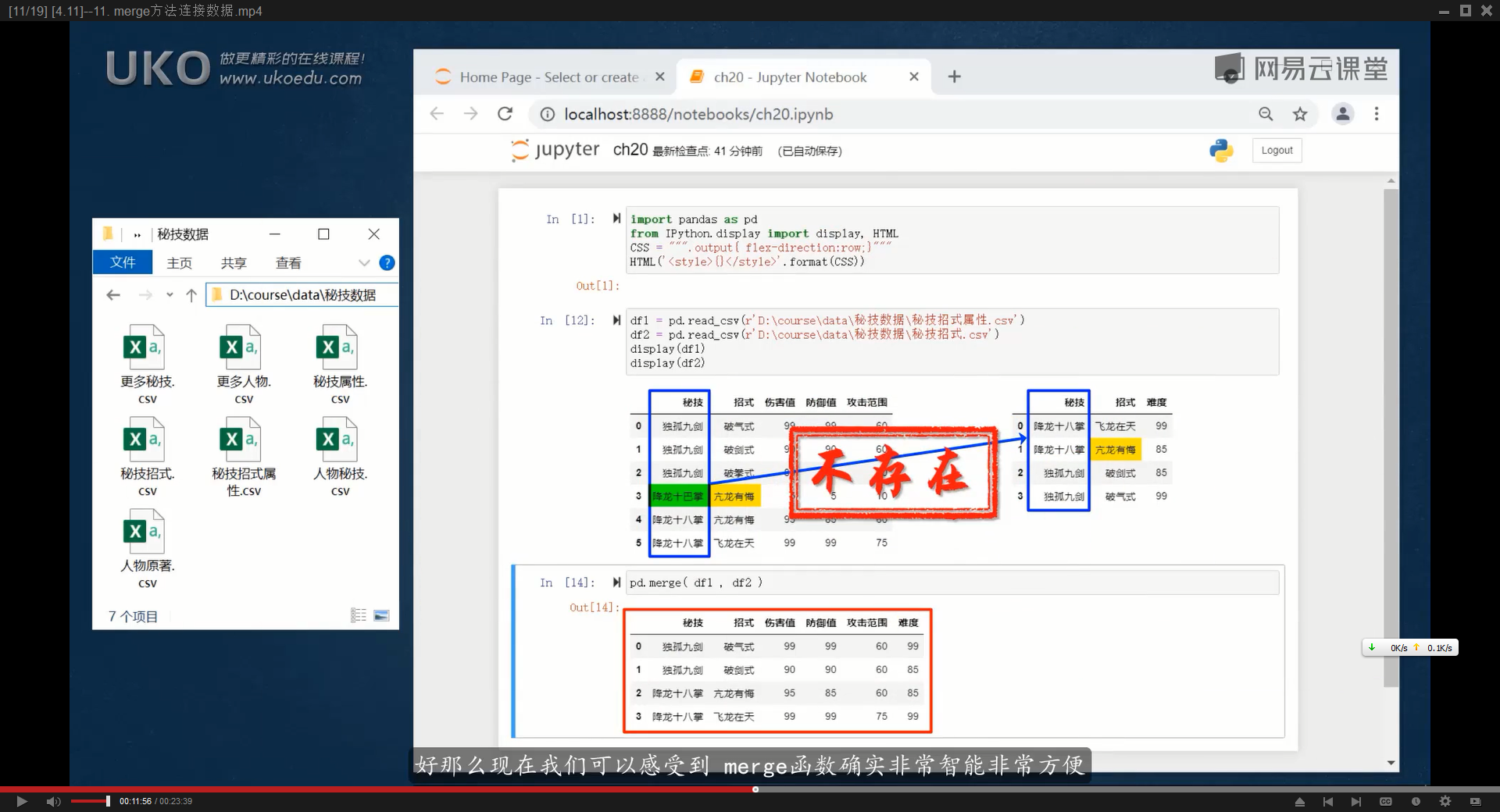
如果想要取两张数据表的并集,可以设置参数【how=’outer’】,缺失值会用NaN来填充
outer表示数据库关系运算中的外连接(与之相反的内连接的意思是,检查每一条记录是否出现在数据集的内部,pd.merger()默认how=’inner’)
merge的基本语法
pd.merge(left,right,how=’inner’,on=None,left_on=None,right_on=None)
left和right分别表示左右两边用于合并的dataframe
how用于指定合并的类型,参数可以是:left/right/outer/inner
left表示左外连接,匹配结果只保证左边数据表每个关键词都得到匹配结果,默认是inner外连接,取两张数据表的交集,因此可能会出现匹配结果的第一列中出现nan的情况
right表示右外连接,与left同理
on指定用于连接的列标签名字,该列标签必须在两个DataFrame中都存在(如果能得到N个匹配结果,就会返回N行)
left_on表示左侧DataFrame中用于连接的列(可以指定多列,放在一个列表中)
right_on表示右侧DataFrame中用于连接的列
ritht_index=True表示将右边DataFrame的index作为键
left_index=True同理
通常情况下,指定了on参数后,就不需要设置left_on和right_on这两个参数,
left_on和right_on经常用于以下几种情况:
1.当两个dataframe有两个相同信息/含义的列,但列标签的名字不同,
2.当两个DataFrame中,各自都有多个相同含义的列标签,
import pandas as pd
df1 = pd.DataFrame({'列标签1': [1, 2, 3], '列标签2': ['x', 'y', 'z'], '列标签3': ['a', 'b', 'c']})
df2 = pd.DataFrame({'列标签1': [3, 2, 1], '列标签2': ['z', 'y', 'x'], '列标签6': ['c', 'b', 'a']})
merged_df = pd.merge(df1, df2, left_on=['列标签1', '列标签2'], right_on=['列标签1', '列标签2'])
#merged_df = pd.merge(df1, df2,on='列标签1')
print(merged_df)
'''
列标签1 列标签2 列标签3 列标签6
0 1 x a a
1 2 y b b
2 3 z c c'''需要注意的是,如果两个DataFrame,有多个重名的列标签,但on参数仅仅指定了一个列标签作为键,那么合并后的结果,会对其他没有指定为键,但名字都相同的列标签进行重命名,通常是加上_x与_y的后缀
比如以下代码中,两个DataFrame都有“列标签2”,在合并结果中,有两列的名字分别是“列标签2_x”和“列标签2_y”
import pandas as pd
df1 = pd.DataFrame({'列标签1': [1, 2, 3], '列标签2': ['x', 'y', 'z'], '列标签3': ['a', 'b', 'c']})
df2 = pd.DataFrame({'列标签1': [3, 2, 1], '列标签2': ['z', 'y', 'x'], '列标签6': ['c', 'b', 'a']})
#merged_df = pd.merge(df1, df2, left_on=['列标签1', '列标签2'], right_on=['列标签1', '列标签2'])
merged_df = pd.merge(df1, df2,on='列标签1')
print(merged_df)
'''
列标签1 列标签2_x 列标签3 列标签2_y 列标签6
0 1 x a x a
1 2 y b y b
2 3 z c z c'''11.重置索引与数据排序
merge()之后重新使用原来的索引
由于merge()返回的新DataFrame会丢失原来DataFrame的Index,
如果希望将原来的index保留,可以先在原来的DataFrame中,将index复制为DataFrame中的普通列【df[‘新列’]=df.index】,
然后再执行正常的merge(),
最后将merge()返回的DataFrame的index,改成新df中的某一列【new_df.index=new_df[‘列标签’]】
如果不喜欢index和某一列的内容重复,可以将那个重复列删除【df.drop(‘列标签’),axis=1,inplace=True】,axis=1表示删除列,而不是根据索引来删除某一行
sort_values()对数据集重新排序
sort_values()可以根据一列或多列数据,对DataFrame中的数据重新排序
最简单的用法是【df=df.sort_values(by=’列标签’)】,默认根据指定列标签的内容从小到大进行排序
也可以根据多列进行排序【df=df.sort_values(by=[‘列标签1′,’列标签2’])】
sort_values参数
| by | 指定用于排序的列名或列名列表 |
| axis | 要排序的轴,0代表行,1代表列,默认为0,对行进行排序 |
| ascending | 布尔值或布尔值列表,True表示升序,False表示降序,默认为True升序,也就是从小到大 |
| inplace | 设置True为直接对原来的DataFrame进行修改,默认False |
| na_position | 由于NAN值无法与数值进行比较,可以选择将NAN放在最前或最后如何处理空值NaN,可以选择 ‘first’ 或 ‘last’,默认为’last’,当设置为’first’时,所有的NaN(不是数字的值)会被放在排序后的DataFrame的顶部,即它们会成为排序后列表的第一项,反之他们会被放在排序后的DataFrame的底部 |
| ignore_index | 是否重置索引,默认为False |
可以根据多列进行排序,只需要将关键的列标签放入一个列表中,再把ascending的参数设置一个列表(与列标签数量对应,否则默认全部按照同一个acending方式排列)
比如当列1的数值一样时,再根据列2的数值进行排序,当列2的数值一样时,在比较列3
【df.sort_values([‘卧室’,’面积’,’总价’],acending=[True,False,False])】
如果sort_values()设置的用来排序的列的内容全是字符串,它的排序方式并不是按照拼音,而是根据字符串的Unicode码位,
如果希望根据某一列的拼音进行排序,可以新建一个列,该列的内容是用来排序的列的拼音,可以使用第三方库将中文字符串转换成拼音,比如【py install pinyin】
【pinyin.get(‘字符串’)】可以获得字符串的拼音形式,该模块可以指定转换出来的拼音不带有声调格式【pinyin.get(‘拼音’,format=’strip’)】,得到的结果就是标准的英文字母,然后再排序
可以通过apply()方法对某一列进行计算,具体的代码是【data[‘列标签’].apply(pinyin.get,format=’strip’)】注意apply()中函数的参数写法,不是写在函数的括号中,而是跟着函数名的逗号之后
chatGPT给出的另一个方案;
import pandas as pd
from pypinyin import lazy_pinyin
