用Python统计了过去历史上,1日线周期下,每个交易日有多少个残血收割信号
目的是为了验证,当一个交易日密集出现多个残血收割信号时,是否可以确认市场已跌至底部
测试结果还算比较满意,基本都能抄到底,
但也有翻车的时候,比如2011/12/16和2001/10/12,
但大部分时候还是赚钱的,下跌了及时止损,亏损应该可以限制在10%以内,但抄到底部,可以赚百分之几十,盈亏比还是挺高的,胜率也高
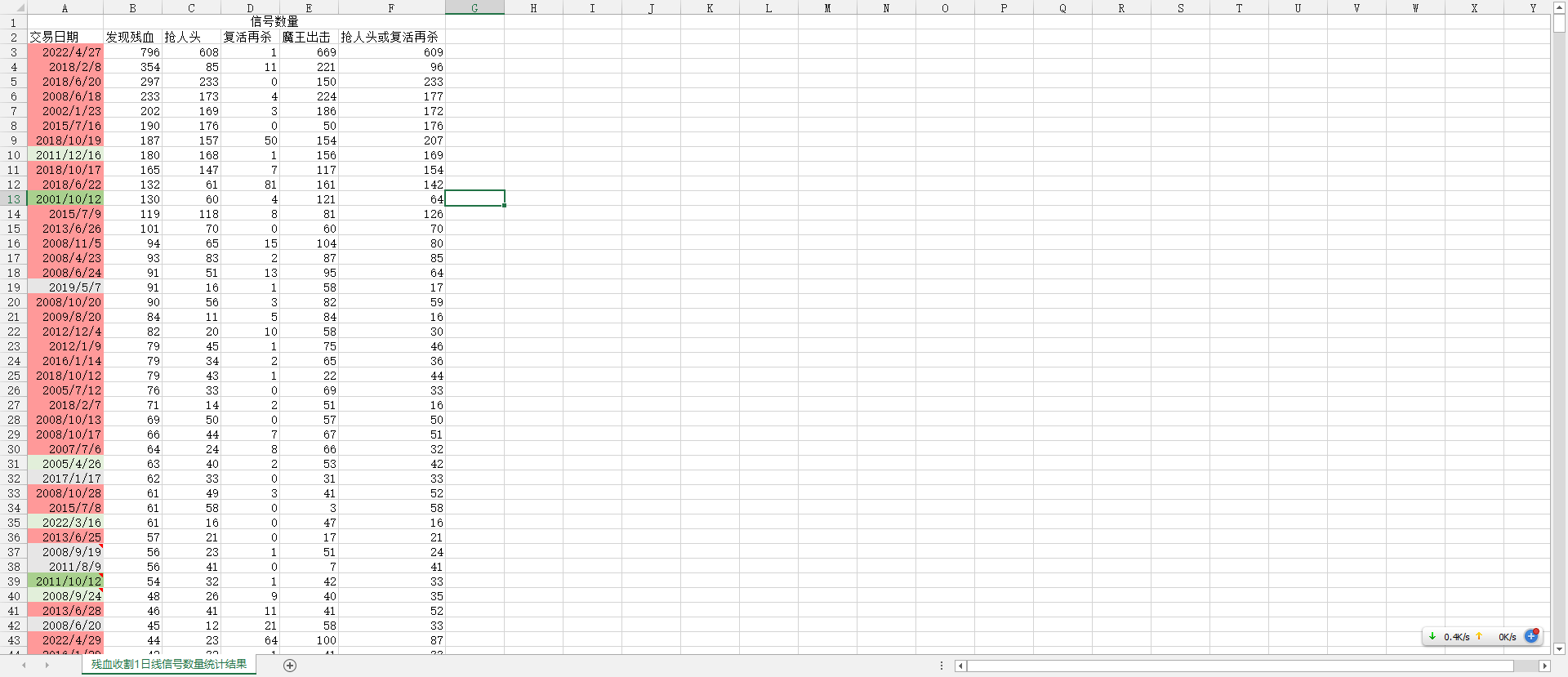
话说为了把这数据弄出来,可真的不容易啊§34§
我不知道如何导出通达信数据,只能用最傻瓜的方法,在个股的K线图页面,用键盘上的快捷键【3-4-回车-回车-ESC-PAGE DOWN】,当然,导出数千次股票,就得重复数千次,然后我用的是键盘模拟软件
然后遇到了第一个问题,就是导出的股票文件不完整,最后发现,如果焦点在K线图,按PAGE DOWN,就会跳到下一只股票,要是焦点在左侧的股票列表,那么按page down,就会跳到下一屏股票,这导致我漏了许多股票没导出。
好在导出的文件是以股票代码命名的,比如000001.xls,我就先把文件夹里的所有文件的文件里列表导出成TXT,用的命令是DIR /S/B >FILESLIST.TXT,导出来之后,放入EXCEL,然后分列,取得股票代码列表,再把股票代码放入TXT文件,然后在同花顺中导入TXT文件的股票,再在同花顺旗下的问财搜索【沪深上市,不包含自选股】,取得所有缺失的股票的列表,在通达信里加自选板块再导出一遍
然后尝试用Python读取excel文件,但是通达信导出的xls格式的文件Python竟然识别读取不了,又找了方法将xls文件批量转换成xlsx
我的思路是:
先创建一个空的DataFrame数据表,用Python依次读取每份股票文件的内容,然后把读取出来的内容存入前面的DataFrame数据表上,把几千只股票的数据合并成一张数据表,最后用pandas的groupby()计算每个交易日有多少残血收割信号
我先用几份文件试了一下,合并没问题,但是用goupby()进行统计时却出了问题,因为导出的excel文件存在空值或NaN值,用NaN值进行计算时就会报错,然后程序终止,
我自己也是个初学Python的新手,于是在网上找到代码,将pandas数据表中的空值与NaN值全部替换成0,但是不知道什么原因,我在网上找到的代码,会把交易日期那一列也全都替换成0,导致日期数据全部丢失,这样就不能知道每个交易日有多少信号了
我想出的办法是,每次读取Excel文件时,先复制一个备份,等我用网上的代码用0填充所有的空值和NaN值后,再用备份中的日期这一列替换掉需要用来合并的数据表
最后,我认为所有问题都已经解决可以开始搞了,结果发现又出了问题,我之前尝试将几只股票的历史数据合并成一张表时一切正常,但我要将几千只股票合并成一张表,电脑内存完全不够用,因为一个交易日期就是一行数据,一只股票会有几百几千行数据,几千只股票可能得有上千万行数据,电脑内存直接爆了,最后想到的办法是,每次读取Excel文件时,只保留有信号的行,没出信号的行全都忽略
最后一个问题解决后,程序终于顺利运行,导出了我想要的统计信息
使用的代码如下:
import os
import pandas as pd
file_location='C:/py/xlsx' #读取的文件夹
# file location存储我们要读取的数据的文件夹绝对路径
# for root, dirs, files in os.walk(file_location):
# # root输出文件夹,dirs输出root下所有的文件夹,files输出root下的所有的文件
# print('当前文件夹:', root)
# print('包含的文件夹:', dirs)
# print('包含的文件:', files)
# print()
pd.set_option('expand_frame_repr', False) # 当列太多时显示完整
#批量读取文件名称
file_list=[]
for root,dir,files in os.walk(file_location):
for filename in files:
if filename.endswith('.xlsx'):
file_path=os.path.join(root,filename) #通过os.path.join()函数,连接当前文件夹路径与文件名,返回给file_path
#file_path=os.path.abspath(file_path)
file_list.append(file_path)
print(file_list)
print('------------------遍历文件名,批量导入数据--------------------')
