1.使用Jupyter编辑器
此处为语雀视频卡片,点击链接查看:[4.1]–1. 使用Jupyter编辑器.mp4
安装jupyter的方法就像安装其他模块一样,可以使用【pip install】
在一个cell的第一行写上【%%time】,运行后可以得到这个代码执行起来需要多长时间,wall time表示这段代码从开始到结束所需要的时间,cpu time表示CPU核心的总计算时间,比如一个核心需要1秒,一共10个核心,那么cpu time就是10秒
魔法命令【%who】可以得到当前环境中所有变量的名字(不包含以_号开头的变量和系统特定的变量)
%who可以与数据类型参数搭配使用,比如【%who str】可以得到当前环境中所有的 字符串形式的变量
Python内置的数据类型有【str/int/float/list/dict/tuple/set/function】
除了基本的数据类型,也可以使用其他模块中的数据类型参数,比如【DataFrame/Series】
Jupyter中,所有魔发指令都以%号开头,如果只有1个%,就仅对这一行起左右,如果有2个,就针对整个cell
%time+代码,可以测试一行代码执行所需要的时间,比如【%timeit [x*x for x in range(10)]】/
如果一个cell的第一行为%%time,就可以得到运行这个cell的代码所需要的时长
cell不仅可以用来写代码,还可以用来做笔记,只需要在工具栏的下拉列表里将代码改成Markdown,这时每个单元格前面的【in】标志就会消失,那么这段话就不属于一个Python程序
工具栏中最后一个按钮提供了许多丰富的命令
如果一个cell写的代码陷入了死循环,可以点击【■】按钮中断
要想关闭一个文件,需要在主页的【running】中将这个文件关闭,保存的文件也可以在主页中的files中找到
或者直接在中断中按【ctrl+c】将整个jupyte关闭
Windows系统下,jupyter默认的文件保存目录是【C:\Users\用户名】
如果想要指定保存的文件夹,可以在终端中运行以下代码:
jupyter notebook –generate-config
在终端中就能看到一个py文件地址,用记事本打开后搜索【notebook_dir】
删除这一行开头的#号和空格,在后面的字符串参数中填入用于保存的文件夹路径
保存该py文件并重启jupyter即可应用新的文件存储路径
jupyter保存的文件格式为【.ipynb】,是一种容纳代码、交互过程、文字格式、输入输出效果等所有元素的特殊类型的文件。
如果用记事本打开,会发现里面的内容并非程序源代码,而是将用户输入输出的进去保存了进去,不是py文件意味着不能被import,想要在其他py文件中import,就需要先保存成py文件
如果想要保存为【.py】格式的源代码文件,直接在【file】菜单下选择【download】即可
jupyter中可以不写print(),直接敲入变量名就能输出该变量的值
如果修改了某个cell中的代码必须重新运行该cell,否则修改无效,意思是:
如果你修改了一个cell中的代码(例如,更改了变量的值、添加了新的代码行等),这些修改只会影响到该cell的代码,并不会自动重新执行该cell。因此,为了让这些修改生效,你需要手动重新运行该cell。
比如一个cell中a变量的值是0,运行其他cell后,将a改成1,在不运行a所在cell的情况下,在另一个cell中输出a,可以看到a还是0
可以通过快捷键【shift + enter】运行当前选中的cell
2.read_excel方法的常用参数
read_excel()方法默认读取工作簿中第一张工作表
工作表中的第一行会被作为列标签,下面的每一行都默认会被分配一个索引 index,index默认从数字0开始
engine 指定引擎
一些电脑的pandas可能无法读取xlsx文件,因为pandas默认使用xlrd模块来读取Excel文件,2.0以上版本的xlrd仅支持xls文件,因此必须通过openpyxl等其他第三方库才能正常读取xlsx工作簿文件,出现这种情况,可以修改参数为【engine=’openpyxl’】
sheet_name #指定读取工作表
如果要读取工作簿中指定的工作表,可以修改sheet_name参数,如果值为数字,可以指定第几章工作表,0为第一张工作表,比如【sheet_name=1】表示读取第二张工作表
也可以根据工作表名字来读取,直接将工作表名作为字符串参数即可,比如【sheet_name=’工作表名’】