# 创建一个包含中文字符串的 DataFrame
df = pd.DataFrame({
'Chinese': ['苹果', '香蕉', '橙子', '桃子']
})
# 使用 lazy_pinyin 将中文转换为拼音
# 将 DataFrame 中的 'Chinese' 列转换为拼音,并连接拼音列表以生成完整拼音字符串
df['Pinyin'] = df['Chinese'].apply(lambda x: ''.join(lazy_pinyin(x)))
# 按照拼音列进行排序
df_sorted = df.sort_values(by='Pinyin')
# 打印排序后的 DataFrame(可选:删除拼音列)
print(df_sorted.drop(columns=['Pinyin']))
sort_index()让DataFrame根据index进行排序
用法与sort_values()一致,因为index只有一列,所以不需要指定根据什么进行排序,可以指定ascending为True或False
12.groupby()方法分组与统计
.groupby()方法返回的是一种对象,无法直接print(),之后要需要指定计算统计方法
.groupby()可以用于数据分组,将大量数据细分为组进行更详细的分析,通常与聚合函数如(sum/mean/max/min等)一起使用,使你能够在一个活多个列(键)上进行分组,然后对每个组应用一个或多个聚合操作。
被用于goupby()的列标签通常有多个相同的单元格(几个重复的属性),groupby()方法会将指定列标签下所用相同的单元格的行合并在一起,并且应用指定的计算方法,比如sum()就是将这一列相同内容的单元格数字相加或者文本合并。
如果只想得到某一列的sum(),可以写成【df.gourpby(‘列标签1’)[”列标签2].sum()】,这条代码是,先对DataFrame根据某一列进行groupby,然后取出某一列,再计算sum()。
import pandas as pd
data = {
'Company': ['Google', 'Google', 'Microsoft', 'Microsoft', 'Facebook', 'Facebook'],
'Person': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'Sales': [200, 120, 340, 124, 243, 350]
}
df = pd.DataFrame(data)
print(df)
'''
Company Person Sales
0 Google Sam 200
1 Google Charlie 120
2 Microsoft Amy 340
3 Microsoft Vanessa 124
4 Facebook Carl 243
5 Facebook Sarah 350'''
print('---------')
grouped=df.groupby('Company')
print(grouped.sum())
'''
Person Sales
Company
Facebook CarlSarah 593
Google SamCharlie 320
Microsoft AmyVanessa 464'''groupby对象常用统计分析方法
| .sum() | 计算组内数值类型数据的总和 |
| .mean() | 计算组内数值类型数据的平均值 |
| .min() | 取得组内数据的最小值 |
| .max() | 得到组内数据的最大值 |
| .count() | 统计每一组每一列中有多少个非空值 |
| .size() | 计算组内元素的总数量(包括空值),也可以理解成统计每一组在原始df中有多少行 |
| .describe() | 为数值型列申城描述性统计摘要 |
| .var() | 计算组内方差 |
| .std() | 计算组内标准差 |
| .median() | 计算组内中位数 |
| .quantile(q) | 计算组内的分位数,其中q是介于0和1之间的数 |
| .agg() | 使用一个或多个操作进行分组级运算 |
| .first() | 返回组内第一个非空元素 |
| .last() | 返回组内最后一个非空元素 |
| .nth(n) | 返回组内第n个非空元素 |
| .sem() | 计算组内的标准误差 |
| .get_group(name) | 返回指定名称的组 |
| .groups | 属性,返回一个字典,该字典将组名映射到组成该组的索引 |
| .ngroups | 属性,返回组的数量 |
| .indeces | 属性,提供一个字典,将组键映射到组内的索引 |
| .cumcount(ascending=True) | 返回组内元素的累计技术 |
| .cumsum() | 返回组内元素的累计和 |
| .cumprod() | 返回组内元素的累计积 |
| .cummax() | 返回组内元素累计最大值 |
| .cummin() | 返回组内元素累计最小值 |
| .rank(method=’average’) | 在每个组内对元素进行排名 |
| .head(n) | 返回每个组前n个元素 |
| .tail(n) | 返回每个组后n个元素 |
| .shift(periods=1,fill_value=None) | 在每个组内对数据进行位移 |
| .iteritems() | 迭代(键,值)对 |
| .itertuples(name=’Pandas’) | 迭代命名元组 |
.agg()可以使用一个或多个操作进行分组级运算
【grouped.agg({‘Sales’: [‘sum’, ‘mean’], ‘Employee’: ‘count’})】
.agg()/.aggragate()分组聚合
.agg()与.agggragate()两个方法完全相同,前者的写法更简单,功能是在groupby()返回的对象中,对不同的列应用不同的计算统计方法
.agg()的写法有很多,比较推荐的写法是将列标签与对应的统计运算方法放入一个字典中:【data.groupby(‘列标签’).agg({‘列标签2′:’统计函数’,’列标签3′:’统计函数’…})】注意列标签与统计函数都要放入引号中
示例:
import pandas as pd
data = {
'Company': ['Google', 'Google', 'Microsoft', 'Microsoft', 'Facebook', 'Facebook'],
'Person': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'Sales': [200, 120, 340, 124, 243, 350]
}
df = pd.DataFrame(data)
print(df)
'''
Company Person Sales
0 Google Sam 200
1 Google Charlie 120
2 Microsoft Amy 340
3 Microsoft Vanessa 124
4 Facebook Carl 243
5 Facebook Sarah 350'''
print('---------')
grouped=df.groupby('Company').agg({'Person':'sum','Sales':'max'})
print(grouped)
'''
Person Sales
Company
Facebook CarlSarah 350
