1.Excel工具库的选择
Python有许多支持读写Excel的模块,xlwt与xlrd在曾经非常流行,但仅支持xls文件不支持xlsx与xlsm。
openpyxl模块,专门处理xlsx,不支持xls,数据、图表、格式全都能读写,功能非常强大,openpyxl只能读取数据表大米无法创建
pandas算是二维表格处理工具,读取Excel文件时,会调用其他模块(xlrd、xlwt、openpyxl)
上述模块都可以脱离office软件的Excel,来处理Excel文件
微软在开发Excel时,采用了面向对象的模式,因此不管是一个工作表还是一个单元格、公式甚至透视表,都可以被看做是程序中的一个对象,有它的类名、方法、属性,微软又为Windows操作系统开发了windows COM API,它的作用是可以让任何语言开发的程序,通过它直接引用office中的对象名,Python中有个win32com模块,就能通过它使用windows COM API
Python中又有许多库,针对win32com模块进行了包装,使代码更加简洁与易用,最经典的代表就是xlwings。
xlwings模块自定义了一些类,对应的就是Excel对象体系中我们日常工作最常用到的那几个类,但实际运行的时候,仍然会调用win32com模块,但xlwings模块的代码易用性更高,xlwings还提供了作为作为Excel插件运行的方式,可以像VBA一样,将它与Excel整合在一起
2.Excel对象与win32com
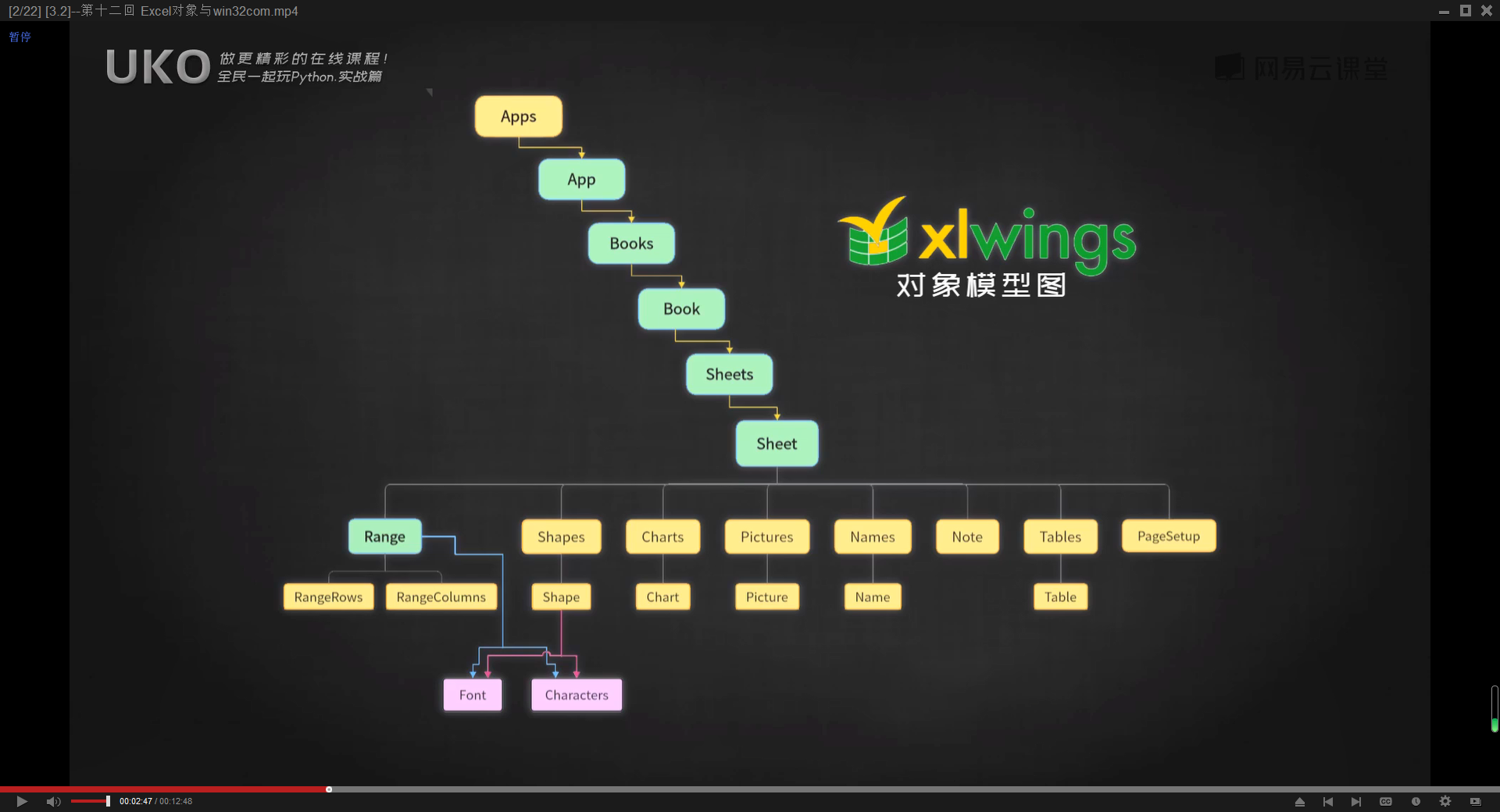
微软官方定义的类名(Python中类名与方法名都以首字母都大写)
Excel(Application)-工作簿个管理员(Workbooks)-工作簿(Workbook)-工作表管理员(Worksheets)-工作表(Worksheet)-单元格(Range)
import win32com.client as win32
#通过Excel.Application对象启动一个Excel实例,并显示界面
excel=win32.DispatchEx('Excel.Application')
excel.Visible=True
#调用Application.Workbooks对象的Open方法,打开工作簿
wb=excel.Workbooks.Open(r'D:\Python\学习\test.xlsx')
#调用Workbook对象的Worksheets属性,找到第一个工作表
ws=wb.Worksheets[1]
#调用WorkSheet对象的Range属性,修改单元格数值
ws.Range('B12').Value='Python办公自动化!!!'