sheet_name的参数还可以是list,可以让pandas一次读取多张工作表,这时候返回的就不是一个DataFrame对象,而是一个字典,
比如,【sheet_name=[0,1]】,表示读取第一张和第二章工作表,然后创建一个字典,键为0和1,值为两个对应的DataFrame
可以通过【df[0]】这样的方式(返回字典的值)来读取DataFrame
header #设置表头
如果工作表中的内容起始位置不是第一行,比如工作表内第一行和第二行都是第二行(或者第一行不是我们想要的内容),但pandas在读取时,仍然会从第一行开始,
如果工作表第一行和第二行都是空行,那么DataFrame的列标签就全是【Unnamed:0】这样的形式,数据集中第一行数据(对应工作簿中第一个空行),值全都是【NaN】
第一个解决方案时,通过header参数来指定哪一行作为表头,如果想以第三行作为表头,那就写【header=2】,那就会以第三行作为表头,同时跳过也就是不读取工作表内第一行和第二行内容,header的参数也可以是一个列表,可以让DataFrame有多个列标签
如果设置【header=None】,那么DataFrame的列标签就是从0开始的数字编号,如果不想用数字编号作为列标签,而又不指定工作簿中的内容作为表头,那么可以自己创建一个列标签,在【header=None】的同时,设置【names=字符串列表】,就能将llist中的每一个字符串作为DataFrame的列标签,这时,如果自己的列标签list中的字符串数量少于DataFrame实际的列数,那么自定义的列标签会被分配给最后几列
usecols #指定读取的列
如果工作表中前2列是空白的,可以使用usecols参数,该参数可以设置指定读取的列
参数的值可以是多种类型的数据
整数列表:指定要读取的列的索引,索引从0开始:
【pd.read_excel(‘data.xlsx’, usecols=[0, 2])】,只读取第一列和第三列的内容作为DataFrame
字符串,指定要读取的(字母)列或者连续的列:
df=pd.read_excel(‘data.xlsx’,sheet_name=2,skiprows=2,usecols=’B,D’) #仅读取B列和D列作为DataFrame
df=pd.read_excel(‘data.xlsx’,sheet_name=2,skiprows=2,usecols=’B:F’) #指定读取范围为B列到F列
甚至列索引交替着写:df=pd.read_excel(‘data.xlsx’,sheet_name=2,usecols=’a,b,d:f’)
range:第几列到第几列
df=pd.read_excel(‘data.xlsx’,sheet_name=2,skiprows=2,usecols=range(2,6)) #读取第二列至第六列
skiprows #跳过不想要的行
skiprows参数也可以跳过不想要的行,比如skiprows=2就是读取工作表时跳过前2行
也可以接受整数列表作为参数,指定跳过哪些行,行号从0开始,比如skiprows=[3,4]就表示跳过第五行和第六行
函数也可以作为skiprows的参数,这个函数需要接受一个参数(行索引)并返回一个布尔值,表示是否应该跳过该行,需要注意的是,行索引是从0开始的,所以工作表中的第一行对应行索引中的数字0
def skip_even_rows(index):
# 如果是偶数行返回True
return index % 2 == 0
df = pd.read_excel('data.xlsx', sheet_name=2, usecols='a,b,d:f', skiprows=skip_even_rows)lambada函数同样可以作为skiprows的参数
实现上一段示例代码同样的功能,可以写成【df=pd.read_excel(‘data.xlsx’,sheet_name=2,usecols=’a,b,d:f’,skiprows=lambda x:x%2==0)】
index_col #指定哪一列作为index
index_col可以指定哪一列的内容作为index,如果不指定,则会自动生成从0开始的编号
如果值是整数,就指定第几列作为index,数字0表示指定第1列作为index
如果值是整数列表,比如[0,1],就指定第一列和第二列作为index
上述两种方法的数值是基于DataFrame而不是基于工作表的