Google SamCharlie 200
Microsoft AmyVanessa 340'''.filter()
用途是在选择保留groupby对象中符合指定条件的分组,一般可以简单写成【groupby对象.filter(函数名)】
groupby对象的filter方法用于过滤数据,基于组内的计算结果来决定是否保留整个组的数据。
每一次将一组统计结果(一行数据)交给指定的函数,如果返回True则显示,反之则忽略,
该方法接受一个函数作为参数,该函数返回一个布尔值,filter方法会对每一个分组应用这个函数,然后保留返回True的哪些分组。
函数的输入是每个组的数据(作为一个数据框),并且必须返回一个布尔值以指示是否保留该组。
语法:【grouped.filter(func, dropna=True, *args, **kwargs)】
以下示例中,假设有一个DataFrame包含产品与产品销售额,现在要过滤掉总销售额小于50的产品:
import pandas as pd
df = pd.DataFrame({
'Product': ['A', 'A', 'B', 'B', 'C', 'C'],
'Sales': [20, 30, 15, 15, 60, 70]
})
#得到一个groupby对象
grouped = df.groupby('Product')
#将对象放入函数,对对象的Sales列应用求和的统计方法,如果大于50返回True
def filter_func(x):
return x['Sales'].sum()>50
filtered_df=grouped.filter(filter_func)
print(filtered_df)其他示例代码:【data.groupby(‘列标签’).filter(lambda g:g[‘总价’].mean()>1000)】
这一行代码的功能是将DataFrame对象根据特定列标签进行分组统计,然后对分组统计对象,仅保留总价这一列的平均值大于1000的分组
13.多层分组与透视表
groupby()方法可以根据多列进行分组,只需要将多个列标签作为一个列表参数放入groupby()中
注意如果是字符串的分组,应用一些统计计算方法可能会出错,所以有时得提前过滤掉字符串分组
在以下示例代码中,假设我们有一个销售数据的DataFrame,其中包括年份、季度、产品类型和销售额,然后我们根据年份和季度对这些销售数据进行分组
import pandas as pd
# 创建示例数据
data = {
'Year': [2020, 2020, 2020, 2020, 2021, 2021, 2021, 2021],
'Quarter': ['Q1', 'Q2', 'Q3', 'Q4', 'Q1', 'Q2', 'Q3', 'Q4'],
'Product': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'],
'Sales': [200, 220, 250, 275, 210, 215, 260, 300]
}
'''
Year Quarter Product Sales
0 2020 Q1 A 200
1 2020 Q2 A 220
2 2020 Q3 B 250
3 2020 Q4 B 275
4 2021 Q1 A 210
5 2021 Q2 A 215
6 2021 Q3 B 260
7 2021 Q4 B 300'''
df = pd.DataFrame(data)
print(df)
#根据年份与季度进行分组
grouped=df.groupby(['Year','Quarter'])
#求每个分组的 平均销售额
#有些字符串的分组,应用求平均值的方法会报错,所以只取Sales这一列,然后再求mean()
mean_sales=grouped['Sales'].mean()
print(mean_sales)
'''
Year Quarter
2020 Q1 200.0
Q2 220.0
Q3 250.0
Q4 275.0
2021 Q1 210.0
Q2 215.0
Q3 260.0
Q4 300.0
Name: Sales, dtype: float64
'''unstack()让数据表更易读
使用了多重分组后,因为不同的分组之间拥有重名的分组,可以使用unstack()方法修改数据表的显示效果,将不同分组之前重名的分组,作为列标签(需要自己指定作为列标签的那个分组)
以下是unstack()之前与之后的对比
import pandas as pd
# 创建示例数据
data = {
'Year': [2020, 2020, 2020, 2020, 2021, 2021, 2021, 2021],
'Quarter': ['Q1', 'Q2', 'Q3', 'Q4', 'Q1', 'Q2', 'Q3', 'Q4'],
'Product': ['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'],
'Sales': [200, 220, 250, 275, 210, 215, 260, 300]
}
'''
Year Quarter Product Sales
0 2020 Q1 A 200
1 2020 Q2 A 220
2 2020 Q3 B 250
3 2020 Q4 B 275
4 2021 Q1 A 210
5 2021 Q2 A 215
6 2021 Q3 B 260
7 2021 Q4 B 300'''
df = pd.DataFrame(data)
print(df)
#根据年份与季度进行分组
grouped=df.groupby(['Year','Quarter'])
#求每个分组的 平均销售额
mean_sales=grouped['Sales'].mean()
print(mean_sales)
'''
Year Quarter
2020 Q1 200.0
Q2 220.0
Q3 250.0
Q4 275.0
2021 Q1 210.0
Q2 215.0
Q3 260.0
Q4 300.0
Name: Sales, dtype: float64
'''
print('---')
unstacked=mean_sales.unstack('Quarter')
print(unstacked)
'''
Quarter Q1 Q2 Q3 Q4
Year
2020 200.0 220.0 250.0 275.0
2021 210.0 215.0 260.0 300.0'''# 原始的grouped DataFrame(分组后并计算了'Sales'平均值)
'''
Product Quarter
A Q1 200
Q2 220
Q3 250
B Q1 300
Q2 310
Q3 320
'''
###使用unstack()方法后,如果你用print()函数来输出,展示效果大致如下:
'''
Quarter Q1 Q2 Q3
Product
A 200 220 250
B 300 310 320
'''
'''
这里,行标签(即索引)是'Product'(A, B),列标签是'Quarter'(Q1, Q2, Q3)。数据格子里的值就是对应的'Sales'的平均值。
这样的展示方式使得你能更方便地查看每个产品在不同季度的销售表现。
'''pivot_table()
pivot_table()可以将原始的DataFrame进行变换,以获取不同维度、层次的汇总数据,其功能与Excel中的数据透视表非常类似
关键的3个要素是:
我们希望在表格中展现什么数值(示例中展示的是销售额)