#调用Workbook对象的Save方法,保存Excel文件
wb.Save()
# 关闭工作簿
#wb.Close()
#调用Application对象的Quit方法,关闭Excel窗口和实例
excel.Quit()3.xlwings对象概览与.api调用模式
微软官方定义的EXCEL对象

XLWINGS模块中的对象
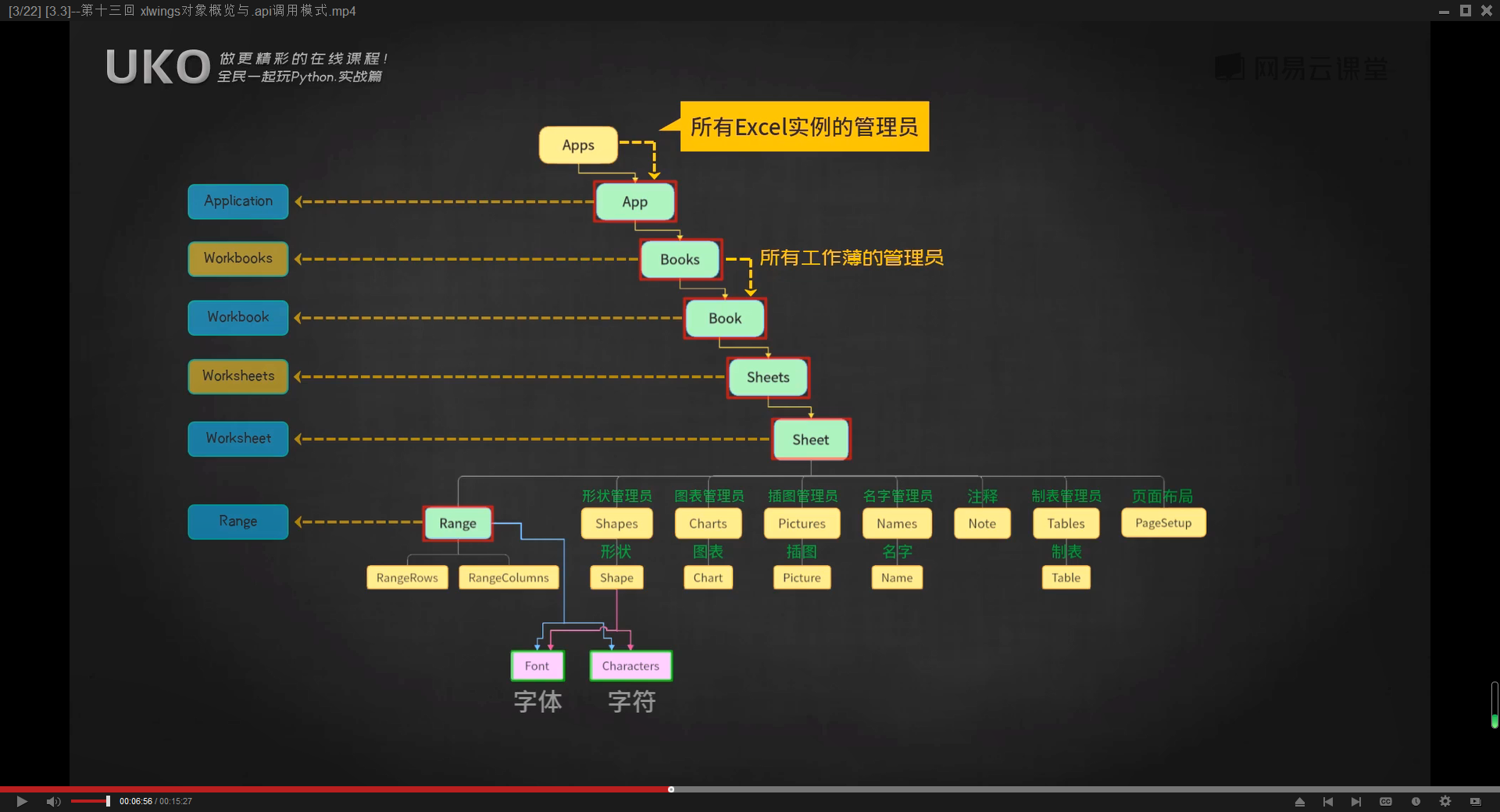
微软官方定义的EXCEL对象的数量远多于XLWINGS,但是XLWINGS模块基于WIN32模块,因此WIN32模块能调用的对象,xlwings都可以调用
比如,微软官方定义的Worksheet下面的PivotTables的PivotTable对象,用来处理数据透视表,xlwings中没有
win32com的调用方法是,Worksheets.PivotTables,
虽然xlwings中的sheet对象,没有PivotTables属性,但xlwings允许我们通过sheet.api.PivotTables这种方式直接调用win32com来找到这个数据表管理员对象,
我们可以在xlwings中,我们可以在任意一个对象,任意一个类后,写上【.api】再加上一个【.】,就可以使用Excel中的某一个对象真正的名字来调用它
又比如:
wb.sheets[0]是xlwings中的标准格式,返回的是xlwings自定义的sheet对象,而不是Excel原生的Worksheet对象,
wb.api.Worksheets是win32com调用Excel原生对象的方法,返回的是Excel中的Worksheet,而不是xlwings中的sheet对象
需要注意的是,【.api】这种方式,相当于使用win32com直接按照Excel的对象体系去调用,而在这个体系中,工作表工作簿透视表等等这些数组型的对象,他们的下标都是1开始算起的,所以,xlwings中的wb.sheets[0],写成api的形式,都要写成wb.api.Worksheets(1)
【.api】这种方式,不仅适用于没有被xlwings收录的对象,而且还适用于xlwings中没有收录的各种方法和属性,
比如Excel中Range对象的“清除格式”方法【Range(“A5”).ClearFormats()】,可以写成【range(“A5”).api.ClearFormats()】,还需要注意大小写,Excel原生的方法名首字母都是大写,xlwings中所有方法的首字母都小写
此外使用【.api】还需要注意的是,集合类对象的索引使用圆括号,集合类对象的索引,下标从1开始,
要注意分清xlwings对象和Excel原生对象,比如创建工作表对象时,已经用api的方式将工作表返回给一个变量,那调用跟这个变量下的属性时就不需要加上.api。
4.使用app与apps控制Excel运行实例
Apps是xlwings模块中的一个类,用于在Python程序中操作Excel程序,它代表着在你电脑上所有Excel实例的集合,简单来说,它就像是一个能够让你用Python代码访问和控制多个Excel窗口的工具(引用、激活(使其成为当前操作窗口、或关闭))。
每一个通过Apps访问的Excel实例都有一个唯一的进程标识符(PID),这允许你准确地指定和操作特定的Excel实例。
由于xlwings库内置了一个apps对象,你不需要显式地创建Apps实例,可以直接使用xlwings.apps来执行操作。
xlwings中,【.App()】是一个用于控制Excel应用的类,可以通过【.App()】来实例化一个Excel对象,
创建时最好加上参数【add_book=False】,否则会有一个多余的空白Excel窗口出现
visible参数可以控制Excel窗口是可见还是隐藏,如果设为True,在打开指定的工作簿之前,还是会有一个空白窗口,如果介意的话,可以先设置为False,打开工作簿后再设为True
import xlwings as xw
a1=xw.App(visible=False,add_book=False)
a1.books.open(r'D:\Python\学习\test.xlsx')
a1.visible=True创建完对象并且执行了想要的操作后,还需要使用【.quit()】方法进行退出操作
为了避免忘记quit操作,可以使用with结构
import xlwings as xw
#使用with结构创建管理a1对象,with结构结束时自动关闭a1
with xw.App(visible=False) as a1:
wb=a1.books.open(r'D:\Python\学习\test.xlsx')
#使用pprint模块中的pprint函数代替print,打印列表时更美观
from pprint import pprint
pprint(wb.sheets[0].range('a1:b2').value)xlwings模块中的Apps()是一个类,用来表示多个Excel程序的集合,每个Excel程序用App来表示,对应一个PID值,可以创建和管理多个工作簿,可以使用Apps()来查看、引用、激活或退出不同的App。
一台电脑可以运行多个Excel实例,而每个Excel实例打开了多个工作簿,因此可以通过1个Apps来管理多个Excel实例,xlwings中也只有一个apps对象,无需创建,直接引用即可【xlwings.apps】。