如果值是字符串,就指定哪个列标签下的列作为index,比如index_col=’天气’,就指定列标签为天气的那一列作为index
如果是字符串列表,就指定将多个列标签下的列作为index,比如index_col=[‘城市’,’天气’]
3.DataFrame与Series
一个DataFrame是由若干个列做成的,而每一个列也都是一个Series,通过df[‘列标签’]可以取出指定列的数据,而且print后自带索引
series.values[0]可以读取该Series中第一个元素
一个Series对象就是有一个ndarray数组对象和一个index索引对象构成的整体,创建一个Series对象只需要指定一个数据来源和一个索引来源即可
如果有l1和l2连个列表,通过pd.series(l1,l2)即可创建一个Series,其中l1会被作为Series的内容,l2会被作为index,
创建Series之前,pandas会先将内容转换成ndarray和index,再组成Series,也就是说,只要是能被转换成ndarray的对象(列表、元组等等),都能作为Series的数据来源,
index不仅仅能使用数字,还可以使用字符串,修改index的方法也非常简单,只要Series.index=数据来源 即可
通过Seriess[数字下标]也可以访问Series中的元素,下标从0开始计数,比如【Series[0]】就是获取其中的第一个元素,但需要注意是,如果Series的index也是数字,那么这种方式的含义就是通过index序号来取得元素
还有一个方法是将Series的数字格式的index转换成文本格式,就能通过Series[下标]的方式访问其中的元素【Series.index=[str(i) for i in Series.indedx]】
4.Series对象的创建与使用
Series同时具有字典和数组的特性
与字典的相似之处
可以通过【S=DataFrame[‘列标签’] 】的方式,从一个DataFrame中抽取一列作为一个Series,而原DataFrame中的index也会跟着成为新创建的Series的index
可以通过字典创建Series,字典的键会变成Series中的index
import pandas as pd
d={'a': 1, 'b': 2, 'c': 3}
s=pd.Series(d)
print(s)在字典中,可以通过【对象 in 字典】的方式来判断该字典是否存在某个键,Series也可以使用同样的方法,来判断Series中是否存在某个index
import pandas as pd
d={'a': 1, 'b': 2, 'c': 3}
s=pd.Series(d)
print('a' in s) #True该方法只对字典的键和Series的index有效
字典可以通过方括号的方式来添加某个键值对,Series也可以使用这个方式添加元素
s[‘x’]=6 #在变量名为s的Series中,创建index为x,对应的值为6
S.keys()与S.index的效果相同
字典对象的【.keys()】【.values()】【.items()】方法分别可以返回该字典的键、值和,Series也可以使用同样的方法
需要注意的是,针对Series使用【.keys】和【.keys()】得到的返回结果不同,其中【.keys()】可以得到所有的键,
根据ChatGPT的解释:
s.keys:这只是对Series对象的keys方法的一个引用,而并不是调用该方法。所以,s.keys实际上会返回Series对象的keys方法本身,而不是这个方法的结果。简言之,你会得到一个方法对象。
s.keys():这是对Series对象的keys方法的实际调用。它会返回这个Series对象的索引。
字典的.items()方法可以返回一个迭代器,该迭代器可以生成字典中的键-值对元素(返回一个包含所有 (key,value)对元组的视图对象),
Series对线也有【.items()】方法,该方法会返回一个迭代器,可以使用list()方法强制转换成列表
import pandas as pd
d={'a': 1, 'b': 2, 'c': 3}
s=pd.Series(d)
#print(d.keys()) #dict_keys(['a', 'b', 'c'])
print(s.keys)
'''
<bound method Series.keys of a 1
b 2
c 3
dtype: int64>'''
print('---')