指定行标题(指定index参数)
指定列标题(指定columns参数)
主要参数如下:
values:你想要汇总哪一列的数据
index:指定行标签
columns:指定列标签
aggfunc:指定汇总函数(如sum/mean/count等)(默认计算平均值)
fill_value:用与填充缺失值
margins:添加所有行/列小计和总和
dropna:是否删除含缺失值的列
import pandas as pd
df = pd.DataFrame({
'Date': ['2021-01-01', '2021-01-01', '2021-01-02', '2021-01-02'],
'Product': ['A', 'B', 'A', 'A'],
'Sales': [100, 150, 200, 50]
})
print(df)
'''
Date Product Sales
0 2021-01-01 A 100
1 2021-01-01 B 150
2 2021-01-02 A 200
3 2021-01-02 A 50'''
print('---')
#你可以创建一个数据透视表,以查看每个产品在不同日期的销售总额
pivot_df=pd.pivot_table(df,values='Sales',index='Date',columns='Product',aggfunc='sum',fill_value=0)
print(pivot_df)
'''
Product A B
Date
2021-01-01 100 150
2021-01-02 250 0'''pivot_table()也允许我们使用多层索引,比如可以为index参数传入一个列表(列表内是多个列标签)
14.文本字符串处理
筛选出DataFrame中某一列为特定文本的行,可以使用【df[df[‘列标签’]==’文本’]】
比如【df=df[df[‘城市’] ==’杭州’]】可以筛选出城市列下所有内容为’杭州’的列
DataFrame的字符串单元格也可以使用切片操作,只需要加上【.str】跑一趟红就会将单元格当成字符串来处理
【df=df[df[‘城市’].str[:1]==’杭’]】 #使用字符串切片功能切除第一个字符,判断它是不是等于’杭’,True则保留
可以使用startwith()方法,筛选出特定列下以某个字符串开头的行
【df=df[df[‘城市’].str.startswith(‘杭’)]】 #筛选出所哟 城市列 下以’杭’开头的单元格的行
| split() | 拆分字符串 |
| replace() | 替换子串 |
| strip() | 去掉首位空白字符 |
| rstrip() | 去除右侧空白租出 |
| lstrip() | 去除左侧空白字符 |
| upper() | 全部转换成大写 |
| lower() | 全部转换成小写 |
| len() | 字符串的长度 |
| contains() | 是否包含指定内容 |
| startswith() | 是否以指定文字开头 |
| isalnum() | 是否全为数字和字母 |
| isalpha() | 是否全为字母 |
| isdigit() | 是否全为数字 |
| islower() | 是否全部小写 |
| isupper() | 是否全部大写 |
| match() | 是否符合指定正则式 |
| findall() | 找出全部匹配结果 |
| extract() | 匹配并提取捕获组 |
通过.str.isalnum()来筛选出只有字母或数字的行的示例
import pandas as pd
# 创建一个示例DataFrame
data = {'列标签': ['abc', '123', 'abc123', 'abc!', '', None, '123!']}
df = pd.DataFrame(data)
# 打印原始DataFrame
print("原始DataFrame:")
print(df)
# 使用str.isalnum()方法筛选出'列标签'列中只包含字母和数字的所有行
filtered_df = df[df['列标签'].str.isalnum() == True]
# 打印筛选后的DataFrame
print("筛选后的DataFrame:")
print(filtered_df)
'''
原始DataFrame:
列标签
0 abc
1 123
2 abc123
3 abc!
4
5 None
6 123!
筛选后的DataFrame:
列标签
0 abc
1 123
2 abc123'''通过.str.lower()将某一列全部转换成小写,该方法会得到一个新的Series
import pandas as pd
# 创建一个示例DataFrame
data = {'列标签': ['ABC', 'aBc', 'AbC', None]}
df = pd.DataFrame(data)
# 打印原始DataFrame
print("原始DataFrame:")
print(df)
# 使用str.lower()将'列标签'列中的所有字符串转为小写
df['列标签'] = df['列标签'].str.lower()
# 打印转换为小写后的DataFrame
print("转换为小写后的DataFrame:")
print(df)
'''\原始DataFrame:
列标签
0 ABC
1 aBc
2 AbC
3 None
转换为小写后的DataFrame:
列标签
0 abc
1 abc
2 abc
3 None'''此处为语雀视频卡片,点击链接查看:[4.15]–15. 文本字符串处理(可试看).mp4
pandas的字符串替换功能也可以调用正则表达式
【df[‘新列’]=df[‘列标签’].str.replace(r'(捕获组)…正则表达式…’),r’\1′,regex=True】意思是将符合该正则表达式的单元格替换成正则表达式中的第一个捕获组,注意要加上参数【regex=True】
15.日期时间处理
pandas提供了将日期格式的字符串转换成日期格式的方法,pandas的【to_datetime】可以将指定的参数转换成时间类型,比如【pd.to_datetime(20230729)】可以得到【1970-01-01 00:00:00.020230729】(timestamp对象/时间戳类型对象)
常用的时间格式写法的字符串,pandas都可以进行智能识别,并且自动决定采用什么精度的时间
需要注意的是,要求的时间精度越高,时间戳对象所能表示的时间范围就越小,比如,如果要求精确到秒,那么一个datetime64类型的对象(64位二进制类型数据)可以表示的日期范围从公元前29亿年到公元后29亿年,如果把精确度提高到纳秒级别,一个datetime64类型的对象,就只能表示从公元1678年到公元2262年之间的时间点
pd.to_datetime()可以将DataFrame中的一整列转换成日期对象【pd.to_datetime(df[‘列标签’])】将返回一个Series对象,内容是DataFrame的一列数据
直接将DataFrame中某一列转换成日期格式,写法可以是【df[‘列标签’]=pd.to_datetime(df[‘列标签’])】
import pandas as pd
df=pd.read_excel('data.xlsx')
print(pd.to_datetime(df['日期']))
'''
0 2023-01-01
1 2023-01-02
2 2023-01-03
3 2023-01-04
4 2023-01-05
...