apps并不是列表,直接引用其中某个元素时,必须使用pid作为下标,比如apps[12345]而不是apps[0],如果想按照列表方式引用,可以先将apps转换为列表再按下标引用,比如写成list(apps)[0]。
print(list(xw.apps))可以看到类似这样的信息【[<App [excel] 14644>, <App [excel] 396>]】,是一个类似列表、元组这种类型的集合对象,上面的信息中可以看到当时共有2个成员,每个成员都是一个App对象,代表一个Excel实例,
其中类似于<App [excel] 396>]中的数字就是PID,也就是进程编号的意思,Windows会给当前所有运行起来的程序每一个进程都给一个编号作为唯一的标识,
我们可以通过for循环直接把Apps中的每一个App对象扫描出来
import xlwings as xw
#使用with结构创建管理a1对象,with结构结束时自动关闭a1
with xw.App(visible=False) as a1:
wb=a1.books.open(r'D:\Python\学习\test.xlsx')
#使用pprint模块中的pprint函数代替print,打印列表时更美观
from pprint import pprint
pprint(wb.sheets[0].range('a1:b2').value)
print(list(xw.apps))
print('---')
for app in xw.apps:
print(len(app.books)) #books有多长代表打开了几个工作簿
#得到每个实例分别打开了几个工作簿文件
#想要查看每一个Excel实例打开的Excel文件都叫什么
for wb in app.books:
print(wb.name)
'''
2
test.xlsx
chatGPT模板.xlsx
1
工作簿1'''有了Apps,Python程序就可以操作系统中所有打开的Excel文件和窗口(包含不是由Python启动的),
比如,在目前已经打开的Excel文件中写入内容
import xlwings as xw
for app in xw.apps: #遍历apps类
for wb in app.books: #遍历每一个工作簿
if wb.name=='test.xlsx': #如果名字为指定的工作簿
wb.sheets[0].range('A2').value='通过Python写入' #在指定单元格写入内容5.使用books与Book控制工作簿
在xlwings模块中,books和book分别代表不同的概念,它们用于在Python中与Excel工作簿进行交互。
Books是一个类,代表了一组工作簿的集合。在xlwings中,当你访问一个App(Excel实例)的books属性时,你实际上是在访问该Excel实例中所有打开的工作簿。
通过Books你可以执行如打开新工作簿、访问已打开的工作簿等操作,它是处理多个工作簿的高级接口。
例如【app.books】会给你该Excel应用程序中所有打开的工作簿。
案例:使用Books打开和列出所有工作簿
假设你在一个Excel程序中,想要查看所有打开的工作簿,或者打开一个新的工作簿,在这个例子中,app.books提供对当前所有打开的工作簿的访问,通过迭代这个集合,可以列出每个工作簿的名称,
【app.books.add()】则用于打开一个新的工作簿。
import xlwings as xw
# 连接到一个正在运行的Excel实例
app = xw.App()
# 列出所有打开的工作簿
for book in app.books:
print(book.name)
# 打开一个新的工作簿
new_book = app.books.add()
print(f"新工作簿的名称: {new_book.name}")
Book是一个类,代表单个工作簿,通过Book实例,你可以访问和修改一个特定的工作簿的内容,比如读写单元格、添加工作表等。
Book提供了更具体、针对单个工作簿的操作,例如【app.books[‘Example.xlsx’]】会返回一个名为Example.xlsx的特定工作簿。
案例:使用Book访问和修改单个工作簿
假设你要访问一个特定的工作簿,并在其中一个的工作表上执行操作,比如在特定的单元格中写入数据
在这个例子中,【app.books.open(‘Example.xlsx’)】用于打开一个名为’Example.xlsx’的工作簿文件,如果不存在,则创建一个新的,
接下来,代码将通过【book.sheets[‘Sheet1’]】访问该工作表中名为’Sheet1’的’工作表,并在A1单元格中写入数据
import xlwings as xw
# 连接到一个正在运行的Excel实例
app = xw.App()
# 打开或创建一个工作簿
book = app.books.open('Example.xlsx')
# 访问特定的工作表
sheet = book.sheets['Sheet1']
# 在特定单元格写入数据
sheet.range('A1').value = 'Hello, xlwings!'