print(s.keys()) #Index(['a', 'b', 'c'], dtype='object')
print(s.index)
print(d.values()) #dict_values([1, 2, 3])
print(s.values) #没有括号 #dict_values([1, 2, 3])
print(d.items())
print(s.items()) #<zip object at 0x000001CEBFFDB180> 得到的是一个zip对象,可以强制转换成列表
print(list(s.items())) #[('a', 1), ('b', 2), ('c', 3)]与numpy的相似之处
numpy和Series都可以通过下标的方式访问里面的数据(下标计数从0开始)
numpy和Series都支持花式索引
花式索引允许你不仅仅通过单个数字或连续的数字范围来获取数据,还可以使用一组自定义数字或条件来选择你想要的数据,注意Series使用花式索引时有两个方括号
Series不仅可以通过数字下标的方式来使用花式索引,还可以使用index的内容来进行花式索引
numpy和Series都支持使用掩码、布尔索引
numpy和Series都可以通过切片的方式来截取子集
如果使用数字下标的方式,截取的内容不包含结尾元素,如果通过index指定范围,截取的内容包含结尾元素
如果Series中的index列本身也是数字,就会造成混淆(如果index索引是数字,pandas会按照从0开始计数的下标来截取)
为了避免混淆,强烈建议使用loc[]与iloc[]的方式来截取,其中,Series.loc[]是按照index来进行切片(包含结尾元素),而Series.iloc[]是按照下标数字来进行切片(不包含结尾元素)
Series的索引值允许重复
5.DataFrame对象的创建与使用
将多个Series组合成DataFrame
可以通过多个Series来创建一个DataFrame
import pandas as pd
#创建2个Series对象
s1=pd.Series(['a','b','c'],name='a') #设置的name参数,当创建DataFrame时,会被作为列名
s2=pd.Series(['x','y','z'],name='x')
#使用concat函数将两个Series合并成一个DataFrame
df1=pd.concat([s1,s2],axis=1)
print(df1)
#通过集合的方式创建DataFrame,格式是列1名:列1值,列2名:列2值
df2=pd.DataFrame({s1.name:s1,s2.name:s2}) #s1.name的位置也可以改为其他字符串,作为列标签,s1的位置用于设置该列的值
print(df2)如何合并的两个Series长度不一致,那么较短的那个Series,长度缺失的部分,会被填充为NaN
取出DataFrame单列
取出DataFrame单列的代码,可以是【df[‘列标签’]】,也可以是【df.列标签】,
两种方法如果只取单列,会得到一个Series对象,
一般来说【df[‘列标签’]】这种方式更加通用,【df.列标签】这种方式,如果列标签与DataFrame的方法名或属性名冲突(比如count、sum等),可能会出错
之所以可以通过【df.列标签】这种方式得到一列,是因为pandas允许我们将DataFrame中的每一列看做这个DataFrame对象的一个属性,而属性名则是DataFrame中的列名
如果要再DataFrame中新建一列,使用的代码是【df[‘列标签’]=value】,其中value可以是一个列表也可以是Series
取出DataFrame多列
将要读取的列标签作为一个列表,再将列表放入【df[]】中,因此会有两个方括号,比如【df[[‘A列’,’B列’]]】
取出pandas单行
可以使用.loc[]与.iloc[]来按行读取DataFrame(注意是方括号)
如果取出的是单行数据,它返回的时一个Series对象,也就是将这一行的内容作为一个series列返回
其中,【.loc[]】是按照index的方式读取行,比如【df.loc[‘a’]】选取的是index中为a的行,可以通过【df.loc[‘index1′:’index10’]】这种方式读取多行,返回的是DataFrame(index10这一行也会包含在返回结果中)
还可以将要读取的行的index放入列表中,再放入【df.loc[]】内来获得多行,比如【df.loc[[‘索引1′,’索引2′,’索引3’]]】,注意有两个方括号