360 2023-12-27
361 2023-12-28
362 2023-12-29
363 2023-12-30
364 2023-12-31
Name: 日期, Length: 365, dtype: datetime64[ns]''' #最后的[ns]表示精度到了纳秒级别同一列中的两个日期格式的单元格可以进行相减
比如【print(df.loc[1,’日期’]-df.loc[0,’日期’]) #返回1 days 00:00:00】
两个日期相减会返回一个Timedelta对象,代表两个时间点的差额
将时间列设为index并重新排序
可以将时间列设为index:【df.index=df[‘日期’]】,需要记住的是,还要对日期索引进行排序,否则许多操作可能会出错,排序的方法是【df=df.sort_index()】
时间类型index的查询
通过loc方法,得到某一行的数据【df.loc[‘1998-02-10 00:23:23’]】,这里的日期格式写法可以自定义,pandas可以做到智能识别,比如把-号换成/号也能成功
如果上面的代码中的取值范围,只精确到日期也就是某一天,pandas也能将所有这一天(可能是不同时间点)的行给取出来【df.loc[‘1998/02/01’]】
时间类型的索引允许我们按照时间段进行查询
如果想要按照某一天的小时查询数据,可以写成日期空格加小时,比如【df.loc[‘1996/02/01 2’]】可以得到1996年2月1日这一天df中所有02时的数据
根据特定的时间段查询数据,可以为两个时间字符串之间加上:号放入df.loc[]参数中
【df.loc[‘1990/01/01 23:59:21′:’1999/12/31 23:59:20’]】
使用loc[]进行切片是,参数的开头和结尾都会被放入返回的内容中
时间切片的参数可以插入df中不存在的时间
时间列属性
时间列.dt.方法,目前只针对列,无法对index使用
df[‘时间列’].dt.day 可以返回一组Series,Series内包含每个单元格的数值对应所处月的那一天(1到31),也就是日期中的“日”。
将day替换成,month或dayofweek同理,注意daofweek会返回星期几,0代表星期1,6代表星期日
其他的参数还有:
year: 返回年份。
quarter: 返回季度(1到4)。
dayofyear: 返回一年中的第几天(1到366)。
week: 返回一年中的第几周。
weekday: 与 dayofweek 类似,返回星期几的信息(0代表星期一,6代表星期日)。
weekofyear: 与 week 类似,返回一年中的第几周。
is_month_start: 返回一个布尔值,表示该日期是否是月初。
is_month_end: 返回一个布尔值,表示该日期是否是月末。
is_quarter_start: 返回一个布尔值,表示该日期是否是季度开始。
is_quarter_end: 返回一个布尔值,表示该日期是否是季度结束。
is_year_start: 返回一个布尔值,表示该日期是否是年初。
is_year_end: 返回一个布尔值,表示该日期是否是年末。
days_in_month: 返回该月有多少天。
hour: 返回小时。
minute: 返回分钟。
second: 返回秒。
microsecond: 返回微秒。
nanosecond: 返回纳秒。再之后,还可以使用groupby()方法,比如一星期7天各自的统计数据
index无法使用上面的方法查看属性,但可以通过df.index.day/month/year/dayofweek/is_month_end等关键词得到类似的数据
返回的是一个NUmpy数组类型的对象
如果想将DataFrame的index的显示格式改为星期几/日,
如果想针对时间索引进行一个日期的提取,还可以使用strftime(时间文本格式化方法),具体来说,先通过map函数,将时间index中的每一个数值交给一个函数,然后在这个函数里,让这个日期时间对象运行它的strftime方法,并且按照我们指定格式的字符串,去算出一个指定的时间字符串,然后,再把这个时间字符串作为返回值
df.index.map(lambda d:d.strftime(‘%d’)) #返回的数据类型是index,因此可以赋值给原来的index
这行代码使用 map 函数和一个 lambda 表达式来转换 DataFrame 的索引。具体地,它将索引中的每个日期时间对象(假设索引是 DatetimeIndex 类型)转换为该日期的“日”部分(day component),并以字符串形式返回。
这里的 lambda 函数 lambda d: d.strftime(‘%d’) 接受一个日期时间对象 d,然后使用 strftime 方法以 %d 的格式(两位数的日)返回该日期的“日”部分。
还可以直接将index复制为一列,再按.dt方法进行转换,然后重新将列赋值给index
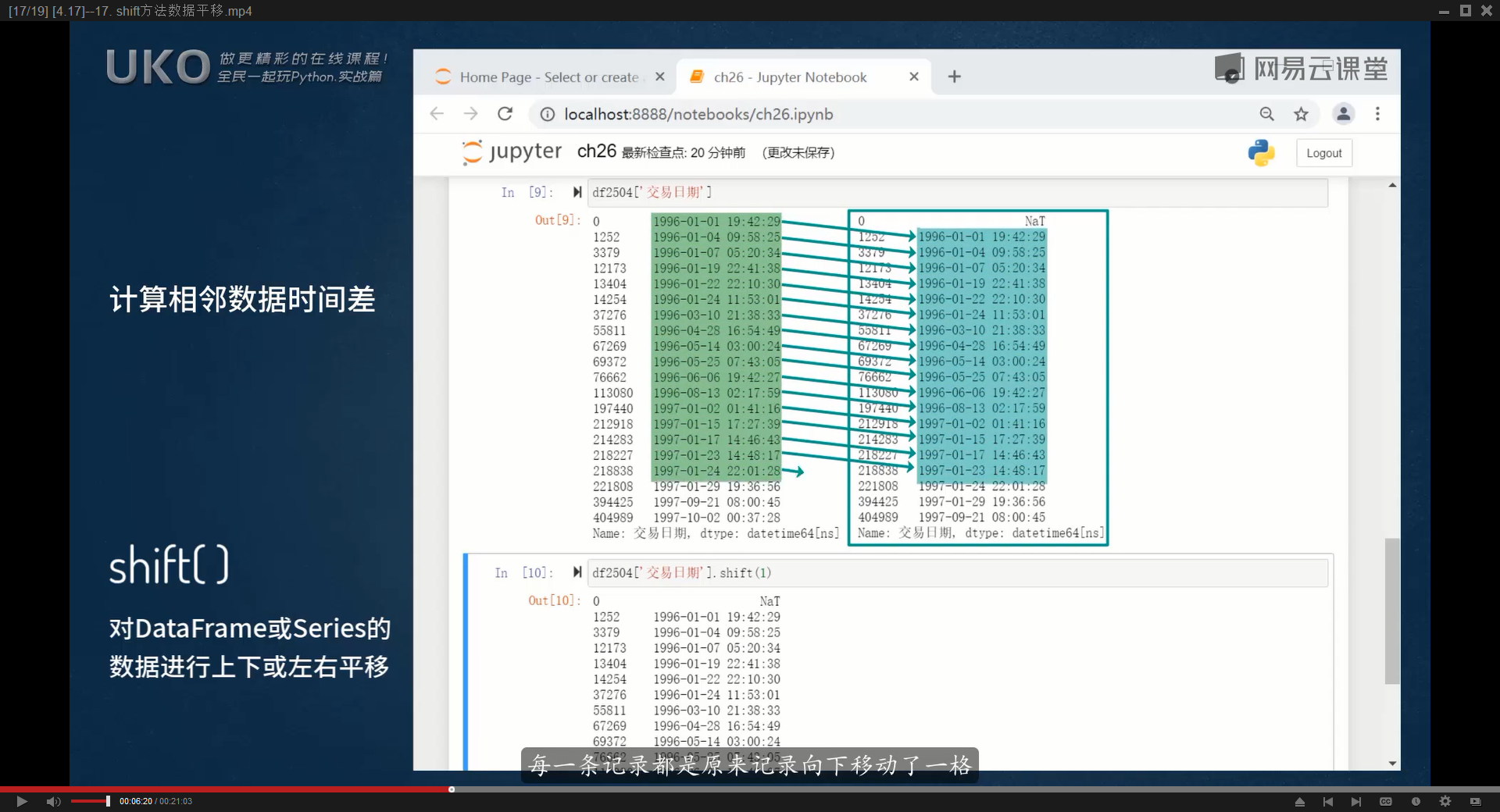
16.shift方法数据平移
计算两个列标签下各自的同一个关键字的时间差,比如‘账户编号’列下同一个账户以及‘交易类型’列下为取款类型,计算同一个账户每次取款的时间差
首先需要筛选出df中同一个账户的同一个交易类型:【df=df[(df[‘账户编号’]==100001)&(df[‘交易类型’]==’取款’)]】
然后在df中新建一列,为上一次的取款日期,可以通过shift方法得到【df[‘上次取款日期’]=df[‘取款’]。shift(1)】
最后新建一列【‘间隔时间’】,数值等于本次取款日期与上次取款日期的相减【df[‘间隔时间’]=df[‘取款’]-dff[‘上次取款日期’]】
两个日期之间相减,得到的数据的类型为TimeDelta时间差类型
TimeDelta类型的数据可以与一个日期做加法,比如一个日期加上6天,就能得到一个6天后的日期
如果想要更改TimeDelta列的显示方式,比如改成按天/小时/分钟显示,可以使用astype()方法
import pandas as pd
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 将'日期'列转换为datetime类型
df['日期'] = pd.to_datetime(df['日期'])
# 将'日期'列设置为索引
df.index = df['日期']
# 打印原始数据帧
print(df)
print('---')
# 筛选出城市为杭州的数据
df = df[df['城市'] == '杭州']