# 保存并关闭工作簿
book.save()
book.close()
案例:Books和Book结合使用
假设你要遍历所有打开的工作簿,并在每个工作簿上的第一个工作表写入相同的数据
在这个例子中,通过【app.books】遍历所有打开的工作簿,对于每个工作簿book,代码访问其第一个工作表【book.sheets[0]】,并在A1单元格中写入数据,最后,再次遍历所有工作簿以保存更改。
import xlwings as xw
# 连接到一个正在运行的Excel实例
app = xw.App()
# 遍历所有打开的工作簿
for book in app.books:
# 在每个工作簿的第一个工作表的A1单元格写入数据
book.sheets[0].range('A1').value = 'Updated by xlwings'
# 保存所有更改
for book in app.books:
book.save()
import xlwings as xw
app=xw.App()
wb1=app.books.add() #新建工作簿
wb2=app.books.open(r'D:\Python\学习\test.xlsx') #打开工作簿
#一个Excel实例对一份Excel文件只能打开一次
#创建第二个Excel实例打开另一个实例一打开的文件,第二个实例打开后Excel文件状态为已读Excel文件在保存时,可以在保存窗口的【工具-常规】中设置打开权限密码与修改权限密码,如果想通过xlwings的open方法打开,可以设置参数password为打开权限密码,write_res_password为修改权限密码
wb=app.books.open(‘文件地址’,password=”,write_res_password=)
如果密码参数设置错误,会触发异常,因此利用这一个特性,可以写出一个暴力破解Excel密码的程序
import xlwings as xw
app=xw.App()
for i in range(1,1000): #假定密码是1到1000之间的数字
try:
app.books.open(r'D:\Python\学习\testp.xlsx',password=str(i))
print(f'破解成功,密码是{i}')
break
except: #如果触发异常,就会跳到excep的程序,然后继续下一个循环
print(f'正在尝试密码{i}')
'''
正在尝试密码231
正在尝试密码232
破解成功,密码是233
'''通过调用字典的方式来暴力破解的代码应该如下,但没能测试成功:
import xlwings as xw
app=xw.App()
with open(r'D:\Python\学习\password.txt','r') as f:
pwd_list=f.readlines()
print(pwd_list)
for i in pwd_list:
try:
app.books.open(r'D:\Python\学习\testp.xlsx',password=i)
print(f'破解成功,密码是{i}')
break
except:
print(f'正在测试密码{i}')查找并操作指定工作簿的第一个方法
import xlwings as xw
app=xw.App(add_book=False)
wb1=app.books.open(r'D:\Python\学习\test.xlsx') #在add_book=False的情况下,这是第一个打开的工作簿
wb2=app.books.open(r'D:\Python\学习\2.xlsx') #在add_book=False的情况下,这是第二个打开的工作簿
wb=app.books[1] #从0开始计数,所以[1]表示操作第二个工作簿
wb.sheets[0].range('C2').value='测试写入内容'但一般来说,没人会记得哪个工作簿是第几个打开的,所以通常采用工作簿名字来查找
import xlwings as xw
app=xw.App(add_book=False)
wb1=app.books.open(r'D:\Python\学习\test.xlsx')
wb2=app.books.open(r'D:\Python\学习\2.xlsx')
wb=app.books['2.xlsx'] #通过文件名来查找
wb.sheets[0].range('C2').value='测试写入指定内容'还有一种方法是,使用管括号来查找,从数字1开始计数
import xlwings as xw
app=xw.App(add_book=False)
wb1=app.books.open(r'D:\Python\学习\test.xlsx')
wb2=app.books.open(r'D:\Python\学习\2.xlsx')
wb=app.books(1) #操作第一个工作簿
wb.sheets[0].range('C2').value='测试写入指定内容3'以上方法都是通过books来新建工作簿,Book也能创建新的工作簿,区别是,前者会新建实例,后者可以在任务管理器中可以看到打开的工作簿都属于同一个实例
import xlwings as xw
wb1=xw.Book() #如果之前没有创建过实例,就会创建一个实例
wb2=xw.Book() #如果之前已经有实例,就会通过建好了的实例创建工作簿通过Book()来打开工作簿【wb1=xw.Book(r’D:\Python\学习\test.xlsx’) 】,效果与books.open相同,唯一的区别是不能打开两次同名文件
通过Book(‘文件名’)来选择已经打开的工作簿,注意还是圆括号
import xlwings as xw
wb1=xw.Book('2.xlsx')每一个打开的工作簿对象都有.app属性,工作簿对象.app代表的就是该工作簿所在的实例,【工作簿对象.app.quit()】会退出该实例下的所有工作簿
工作簿对象.name可以得到该工作簿的文件名(包括扩展名)
工作簿对象.fullname可以得到文件的路径地址
工作簿对象.sheet_names可以得到工作簿内所有工作表的名字
工作簿对象.activate()可以将该工作簿设为当前活动工作簿
工作簿对象.save()可以保存该工作簿、
工作簿对象.close()可以关闭该工作簿
wb.to_pdf (path=’文件路径’,include=[1,工作表名],show=True)
可以将该工作簿转换为PDFinclude是可选参数,可以使用下标数字(从1开始计数),也可以使用工作表名来决定保存哪几个工作表,show=True表示创建好PDF文件后将它自动显示在屏幕上
xlwings虽然没有提供将工作表转换成网页的方法,但是微软官方有提供,可以通过微软官方的api来调用
工作簿对象.api.WebPagePreview()
6.使用sheets与Sheet控制工作表
工作表管理员Sheets的方法非常简单,只有创建新的工作表和定位工作表
添加工作表
import xlwings as xw
app=list(xw.apps)[0] #获取所有打开的Excel应用,并把第一个(索引为0)Excel应用对象赋值给app。如果没有任何打开的Excel应用,这会引发一个错误
wb=app.books['test.xlsx'] #定位工作簿
ws1=wb.sheets.add() #新建工作表,并用变量名代表这张工作表