甚至还可以是一个判断条件,如果比如只希望读取:A列中数值大于800 的行,可以写【df.loc[df[‘A’]>800]】,可以使用【与或非】的方式增加多个判断条件,需要使用字符【& | ~】,此外,每个条件都应该用圆括号括起来,
比如得到df中 所有A列值大于100,同时,B列值小于999999的行,可以写成【df[(df[‘a’]>100) & (df[‘b’]<999999)]】
可以从DataFrame中选择特定index的特定列,比如【df.loc[‘索引2′:’索引20’,[‘列标签1′,’列标签2’]]】或者【b=a.loc[10:100,[‘日期’,’城市’]]】Index如果是数字不许要加上引号,
↑第一个参数甚至可以是一个筛选条件,比如有一个列标签是温度,筛选温度大于22的行,然后再取城市与降水量【b=a.loc[a[‘温度°C’]>22,[‘日期’,’城市’]]】(a是源DataFrame,注意写筛选条件时一定要写全,将原DataFrame名与列名写上,而不是只写一个列名)
【.iloc[]】是按照数字下标(从0开始计数)的方式按行读取pandas,比如【df.iloc[0]】,无论index是什么,都会读取DataFrame中的第一行,其他使用方法与loc[]相同,需要记住的是,使用切片时,最后一个元素不会放在切片内,比如【b=a.iloc[0:2]】只包含第一行与第二行,不包含下标数字为2的第三行
转换成numpy二维数组
有时候希望像处理numpy一样处理DataFrame,由于pandas就是基于numpy,通过【df.values】便可得到一个numpy二位数组,其中便是DataFrame中的完整内容
6.DataFrame运算与统计
pandas中的计算规则
DataFrame可以整体进行运算,比如【df*10】可以返回一个,df中所有数值都乘以10后的DataFrame,如果单元格中的内容是文本,乘以几就是重复多少次,比如’abc’*2就会变成’abcabc
可以导入numpy模块,然后使用numpy中的函数对df进行运算,比如,对DataFrame中的所有数字,使用numpy的sqrt函数求平方根:
import pandas as pd
import numpy as np
def skip_even_rows(index):
# 如果是偶数行返回True
return index % 2 == 0
# df=pd.read_excel('data.xlsx',sheet_name=2,usecols='a,b,d:f',skiprows=lambda x:x%2==0)
df = pd.DataFrame({
"A": [2, 3, 3],
"B": [6, 6, 6]})
# 使用np函数对dataframe进行运算
result = np.sqrt(df)
print(result)
'''
A B
0 1.414214 2.44949
1 1.732051 2.44949
2 1.732051 2.44949'''
result=np.sum(df) #sum函数会对每列进行统计,而不是统计整张表的总和
print(result)
'''
A 8
B 18
dtype: int64'''
#dataframe的values属性相当于一个numpy二维数组
#想要如果想要计算整张表的总和
result=np.sum(df.values)
print(result) #26df之间加减乘除以及求模、乘方、整除
如果两个 列标签与index 以及形状 相同的DataFrame进行相加,返回的DataFrame中的每个数值都是之前两个DataFrame中对应数值的和,
如果列标签与形状不相同,在相加后的返回结果中,相同位置(列标签与索引)可以正常求和,其他位置都会被NaN填充(原理是对两个DataFrame进行相加时,会先进行对其,也就是让两个df保持相同的列标签与Index,比如pandas会让两个df设置相同的列标签,会把两个df之前各自独有的列标签加入给对方,但新创建的列标签的数值会被NaN填充,计算结果也就是NaN了)
在上面的情况中,两个df之间相加,如果想要避免一个数值+一个NaN返回一个NaN,可以使用df1.add(df2),相当于df1+df2,此时返回结果中仍然会是nan,但是可以通过加上参数,让数字+nan=数字本身,我们可以写成【df1.add(df2,fill_value=0)】,相当于将nan填充为0,然后进行运算,需要注意的是,使用add函数进行两个df的相加时,如果两张表同一个位置都是nan,返回结果仍然是nan,只有两张表中,一个位置是数字,另一张表同一个位置为0,另一个表中相同位置的nan才会被填充为0