# 再次确保'日期'列是datetime类型(这一步其实是多余的,因为之前已经转换过了)
df['日期'] = pd.to_datetime(df['日期'])
# 创建一个新列'上个日期',其中包含上一行的'日期'值
df['上个日期'] = df['日期'].shift(1)
# 创建一个新列'间隔',其中包含当前日期与'上个日期'之间的时间差
df['间隔'] = df['日期'] - df['上个日期']
# 将'间隔'列转换为以秒为单位的时间差(timedelta64[s])类型,
# 然后除以3600(每小时的秒数)以将时间差转换为小时。
# 最后,将结果存储在新的'间隔(小时)'列中。
df['间隔(小时)'] = df['间隔'].astype('timedelta64[s]')/3600
print(df)TimeDelta常用单位:
timedelta64[Y]:年
timedelta64[M]:月
timedelta64[D]:日
timedelta64[W]:周
timedelta64[h]:时
timedelta64[m]:分
timedelta64[s]:秒
timedelta64[ms]:毫秒
timedelta64[ns]:纳秒
还可以通过TimeDelta对象的TotalSeconds()方法来获取总秒数,然后转换成小时可以除以3600,
import pandas as pd
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 将'日期'列转换为datetime类型
df['日期'] = pd.to_datetime(df['日期'])
# 将'日期'列设置为索引
df.index = df['日期']
# 打印原始数据帧
print(df)
print('---')
# 筛选出城市为杭州的数据
df = df[df['城市'] == '杭州']
# 再次确保'日期'列是datetime类型(这一步其实是多余的,因为之前已经转换过了)
df['日期'] = pd.to_datetime(df['日期'])
# 创建一个新列'上个日期',其中包含上一行的'日期'值
df['上个日期'] = df['日期'].shift(1)
# 创建一个新列'间隔',其中包含当前日期与'上个日期'之间的时间差
df['间隔'] = df['日期'] - df['上个日期']
# 将时间差转换为小时
df['间隔(小时)'] = df['间隔'].dt.total_seconds() / 3600
# 打印结果
print(df)shift()可以对DataFrame或Series数据进行上下或左右平移,比如【df[‘列标签’].shift(1)】就是把指定的列标签的数据下移一格,而第一个单元格会被NaN或NAT(缺失的时间值)填充
默认往下平移,网上平移可以写成负值
【fill_value】参数可以指定用什么数值来填充缺失的位置,比如【fill_value=pd.Timestamp(‘1990-1-1’)】
【axis=1】参数可以设置左右方向的平移
【frequent】参数可以进行时间计算
timedelta类型数据还可以用来做时间计算
日期时间不能直接用来与数字相计算,但可以与timedelta类型数据相加相减
创建timedelta类型数据,需要指定数字与计量单位(天/月/星期…)
pandas提供了多种创建timedelta的写法,最简单的写法是【pd.Timedelta(数字,’时间单位’)】,
比如【pd.Timedelta(10,’D’)】,甚至可以精简成【pd.Timedelta(’10D’)】或者【pd.Timedelta(’10D10h’)】
timedelta中时间单位的关键字有:W(周)D(日)h(小时)T或m(分)S(秒)L(毫秒)U(微秒)N或ns(纳秒)
通过字符串创建:
pd.Timedelta(‘1 days’)
pd.Timedelta(‘1 days 00:00:01’)
import pandas as pd
# 创建一个表示1天,2小时,3分钟和4秒的时间差
delta = pd.Timedelta('1 days 2 hours 3 minutes 4 seconds')
print(delta) #1 days 02:03:04通过关键字指定各个时间单位:
pd.Timedelta(days=1, seconds=1, microseconds=1, milliseconds=1, minutes=1, hours=1, weeks=1)
通过两个日期对象相减创建:
time1 = pd.Timestamp(‘2022-01-01 01:00:00’)
time2 = pd.Timestamp(‘2022-01-02 01:00:00’)
delta = time2 – time1
还可以使用 pd.to_timedelta 函数:
单个字符串或数值:
pd.to_timedelta(‘1 days’)
pd.to_timedelta(86400, unit=’s’) # 86400秒等于1天
字符串或数值的列表:
pd.to_timedelta([‘1 days’, ‘2 days’])
pd.to_timedelta([86400, 172800], unit=’s’) # 1天和2天
与单位的组合:
pd.to_timedelta(1, unit=’D’) # 1天
如果DataFrame的index就是日期格式,还可以使用shift的方法计算时间
比如【df=df.shift(10,freq=’D’)】就是给每个index加上10天,该方法只能在索引列上使用
17.数据类型转换与缺失值处理
通过正则表达式实现文本提取与替换
如果DataFrame中的一列,本该是数字类型,但却包含的杂七杂八的文本,可以新建一列再通过正则表达式提取数字
示例1:
import pandas as pd
import numpy as np # NumPy 用于生成缺失值
import re
# 创建一个字典,用于生成DataFrame
data = {
'ProductID': [101, 102, 103, 104, None],
'ProductName': ['Apple', 'Banana', None, 'Durian', 'Eggplant'],
'Price': ['RMB1.2', 0.8, '30元', 2.5, 1.8],
'InStock': [True, True, False, None, True]
}
# 使用字典来创建DataFrame
df = pd.DataFrame(data)