#上一行代码新建的工作表可能会出现在工作簿的最前面,如果希望排在最后一位,可以设置after参数指定排在哪个工作表之后,对应的参数是before
ws2=wb.sheets.add(after=ws1)
#如果想放在最后一位,可以通过工作表管理员来定位
ws3=wb.sheets.add(after=wb.sheets[-1]) #注意是wb.sheets,wb是之前设置的工作簿名,负一代表最后一张定位工作表
import xlwings as xw
app=list(xw.apps)[0] #获取所有打开的Excel应用,并把第一个(索引为0)Excel应用对象赋值给app。如果没有任何打开的Excel应用,这会引发一个错误
wb=app.books['test.xlsx'] #定位工作簿
#通过序号定位工作表
ws1=wb.sheets[0] #第一张工作表
ws1.range('b1').value='这是B1单元格的内容'
#通过工作表名来定位工作表(提倡)
ws10=wb.sheets['Sheet10']
ws10.range('b10').value='B10'
#模仿win32,使用圆括号,从1开始计数
ws3=wb.sheets(3)#从左往右第三张工作表
ws3.range('b2').value=2sheet方法的常用方法和属性
1.名称标识: name index
2.复制删除: copy delete
3.清空重置: clear clear_contents clear_formats
4.转换格式: to_pdf to_html
5.保护隐藏: visible Protect Unprotect
名称标识
# 导入xlwings库,并用别名xw来表示
import xlwings as xw
# 打开位于指定路径的Excel文件,将其作为一个工作簿对象赋值给变量wb
wb = xw.Book(r'D:\Python\学习\test.xlsx')
# 选择工作簿wb中的第二个工作表(Python中的索引从0开始,所以1代表第二个),并将其赋值给变量ws
ws = wb.sheets[1]
# 打印出工作表ws在工作簿中的索引位置
print(ws.index) #2
# 打印出工作表ws的名称
print(ws.name) #Sheet2列出指定目录(在这里是 ‘D:\Python\学习’)下所有Excel工作簿的文件名及其包含的所有工作表的索引和名称。
#获取一个文件夹中所有Excel文件中每个工作簿的文件名以及各自内部工作表的名字
import xlwings as xw
from pathlib import Path
doc_path=Path(r'D:\Python\学习')
#使用xlwings的App类创建一个新的Excel应用实例
with xw.App() as app:
#遍历指定路径下指定格式的文件
for f in doc_path.rglob('*.xls?'): #可选glob或rglob
#打印当前文件名
print(f'----------------工作簿文件:{f.name}-----------')
try:
#打开当前Excel文件
wb=app.books.open(f)
#遍历当前Excel文件内所有的工作表
for ws in wb.sheets:
#打印当前工作表的索引和名称
print(f'第{ws.index}张:{ws.name}')
#关闭当前工作表
ws.close()
except:
pass #如果在处理过程中触发异常,就忽略并继续处理下一个文件复制删除
Sheet.copy() #默认会将拷贝的工作表放在最后一个位置
可选参数:
before:将该工作表拷贝到哪张表之前
after:将该工作表拷贝到哪张工作表之后
name:新工作表名称
#根据某张工作表为模板,复制12个工作表,每个新复制的工作表以2023年中每个月的月份第一日的日期为名称,比如20230101
# 导入xlwings库,xlwings是一个Python库,用于操作Excel。这里,我们使用别名"xw"来代表xlwings库,以便在后续代码中方便调用
import xlwings as xw
# 使用xlwings的Book函数打开指定路径下的Excel文件。这里的路径是'D:\Python\学习\test.xlsx'。打开的文件被赋值给变量wb,代表一个"工作簿"对象
wb = xw.Book(r'D:\Python\学习\test.xlsx')
# 从工作簿wb中获取名为'20220210'的工作表,并将其赋值给变量ws_src。这里的'sheets'属性用于访问工作簿中的工作表,可以通过索引或名称来获取工作表
ws_src = wb.sheets['20220210']
# 使用for循环和range函数创建一个从1到12的整数序列,代表一年中的所有月份。对于每个月份,执行以下的代码块
for month in range(1, 13):
# 创建一个新的工作表名称。这个名称由年份'2023'、两位数的月份和日期'01'组成。例如,如果month是2,那么sheet_name就会是'20230201'
sheet_name = '2023' + '{0:02d}'.format(month) + '01'
# 使用工作表ws_src的copy方法创建一个新的工作表,这个新工作表是ws_src的复制,并且使用上一步创建的sheet_name作为新工作表的名称
ws_src.copy(name=sheet_name)关于上述代码中format用法的解释【sheet_name = ‘2023’ + ‘{0:02d}’.format(month) + ’01’】
format()方法可以在字符串中插入并且用于对字符串进行格式化,上面的代码用于将数字格式化成两位整数
{}是占位符,用于表示用来插入变量的位置
第一个0是format()方法的索引,因为format可以接收多个参数,如果只有一个参数则可以省略
:02d用于表示对插入的变量进行格式化,冒号后面的部分是格式说明符,其中2表示(最小)宽度,即输出结果占用的字符数,如果实际数值小于这个宽度,那么输出结果会在左边填充空格以达到这个宽度,大于这个宽度则按照原来的数值
0表示如果宽度大于实际值的字符数,那么使用0来填充
d表示参数是一个整数
根据以上解释,’0:02d’.format(month)会将month变量转化成2位数的字符串,如果month小于10,那么左边会填充一个0
删除工作簿中特定名字的工作表,以下代码用于删除指定工作簿中名字以2023开头的工作表
# 导入xlwings库,xlwings是一个Python库,用于操作Excel。这里,我们使用别名"xw"来代表xlwings库,以便在后续代码中方便调用
import xlwings as xw
wb=xw.Book(r'D:\Python\学习\test.xlsx')
for ws in wb.sheets:
if ws.name.startswith('2023'):
ws.delete()上述代码中,如果将ws.delete()改成ws.clear()就不会删除工作表,而是清空工作表的内容,包括边框线(工作表全白),而clear_contents()则可以做到只清空内容而保留原来的格式(包括边框线的样式,每个单元格的字体属性),对应的还有clear_formats(),只删除格式而保留每个单元格的内容