不仅仅只有add函数进行两个DataFrame的相加,还可以进行减乘除以及求模、乘方、整除
| 函数 | 功能 | 解释 | 反向函数 | |
| add | 加法 | df1.add(df2)相当于df1+df2 | radd | |
| sub | 减法 | df1.sub(df2)相当于df1-df2 | rsub | df1.rsub(df2)相当于df2-df1 |
| mul | 乘法 | rul | ||
| div | 除法 | rdiv | ||
| mod | 求模 | rmod | ||
| pow | 乘方 | rpow | ||
| floordiv | 整除 | rfloordiv |
以上函数都可以使用fill_value参数来指定缺失值该如何处理
DataFrame(二维)与Series(一维)数组也能进行运算
当把DataFrame与Series放一起运算时,Pandas会将Series看做一行数据,而不是一列数据
如果直接把df与Series放一起运算,Series会被转换成df,其中Series的index变成列标签,,每个值都变成对应列标签下唯一的值,从Series转换得来的df只有一行数据,并且没有索引,由于没有索引,与另一个df相加时这一行的内容(原Series的值会被忽略),因此df与Series直接进行运算,得到的DataFrame全都是Nan
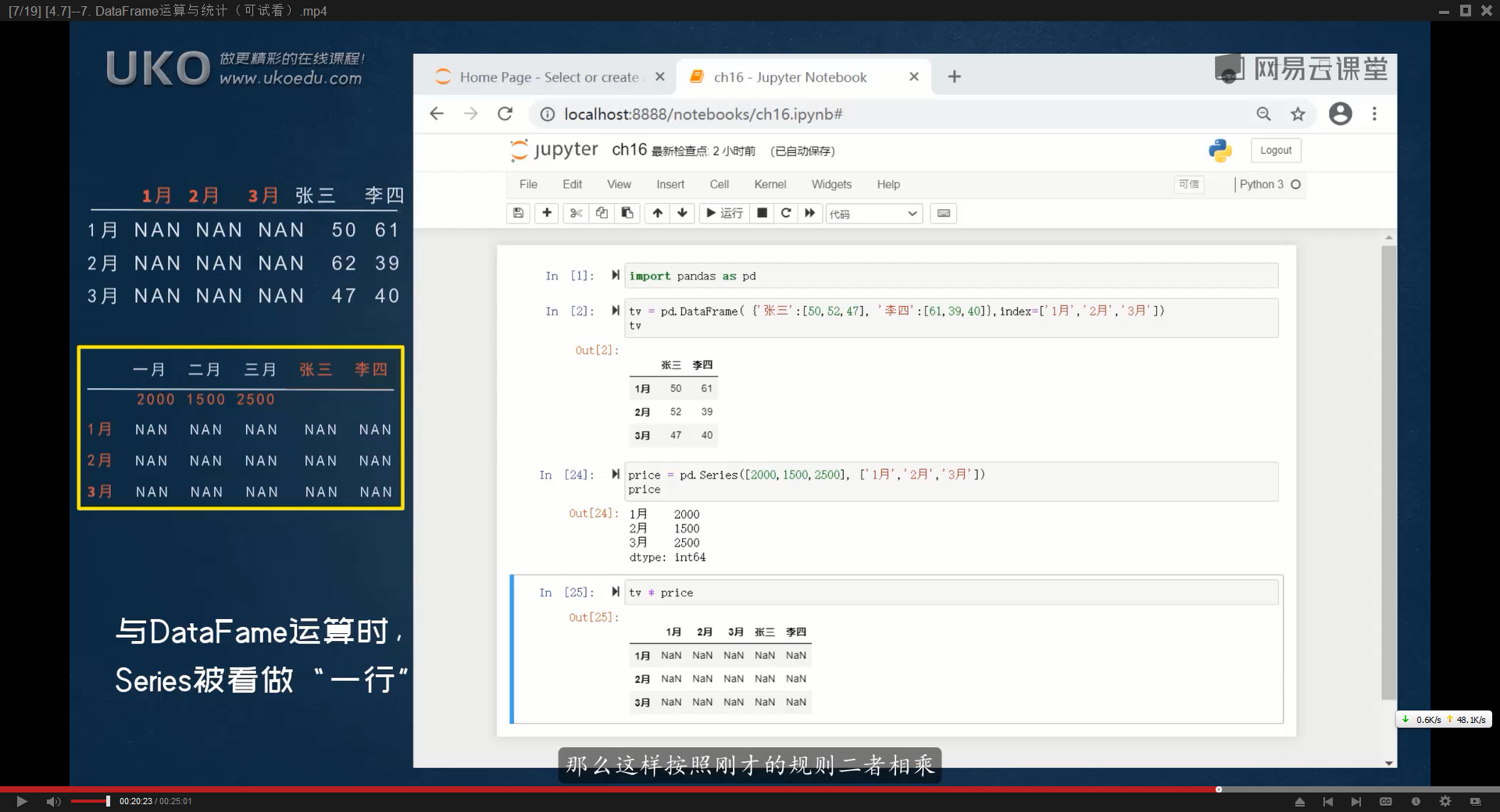
如果让一个df中的每个值,乘以另一个Series中相同index的值,可以使用【df1.multiply(series,axis=0)】,将Series(竖着)转换成相同形状的DataFrame(参数中,可以使用’index’代替0,’columns’代替1)
7.map、apply、applymap方法的使用
map/apply/applymap这三个函数并不会对原来的数据进行修改,而是返回一个新的结果
针对Series的map()函数
在Pandas中,Series有一个专门的函数叫做【map()】,用法是【Series.map(参数)】,
参数可以是一个函数(也可以是lambda)或一个字典,
如果参数是函数,填写参数时不需要加后面的括号,只需要写入函数名,
该函数将对Series中的每一个元素进行计算,在对每一个Series进行计算后,返回一个新的Series,index保持不变,而每个元素都是旧Series元素的计算结果
如果map()函数的参数是一个字典,那么会用字典的值对Series的元素进行替换,返回一个新的Series,如果Series中的某个值在字典中找不到对应的键,在新创建的Series中该位置会被填充为NaN
import pandas as pd
import random
from datetime import datetime, timedelta
s=pd.Series([1,2,3,4,5]) #定义Series中每个元素的值
#使用map函数,对Series中的每个元素乘以2
s2=s.map(lambda x:x*2)
print(s2) #返回结果是2/4/6/8/10的Series以下代码中,先读取一个房产数据表的每平方米均价列作为一个Series,然后创建一个函数,如果参数大于10000,返回’高档住宅’,否则返回’普通住宅’,利用map函数使用house_grade函数对Series进行计算,返回一个新的Series,index与旧的Series相同,内容则是只剩下高档住宅与普通住宅两种
s=df['每平方米均价']
def house_grade(price):
if price>100000:
return '高档住宅'
else:
return '普通住宅'
s2=s.map(house_grade)
print(s2)
print('--------------------')
#lamda写法,更加精简,效果相同
s3=s.map(lambda price:'高档住宅' if price>100000 else'普通住宅')
print(s3)map函数中以字典作为参数
import pandas as pd