# 显示DataFrame
print(df)
print('---')
#定义一个正则表达式,从文本中提取整数与小数
def exctract_numbers(text):
if isinstance(text,(int,float)):
return text #如果是整数或小数,直接返回
#match=re.search(r'\b\d+(\.\d+)?\b',str(text)) #\b表示边界,\d+表示连续的数字,?号表示可能出现或不出现
#()号中的内容会座位group()方法的返回内容
#match=re.search(r'(\d+[\.\d]?\d?)',str(text)) #[]表示匹配里面的任意字符
match=re.search(r'(\d+\.?\d+?)',str(text)) #\b表示边界,\d+表示连续的数字,?号表示可能出现或不出现
return float(match.group()) if match else None #如果找到匹配返回数字,否则返回None
'''match 是一个 Match 对象,它包含了关于正则表达式匹配的多种信息,例如匹配位置、匹配字符串等。因此,你不能直接将 Match 对象转换为浮点数。你需要使用 .group() 方法来提取出实际匹配的字符串。
这里的 match.group() 返回与正则表达式匹配的那部分字符串。例如,如果正则表达式匹配了字符串 "abc" 中的 "b",则 match.group() 将返回 "b"。'''
#常见一个新列,其中包含提取的数字
df['提取数字']=df['Price'].apply(exctract_numbers)
print(df)另一个示例是,匹配出整个单元格的内容,将要保留的部分放入捕获组,在最后用捕获组里的内容替换掉整个单元格
最关键的一行代码是【df[‘Price’]=df[‘Price’].astype(str).str.replace(r'[^\d]*(\d+\.?\d+)[^\d]*’,r’\1′,regex=True)】
【.astype(str)】的作用是将这一列单元格转换为字符串形式,否则数值形式的单元格无法使用后面的.str()方法,replace后会变成NaN
【[^\d]*(\d+\.?\d+)[^\d]*】这个正则表达式中,【[^\d]】表示非数字开头的文本,*号表示可以出现0次货人一次,【(\d+\.?\d+)】表示将整数或小数放入捕获组
参数【r’\1’】表示使用第一个捕获组的内容(用于替换前一个参数的内容)
regex=True必须要加上,否则可能报错
import pandas as pd
import numpy as np # NumPy 用于生成缺失值
import re
# 创建一个字典,用于生成DataFrame
data = {
'ProductID': [101, 102, 103, 104, None],
'ProductName': ['Apple', 'Banana', None, 'Durian', 'Eggplant'],
'Price': ['RMB1.2', 0.8, '30元', 2.5, 1.8],
'InStock': [True, True, False, None, True]
}
# 使用字典来创建DataFrame
df = pd.DataFrame(data)
# 显示DataFrame
print(df)
print('---')
df['Price']=df['Price'].astype(str).str.replace(r'[^\d]*(\d+\.?\d+)[^\d]*',r'\1',regex=True)
print(df)astype()转换数据类型
当通过astype()将内容转换成bool逻辑值的时候,以下会被转换成False,其他几乎都会被转换成True
数字 0
浮点数 0.0
空字符串 “”
None
NaN(Not a Number)
空集合 []、{} 等
布尔值 False
需要注意的是,numpy.nan会被转换成True
在Python和NumPy中,numpy.nan(表示”非数字”)被认为是一个特殊的浮点数。当你尝试将其转换为布尔值时,它会被转换为 True 而不是 False。这是因为numpy.nan 是一个特殊的“占位符”,用于表示数值运算中不确定的或未定义的部分。
在逻辑判断中,numpy.nan 的行为与非零数字类似,因此当你将其转换为布尔值时,它会变为 True。
在对某一列进行数字运算之前,需要先转换为数字格式
DataFrame中主要数据类型有:object(各种对象)/str/int64(整数)/float64(浮点数)/bool(逻辑值)/datetime64(时间日期)/timedelta[ns]时间差
将某一列字符串转换为数字格式,只需要【df[‘列标签’]=df[‘列标签’].astype(‘int’)】,但是如果某些文本无法转换,运行过程中会报错
如果需要为某一列数字加上文本的后缀,也就是与其他字符串拼接,也可以先转换成字符串,然后与文本相加,最后赋值给原来的列
apply方法自定义函数
一些复杂的情况需要通过自定义函数apply()来处理,该函数的基本功能是将一个函数应用于整个DataFrame的列或行,或者将函数应用于Series中的每个元素
文本形式的列通过.astype()方法转换成数字形式,如果一些文本无法直接被转换成数字,会报错,这时候可以通过自定义函数的方式来转换
通过lambda来转换:
【df[‘数量’].apply(lambda s:float(s) if isinstance(s,int) else -1)】
上面这行代码的含义是将内容作为s变量传递给函数,转换成小数如果该变量的类型是整数类型,否则返回-1,isinstance()会返回True或False
实际可使用的代码:
import pandas as pd
df=pd.read_excel('data.xlsx',sheet_name=1)
df['英语']=df['英语'].astype('str')
#使用lambda函数和pd.toto_numeric()
df['英语']=df['英语'].apply(lambda x:pd.to_numeric(x,errors='coerce')).fillna(-1)
#pd.to_numeric(x,errors='coerce')尝试将x转换为数字,如果转换失败,它不会引发错误,而是返回一个NaN,然后,fillna()会将所有的NaN替换为-1
#errors='coerce'是pd.to_numeric()函数中的一个参数设置,用于指定如何处理转换错误,