all_data=pd.DataFrame()
#for fp in sorted(file_list): #sorted()函数可以对包括列表、元组、字符串、字典、集合这些序列进行排序
for fp in sorted(file_list): #加入切片操作,只读取文件夹中前11个文件
print(fp) #打印文件路径与文件名
#导入数据
df=pd.read_excel(fp,skiprows=2,parse_dates=[' 时间'])
df = df.drop(labels=0) #删除索引值为1的行
df2=df
# 移除数据表内的空格
df.replace('\s+', '', regex=True, inplace=True)
df.fillna(0, inplace=True)
#
# # 将空值替换为0
df = df.replace(r'\s*', 0, regex=True).fillna(0)
#
df.replace('\s+', '', regex=True, inplace=True)
df.fillna(0, inplace=True)
rename_dict = {'残血收割.DCD ': '抢人头', '残血收割.CD ': '发现残血', ' 时间':'日期','魔王出击.MWGZ ': '魔王出击','残血收割.ZCD ': '复活再杀'} #
# '魔王出击.MWGZ ': '魔王出击',
# '残血收割.ZCD ': '复活再杀',
df.rename(columns=rename_dict, inplace=True)
#时间这一列莫名其妙会被删除,于是提前复制一个备份,在最后放回来
df['交易日期']=df2[' 时间']
df['抢人头与复活再杀']=df['抢人头']+df['复活再杀'] #只要等于1那就说明今天有残血收割信号
df['信号数量']=df['发现残血']+df['魔王出击']
#df.fillna(value=0, inplace = True)
#df=df.fillna(0)
#df['全残血收割'] = df['抢人头'] + df['复活再杀']
df = df[df['信号数量'] > 0] #仅保留有信号的行
#print(df)
#exit() #不加上这一一行,会连续读取,加上这一行,读取一个文件就结束for循环
all_data=all_data.append(df,ignore_index=True) #合并过多文件会响应过慢
print(all_data)
'''每次导入几千个文件耗时太长,可以将所有的文件合并成一个csv文件'''
#all_data.to_csv('all_data.csv',index=False,encoding='gbk')
'''导出数据为hdf文件格式'''
#all_data.to_hdf('全量通达信数据.hdf',key='all_data',mode='w') #key是数据表的名字,类似于Excel工作簿中的工作表,W模式为覆盖
all_data.to_csv('全量通达信数据.csv',encoding='gbk')
all_data.groupby('交易日期' ,as_index=False)['发现残血','抢人头','复活再杀','魔王出击','抢人头与复活再杀'].sum().to_csv('统计结果.csv',encoding='gbk')
#all_data.groupby('日期' ,as_index=False)['复活再杀'].sum().to_csv('统计结果2.csv',encoding='gbk')
代码VBA,将XLS文件批量转换成XLSX文件
右键Sheet1查看代码,插入模块,在模块中修改xls文件路径,文件路径需要保留最后的/号,然后运行
Sub ConvertToXlsx()
Dim strPath As String
Dim strFile As String
Dim wbk As Workbook
' Path must end in trailing backslash
strPath = "C:\py\xls/"
strFile = Dir(strPath & "*.xls")
Do While strFile <> ""
If Right(strFile, 3) = "xls" Then
Set wbk = Workbooks.Open(Filename:=strPath & strFile)
wbk.SaveAs Filename:=strPath & strFile & "x", _
FileFormat:=xlOpenXMLWorkbook
wbk.Close SaveChanges:=False
End If
strFile = Dir
Loop
End Sub