转换格式
to_pdf与to_html可以将Excel文件转换成指定格式
将工作簿内每张工作表转换成PDF
import xlwings as xw
wb=xw.Book(r'D:\Python\学习\test.xlsx')
for ws in wb.sheets:
ws.to_pdf(path=fr'D:\Python\学习\目标文件夹\{ws.name}.pdf')将上面代码中的to_pdf改成to_htm可以将工作表转换成html页面
保护隐藏
扫描某一个文件下的每一个xlsx文件,如果工作表名字带有“隐藏”,就将该工作表隐藏
如果想要全部去下隐藏,将下面代码中的ws.visible = False改成True即可
# 导入xlwings库,这是Python中用于处理Excel文件的库
import xlwings as xw
# 导入Path类,这是用于处理文件路径的类
from pathlib import Path
# 用xlwings的App类创建一个Excel应用实例,这个实例会在这个with语句块结束后自动关闭
with xw.App() as app:
# 使用Path类的glob方法,找到指定目录下所有以.xlsx结尾的文件,然后遍历这些文件
for f in list(Path(r'D:\Python\学习').glob('*.xlsx')):
# 尝试执行下面的代码,如果有错误就跳过
try:
# 使用Excel应用实例的books.open方法打开一个Excel文件
wb = app.books.open(f)
# 遍历这个工作簿中的所有工作表
for ws in wb.sheets:
# 如果工作表的名字中包含'隐藏'
if '隐藏' in ws.name:
# 那么就把这个工作表设为不可见
ws.visible = False
# 保存工作簿
wb.save()
# 关闭工作簿
wb.close()
# 如果上面的代码有错误
except:
# 就什么都不做,继续执行下一条指令
pass与上面代码类似,还可以保护指定的工作表,但xlwings没有提供这个功能,需要使用win32com
import xlwings as xw
from pathlib import Path
with xw.App() as app:
for f in list(Path(r'D:\Python\学习').glob('*.xlsx')):
try:
wb=app.books.open(f)
for ws in wb.sheets:
if '隐藏' in ws.name:
ws.api.Protect('233')#设置工作表保护与密码,取消工作表保护则是Unprotect
wb.save()
wb.close()
except:
pass上面的示例方法中,都使用了try except结构,避免在处理大量文件的程序运行中出现异常而中断
7.用Range表示单元格
用字符串读取指定区域
可以通过【工作表.range(‘单元格地址’)】来获取单元格内容,如果获取多个单元格地址,可以使用【起始单元格:结束单元格】来表示
如果多行多列单元格,那么会返回一个二维数组,一行单元格的内容作为一个小的list,最后将每行list放入一个大的list中
默认的print()方法会将二维列表中的所有列表在一行中显示,而pprint则可以将二维列表中的每一个;列表在打印的视乎单独占据一行显示,这样更方便查看(如果列表中的元素不多或子列表的长度不算长仍然可能会全部放在一行展示)
如果读取单行或单列单元格,会返回一维列表(pandas中读取一列好像会返回二维列表)
import xlwings as xw
wb=xw.Book('test.xlsx')
st=wb.sheets['测试隐藏']
print(st.range('j15').value)
print(st.range('j15:l16').value)
print('---')
from pprint import pprint
pprint((st.range('j15:l17').value))如果要读取多个单元格的内容,xlwings允许将起始单元格与结束单元格作为两个参数填入【pprint((st.range(‘j15′,’l17’).value))】
这个方法可以在两个参数都中填写单元格区域,那么会返回左上角单元格到右下角单元格之间整片区域,其中没有数值的单元格会返回None
用行列元组读取指定区域
range((行号,列号)) #读取单个单元格 (注意这里的行号和列好都是数字)
range((a,b),(,x,y)) #读取一个单元格区域,ab表示起始单元格的行列数值,xy表示结束单元格的行列数值
import xlwings as xw
# 打开Excel应用和特定工作簿
app = xw.App(visible=True)
wb = app.books.open('example.xlsx') # 假设Excel文件名为example.xlsx
sheet = wb.sheets['Sheet1'] # 假设我们操作的工作表名为Sheet1
# 读取单个单元格(比如第3行第2列)
cell_value = sheet.range((3, 2)).value # 这将读取位于第3行第2列的单元格的值
print("读取的单个单元格的值是:", cell_value)
# 读取单元格区域(比如从第1行第1列到第4行第3列)
range_value = sheet.range((1, 1), (4, 3)).value # 这将读取从第1行第1列到第4行第3列的单元格区域
print("读取的单元格区域的值是:", range_value)
# 关闭工作簿和Excel应用
wb.close()
app.quit()
print(工作表.range((15),(10)).value) #读取第15行第10列单元格的内容
#读取多行多列则是在元组中插入两个数,分别代表起始单元格的行列与结束单元格的行列
print(st.range((15,10),(17,12)).value)
默认方法都是逐行读取单元格,但也可以通过for循环读取
import xlwings as xw
wb=xw.Book('test.xlsx')
st=wb.sheets['测试隐藏']
for col in range(10,13): #10到13可以获取:10,11,12
print(st.range((15,col),(17,col)).value) #15为起始单元格所在的行,17位结束单元格所在的行使用range对象指定range
import xlwings as xw
wb=xw.Book('test.xlsx')
st=wb.sheets['测试隐藏']
r1=st.range('J15') #没有.value,.value表示单元格中的内容
print(r1)import xlwings as xw
wb=xw.Book('test.xlsx')
st=wb.sheets['测试隐藏']
r1=st.range('J15') #J15单元格对象
r2=st.range('l17') #L17单元格对象
r3=st.range(r1,r2) #一整块区域的单元格
print(r3.value)混合使用
前面三种方法可以混合起来使用
比如:
import xlwings as xw
wb=xw.Book('test.xlsx')