# 创建一个Series
s = pd.Series(['cat', 'dog', 'bird','test'])
# 使用map函数,用字典进行映射
new_s = s.map({'cat': '猫', 'dog': '狗', 'bird': '鸟'})
print(new_s) #test因为没有对应的键值,新Series对应的位置会被填充为NaN此外,map函数还可以对DataFrame中的某一列进行操作,比如【df[‘列标签’]=df[‘列标签’].map(lambda x:x*2)】
针对DataFrame的apply函数
apply函数与map函数类似,但它可以对DataFrame中的一列或一行进行计算,如果要对每一行进行计算,要设置第二个参数【axis=1】,比如对df每行进行求和可以写成【result = df.apply(sum, axis=1)】
apply的参数可以是系统自带函数、自定义函数甚至lambda函数
返回结果通常是一个Series,如果对每列进行计算,那么返回的Series的index是df的列标签,对应的值是该列的计算结果,如果对每行进行计算,index还是DataFrame的index
lambda参数示例:
比如,要计算df中每一列最大值与最小值的差,可以写成【result=df.apply(lambda x:x.max()-x.min())】
import pandas as pd
import numpy as np
from pprint import pprint
df=pd.read_excel('房源数据.xlsx',index_col=0)
print(df)
#从一个房产数据表中,判断哪些房源属于高档住宅
# 判断条件为平米均价超过10万,面积超过3百平方米
def house_grade(house):
if house['平米均价']>100000 and house['面积']>300:
return '高档住宅'
else:
return '普通住宅'
print(df.apply(house_grade,axis=1)) #注意是axis=1
#设置了axis=1,就相当于将每一行作为一个数据集,交给apply函数进行运算applymap
与apply逐行或逐列处理不同,applymap可以处理逐个单元格处理并且返回一个新的DataFrame
比如,要对DataFrame中每个元素乘以2,可以写【new_df=df.applymap(lambda x:x*2)】
import pandas as pd
import numpy as np
from pprint import pprint
df=pd.read_excel('房源数据.xlsx',index_col=0)
print(df)
#只保留数据表中每个元素的第一个字符,后面都隐藏成XX
def code(x):
s=str(x)[0]+'xx'
return s
print(df.applymap(code))
'''
平米均价 面积 房屋总价 挂牌时间 卧室数量 客厅数量 卫生间数量 交易时间 楼层信息
房源编码
房源1 1xx 1xx 2xx 2xx 4xx 2xx 1xx 2xx 1xx
房源2 1xx 1xx 2xx 2xx 3xx 1xx 1xx 2xx 1xx
房源3 6xx 6xx 3xx 2xx 2xx 6xx 5xx 2xx 7xx
房源4 1xx 1xx 1xx 2xx 4xx 2xx 2xx 2xx 8xx
房源5 9xx 1xx 1xx 2xx 1xx 2xx 3xx 2xx 1xx
房源6 5xx 1xx 5xx 2xx 3xx 1xx 2xx 2xx 7xx
房源7 1xx 9xx 1xx 2xx 2xx 1xx 2xx 2xx 1xx
房源8 7xx 1xx 1xx 2xx 4xx 2xx 2xx 2xx 1xx'''pandas内置的常用的统计运算的函数
DataFrame和Series都能使用
| 函数 | 功能 |
| count() | 非空值的总个数 |
| sum() | 全部数值加总 |
| mean() | 平均值 |
| median() | 中位数 |
| mode() | 众数 |
| std() | 标准差 |
| min() | 最小值 |
| max() | 最大值 |
| abs() | 绝对值 |
| prod() | 全部元素相乘之积 |
| cumsum() | 从第一个元素到本元素的累加之和 |