#当设置为'coerce'时,如果转换失败,该函数不会引发错误,而是会返回一个特殊的浮点数NaN
print(df)通过def自定义函数来实现:
import pandas as pd
df=pd.read_excel('data.xlsx',sheet_name=1)
df['英语']=df['英语'].astype('str')
#定义一个自定义函数,尝试将文本转换为浮点数
def try_convert_to_float(x):
try:
return float(x)
except:
return -1
#使用apply函数应用自定以函数到指定列
df['英语']=df['英语'].apply(try_convert_to_float)
print(df)定位缺失值
定位缺失值可以使用isnull和notnull两个方法
【df.isnull()】可以返回一个与原来DataFrame相同形状的DataFrame,原DataFrame中缺失值的位置会被显示为True,非缺失值的位置会被显示未False
【df.notnull()】与上述的功能相反
也可以对DataFrame中某一列来寻找缺失值:【df[‘列标签’].isnull()】
筛选出DataFrame中某一列下为缺失值的行:【df[df[‘列标签].isnull]】
筛选出DataFrame中某一列下不为缺失值的行(将某一列下位缺失值的行全都抛弃):【df[df[‘列标签’].notnull()]】
.dropna()删除缺失值
.dropna()默认按行来删除(因为索引也是按行来索引),如果想要按列来删除,可以设置参数【axis=1】
DataFrame还有个方法是.dropna(),也就是删除空缺值的行或列,然后返回一个新的DataFrame
默认情况下,dropna()会删除缺失值所在的行,如果要删除缺失值所在的列,要加入参数【axis=1】
.dropna()的参数
how可以设置指定删除行或列的条件,值可以是’any’或’all’,如果是’any’会删除至少包含一个缺失值的行或列,而all会删除所有值都是缺失值的行或列(默认值是any,即只要出现一个缺失值,就将整行或列都删除)
thresh参数用来接受一个整数,用于指定行或列中 非缺失值 的最小数量,少于这个数量将会被删除(也就是说一行或一列中 非缺失值 的数量 少于该整数,这一行/列就会被删除)
subset参数用于指定一组列名,在这些列中查找缺失值(仅仅在指定的列中查找缺失值)
【inplace=True】可以直接对原DataFrame进行修改
.fillna()
.fillna()用于填充或替换DataFrame或Series中的缺失值NaN
最基础的用法是,用特定的内容替换掉df或Series中所有的NaN:【df.fillna(‘用来替换的内容’)】
可以使用一个字典作为参数,分别指定不同列的缺失值用什么来填充,该方法只会在特定的列标签下填充缺失值,没有指定的列标签里的缺失值仍会保留
字典里键的值甚至可以是比如【df[‘列标签’].mean()】数据类型,得到的会是有效值的平均值,再填充进每个缺失值的位置
# 使用字典来填充缺失值
df.fillna({‘列标签1’: 缺失值内容, ‘列标签2’: 缺失值内容})
forward(向前)/ backward(向后)
method参数可以指定用前面或后面最近的一个有效值来填充缺失值,method参数可以设置两个值,’ffill’和’bfill’,如果设置为【method=’ffill’】,那么缺失值就会用上面的最近一个有效值进行填充,如果如果是,’bfill’相反,如果前后都是NaN,那么缺失值仍然是NaN
如果想要按行来确定方向,让缺失值等于左边最近一个有效值或右边最近一个有效值,可以设置【axis=1】
limit参数用于配合method参数使用,当nan在一行或一列连续出现时(连续出现是指连在一起,中间无有效值),可以指定只有多少个nan可以获得最近一个有效值,如果设置为1,只有第一个nan能得到最近一个有效值
18.多层索引的使用
此处为语雀视频卡片,点击链接查看:[4.19]–19. 多层索引的使用.mp4
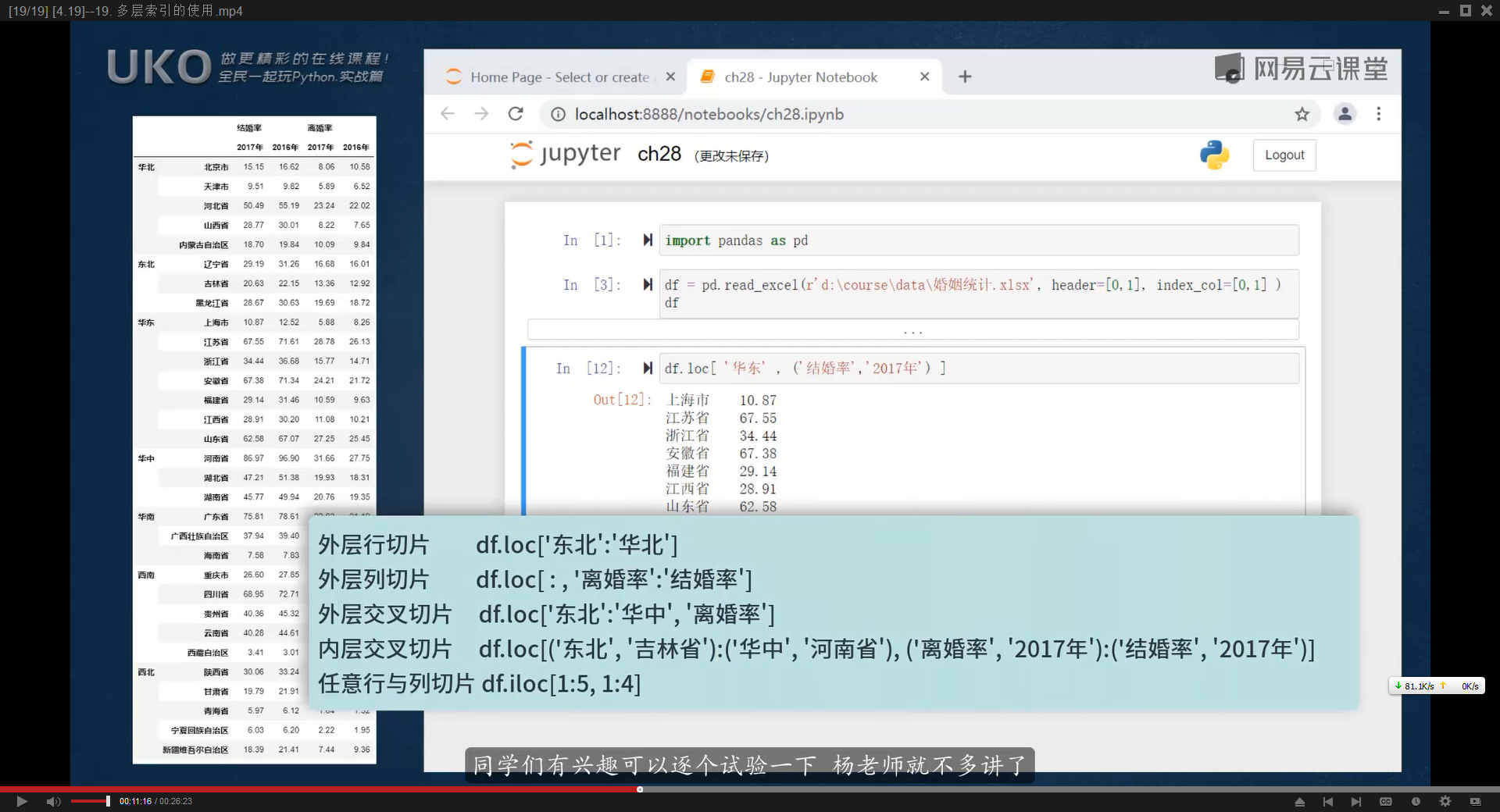
df.loc[‘行标签’,’列标签’]可以读取具体未指定值
如果一个DataFrame有多个index,定位时就需要将索引名称都写全,将索引名与列标签都放入元组,如果索引与列标签都只有一个,可以直接写一个字符串,比如【df.loc[(‘index1′,’index2’),(‘列标签1′,’列标签2’)]】,
外层行切片(多个index时根据左边第一个index进行切片):df.loc[‘index1′:’index2’]
外层列切片(多个列标签时,根据第一行列标签进行切片):df.loc[:,’列标签1′:’列标签2′] #注意参数中最左边的冒号,表示全部的index
外层交叉切片(多个index时,根据左边第一列index进行切片,然后只取特定一列数据):df.loc[‘index1′:’index2′,’列标签’]
内层交叉切片(多个index时,根据第一层与第二层index进行切片,然后读取指定的列):df.loc[(‘左index1′:’右index1’):(‘左index2′:’右index2’),(‘上列标签1′,’下列标签1’):(‘上列标签2′,’下列标签2’)]
任意行与列切片:df.loc[1:5,1:4]
需要注意的是,对于没有正确排序的列索引行索引,pandas会报错
swaplevel交换列标签层级
【df.swaplevel()】可以将df原来的左边第一列index变成第二列,原来在右边的第二层index变成左边第一列
设置参数【axis=1】,即可将第一行列标签与第二行列标签的位置互换
.swaplever()会返回一个df。
df.sum(level=0),在多重index下,根据左边第一列index,对每个列标签进行求和(根据左边第一列index进行分组,然后对组内么一组数据进行求和),level参数指定了第几个index。
同理,设置【axis=1】根据根据列标签进行汇总
stack与unstack 行列互换
.stack()可以将一个列标签转换为index,可以通过.stack()方法实现,默认将第二行列标签转换为最后一列index(默认转换最里面一行列标签),如果想将最上一行列标签转换成index,可以设置参数【level=0】(以此类推)
.usntack()方法可以将一个index转换为列标签,同样可以设置leve参数