st=wb.sheets['测试隐藏']
print(st.range('J15',(15,12)).value) #获取从J15单元格到第15行12列单元格之间的内容,其中的range参数也能替换为一个单元格对象8.动态确认表格范围
此处为语雀视频卡片,点击链接查看:[3.8]–第十八回 动态确认表格范围.mp4
end()方法查找边界
在Excel中,选中一个单元格,按下CTRL+方向键,即可跳转到对应方向的连续单元格中的最后一个单元格,xlwings模块也能模拟这个方法,也就是range的end(),该方法会返回一个range对象,也就是对应方向的连续单元格中的最后一个单元格。
end()方法的用来表示上下左右的参数分别可以写【up】【down】【left】【right】
如果选中单元格已经是连续单元格中的最后一个,再使用end()方法,又会有两种情况,如果再往这个方向出发,还有单元格,虽然不连续,那么就会返回往这个方向出发后能找到的第一个有内容的单元格,否则会返回Excel所能支持的最后一行/列的单元格,比如第1048576行单元格(xls文件最大行号是65535),最大列好好像是XFD17
import xlwings as xw
wb=xw.Book('test.xlsx')
ws=wb.sheets['测试隐藏']
r1=ws.range('j15').end('down') #j15单元格往下的连续单元格中的最后一个单元格
print(r1.value)选中表内任意一个单元格,得到该表中最后一个单元格(最右下角)的单元格对象,可以用这种写法【r1=ws.range(‘j15’).end(‘right’).end(‘down’)】
expand方法
用于扩展当前的range对象,将范围扩展至上下左右所有连续的单元格(可以理解成选中一个单元格,然后得到单元格所属的整个表格的范围)
根据实测,expand()默认会返回 所选单元格 作为起始单元格,然后从起始单元格往下最后一格再往右最后一格单元格 的整个范围(而不是根据所选单元格,得到该单元格所处的表格的全部)
import xlwings as xw
from pprint import pprint
wb=xw.Book('data.xlsx')
sheet=wb.sheets['Sheet1']
#选择一个单元格,然后扩展
table_range=sheet.range('C2').expand().value
pprint(table_range)所以,end()方法返回的是一个单元格,而expand()方法是返回一片区域
expand()方法允许通过参数设置扩展的方向,分别是【down】【right】和【table】,不填参数的情况下默认是table,也就是向下然后向右(注意顺序)
如果是down,那就从起始单元格开始向下至连续的最后一个单元格 这一片区域(value返回的是一个一维列表,列表中包含这个区域内(这一列)每个单元格的内容)
参数如果是’right’则返回从起始单元格开始的一整行
import xlwings as xw
from pprint import pprint
wb=xw.Book('data.xlsx')
sheet=wb.sheets['Sheet1']
#选择一个单元格,然后扩展
table_range=sheet.range('C2').expand('down').value
pprint(table_range)Sheet对象的used_range属性
Sheet对象的used_range属性可以根据该工作表中有内容的单元格得到一个矩形的表格区域(先确定有内容够的单元格,然后根据这些单元格得到一个矩形区域,比如第一行为空,那么第一行就被忽略),它返回的是一个range对象
from pprint import pprint
import xlwings as xw
wb=xw.Book('test.xlsx')
ws=wb.sheets['测试隐藏']
r1=ws.used_range
print(r1)
pprint(r1.value)如果range对象包含多个单元格,那么它的结构就有点像列表,可以通过下标来得到它的第一个单元格,也就是一整片单元格区域的左上角起始单元格
from pprint import pprint
import xlwings as xw
wb=xw.Book('test.xlsx')
ws=wb.sheets['测试隐藏']
r1=ws.used_range
print(r1[0].value) #通过下标来选择其中的某一个单元格,如果是最后一个,下标可写成【-1】需要注意的是:只要某一个单元格曾经修改过格式,哪怕没有任何内容,Excel仍然会认为它是一个是用过的单元格,并且将其放入used_range中。
Range对象还有两个属性分别是row和column,分别可以返回所在行号和列号(相对于整个工作簿)
r1=ws.used_range
print(r1[0].row) #返回首个单元格所在的行号如果range对象包含多个单元格,那么row和column属性返回的是左上角第一个单元格的坐标
9.Range.options方法
Range对象的options()方法允许我们在原来的range对象的基础上,修改一些默认的选项,比如按行还是按列读取,读取成整数还是小数等,然后它会按我们指定的这些选项,给我们返回一个新的Range对象
将range对象的options方法中,transpose(转置)属性设为True,可以按列读取数据
from pprint import pprint
import xlwings as xw
wb=xw.Book('test.xlsx')
ws=wb.sheets['测试隐藏']
r1=ws.range('J15:L17')
pprint(r1.options(transpose=True).value)numbers参数可以设置int或float,参数不需要引号,比如【numbers=int】,就可以设置数字单元格读取为整数还是小数
empty参数可以设置,如果是空单元格返回什么内容,比如【empty=’内容’】
dates参数可以将日期格式的单元格,读取成日期格式,比如【dates=datetime.date】,但使用前需要【import datetime】
ndim控制数据返回的维度
在xlwings中使用ndim参数可以控制返回的数据的维度,默认情况下,xlwings根据Range对象的形状返回值,当读取单行或单列时,返回一维列表,当读取多行多列时,返回二维列表。
通过设置ndim参数,可以强制xlwings按指定的维度返回数据
单个单元格
不设置ndim参数,默认情况下,读取单个单元格:sheet.range(‘A1’).value将返回单个值,比如5
设置ndim=1,如sheet.range(‘A1’).options(ndim=1).value,将返回以为列表,比如[5]
设置ndim=2,即使是单个单元格也会返回二维列表,返回结果比如[[5]]
单行
不设置ndim,默认读取单行范围,如sheet.range(‘A1:C1’).value将返回一维列表,如[2,3,3]
设置ndim=2,将返回二维列表,如sheet.ranhe(‘A1:C1’).options(ndim=2).value会返回[[2,3,3]]
多行多列范围
在读取多行多列的情况下,设置ndim=1会报错,因为ndim不能用来降维
ndim参数可以设置Range对象的维度,默认情况下,如果Range对象为1行单元格,那么读取它的Value只会返回一个一维列表,列表中每个元素是这一行单元格中每一个单元格的值,
如果设置【ndim=2】,那么及时只有一行单元格,但它返回的却是二维列表,一个大的列表中包含许多个小列表,每个小列表中是这一行中每个单元格中的值,比如【[[2], [3], [3]]】
如果Range对象只是单个单元格,默认返回结果就不是列表,但是设置ndim参数可以让它返回一维列表或者二维列表
ndim的参数只能是1或2
需要注意的是,ndim参数只能用来升维,不能用来降维,如果Range对象是多行单元格,原本返回的是二维列表(每一行是一个子列表),但如果设置ndim=1则会报错
expand参数
expand参数与前文讲的expand方法基本一致,只不过这次变成了options方法中的一个参数,参数的值可以为【’table’】【‘right’】【’down’】
r1=ws.range('J15')
pprint(r1.options(expand='down').value)但严格来讲,这两个expand还是存在区别,options的expand参数支持动态跟中,原来的表格中新增了一行内容,它会自动识别并自动扩展范围,而expand()方法则是会保持第一次执行时的内容
将数据写入Excel工作表
要将数据写入Excel工作表,只要将Range对象等于要写入的就行,一维列表可以写入一行数据
如果想写入一列数据,那就用一个二维列表,子列表中包含这列数据中的值
多行多列则是用正常的二维列表就行
比如
from pprint import pprint
import xlwings as xw
wb=xw.Book('test.xlsx')
ws=wb.sheets['测试隐藏']
r1=ws.range('J15')
r1.value=1 #将数据写入相应的单元格
r1.value=[6,6,6] #写入一行数据
r1.value=[[6],[6],[6]] #写入一列数据写入单元格时,也能使用options方法,比如更加直观的写入一列数据:
r1=ws.range('J15')
r1.options(transpose=True).value=[2,3,3] #写入一列数据10.将数据读为DataFrame
Range对象的options方法还有一个参数是convert,可以将数据转换成字典格式甚至pandas的DataFrame。
要转换成字典,就设置成convert=dict,会将一行中每两个单元格设置成一对键值
需要注意的是,如果转换成字典,每一行应该只有两个单元格,第一个单元格被作为键,后一个单元格被作为值
import xlwings as xw
# 打开工作簿和工作表
wb = xw.Book('example.xlsx')
sheet = wb.sheets['Sheet1']
# 读取指定范围并转换为字典
data_range = sheet.range('A1:B3')
data_dict = data_range.options(convert=dict).value
# 输出转换后的字典
print(data_dict)
转换成pandas中的dataframe,可以在options()方法中设置参数【convert=pd.DataFrame】,但使用前需要【import pandas as pd】,
比如:【df=r.options(convert=pd.DataFrame,numbers=int).value】
如果某个单元格数值过长,可以使用【numbers=int】强制转换成整数,但这样也会把表格中的小数转换成整数
如果某些列想保留小数,可以在转换成DataFrame后,再将指定列转换成整数【df[‘列标签’]=df[‘列标签’].astype(int)】
或者转换成np.int64
astype()的可以使用的参数:
基础数据类型:
浮点数: float
整数: int
字符串: str
日期和时间:
日期时间: ‘datetime64[ns]’
布尔型:
布尔值: bool
分类数据:
分类数据: ‘category’
其他numpy数据类型:
32位整数: np.int32
64位整数: np.int64
32位浮点数: np.float32
64位浮点数: np.float64
复数: np.complex
在确保所有的列标签都可以转换成整数的情况下,如果想将DataFrame中的所有列标签都可以被转换成整数,可以使用【df.columns = df.columns.astype(np.int64)】
如果通过xlwings的options()方法将Range转换成DataFrame,还要两个参数分别是header和index,
header 参数
- header 参数确实可以是布尔值或数字。
- 当设置为 True,xlwings 将表格的第一行作为列标签(即 DataFrame 的列名)。
- 当设置为 False,列标签将由 pandas 自动生成为整数序列(0, 1, 2, …)。
- 当 header 设置为数字时,该数字表示作为列标签的行数。例如,header=1 意味着第一行作为列标签;header=2 表示第一行和第二行合并作为多级列标签(对于多级索引的情况)。
- 如果 header=0,则表示第一行被视为数据的一部分,列标签由 pandas 自动生成。
index 参数
- index 参数确定是否将某一列(或多列)用作 DataFrame 的索引。
- 当设置为布尔值 True 或 False 时,表示是否将第一列作为 DataFrame 的索引。
- 如果设置为数字,那么这个数字表示作为索引的列数。例如,index=1 将第一列作为索引,index=2 将前两列作为多级索引。
- index=False 表示 DataFrame 的索引将由 pandas 自动生成,而不使用 Excel 数据中的任何列。
- index 参数通常不接受数字 0,因为这会导致混淆(是否表示不使用索引,或者使用第一列作为索引)。
header参数可以是布尔值True/False也可以是数字,True表示将表给内第一行作为列标签,False则列标签变成pandas自动创建的数字序列
heder参数是几,就可以指定将从0到几的行设为列标签,比如参数是1,就可以将第一行设为列标签,参数是2,就将第一行和第二行设为列标签,参数是0,就代表原来的表格内没有列标签,由pandas自动生成的0/1/2…序列数字来作为列标签
index参数的值可以是布尔值或数字,布尔值表示是否将第一列作为列标签
如果参数的值是数字,0表示DataFrame的index参数为pandas自动生成的从0开始的整数序列
参数是整数几,就表示将表格的前几列作为列标签
如果要将DataFrame数据通过xlwings写入Excel单元格,只要指定起始单元格的位置的value等于DataFrame即可
比如【ws.range(‘j1’).value=df】,需要注意的是,这会先将DataFrame的整体也就是包括index和列标签都转换成普通表格,然后开始从指定单元格位置写入
如果不需要index和列标签,可以通过options参数设置index和header都为0【ws.range(‘a1’).options(pd.DataFrame,header=0,index=0).value=df】