| cumprod() | 从第一个元素到本元素的累乘之积 |
| argmax() | 返回数值最大的元素在第几行 |
比如【df.count()】可以返回每一列的非空值的个数(Series对象)
df.cumsum()的案例
import pandas as pd
# 创建一个简单的 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 计算累计和
result = df.cumsum()
print(result)
'''
A B C
0 1 4 7
1 3 9 15
2 6 15 24
'''# 使用 apply 函数计算每个字符串中 'a' 的出现次数
df['count_a'] = df['text'].apply(lambda x: x.count('a'))import pandas as pd
# 创建一个简单的 DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 沿着列(axis=0)进行求和,也就是说,计算每一列的总和
sum_by_column = df.apply(sum, axis=0)
print("Sum by column:")
print(sum_by_column)
# 沿着行(axis=1)进行求和,也就是说,计算每一行的总和
sum_by_row = df.apply(sum, axis=1)
print("Sum by row:")
print(sum_by_row)argmax()与idxmax()
【argmax()】返回最大的数值在第几行(从0开始计数),好像只能针对Series或df的某一列使用
比如【print(df[‘平米均价’].argmax())】将返回【df中’平米均价’这一列最大的数值在第几行】
可以再通过df.iloc(行号)来得到这一行的数据
如果针对整个df使用,可以使用【idxmax()】函数
需要注意的是,如果df中某一列不适用于统计最大数,那么可能会触发报错
可以先筛选出数值列,然后再使用【idxmax()】函数
df=pd.read_excel('房源数据.xlsx',index_col=0)
print(df.select_dtypes(include=['number']).idxmax())如果一些非数值列可以被转换为数值,也可以尝试以下代码:
df[‘your_column’] = pd.to_numeric(df[‘your_column’], errors=’coerce’)
这里,errors=’coerce’ 会将无法转换的值设置为 NaN。
idxmax()也可以针对DataFrame中某个列标签使用,将直接返回该列数值最大的单元格对应的index
print(df[‘平米均价’].idxmax())
corr()函数用于计算列之间的相关系数
corr()函数可以用于计算DataFrame中列与列之间的相关系数,
这主要用于探究不同数值变量之间是否存在某种关系,该函数默认计算的是Pearson的相关系数,取值范围是-1到1的小数。
它会返回一个新的DataFrame,列标签还是原来的列标签,index也是原来的列标签,越接近1表示这两个组的相关性越高(正相关),代表它在原来的df中,一列的数值越高,另一列的数值也越高
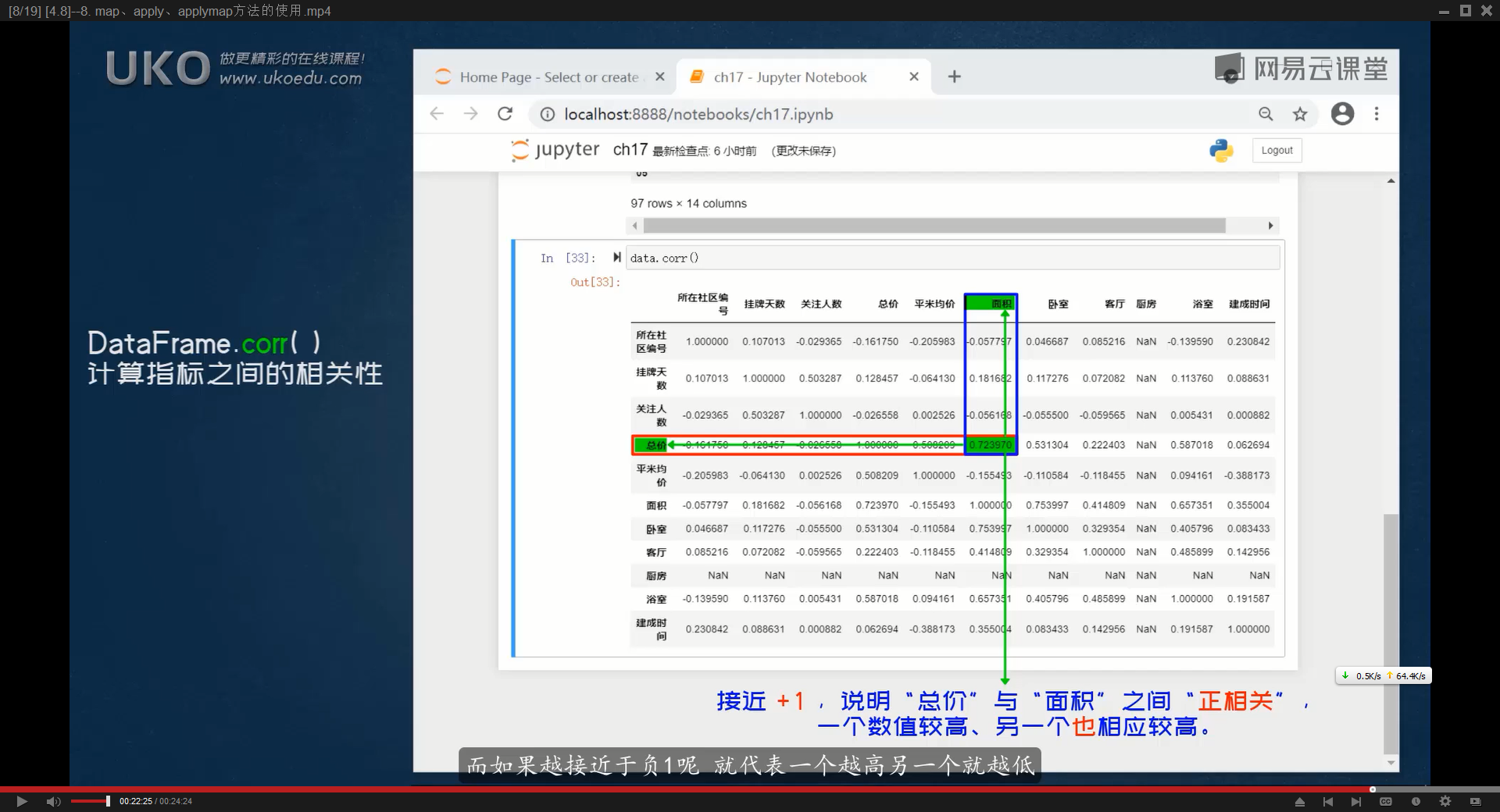
df.corr() 函数默认会尝试将所有列转换为浮点数类型进行计算。但如果 DataFrame 中含有不能转换为浮点数的列(如日期、字符串等),则会抛出这个错误。
解决这个问题有几种方法:
删除或忽略非数值列:你可以仅选择数值列进行相关性计算。
numeric_df = df.select_dtypes(include=[‘number’])
print(numeric_df.corr())
手动转换数据类型:如果你确实需要某个非数值列参与计算,考虑是否可以将其转换为数值形式。但请注意,对于日期或其他非数值数据,这通常没有意义。
数据预处理:在使用 df.corr() 之前,确保所有涉及计算的列都是数值类型。例如,如果有日期字段,考虑是否真的需要它参与相关性计算。
在进行任何操作之前,请仔细检查你的 DataFrame,了解每一列的数据类型和含义,以便做出合适的决策。
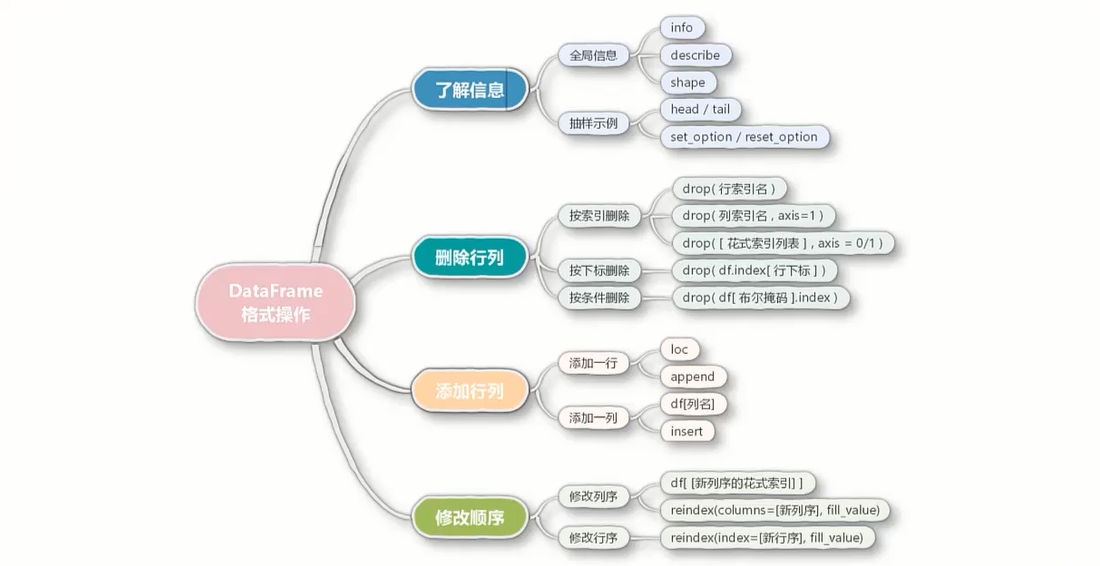
8.DataFrame行列编辑
了解信息
.info()函数可以获取DataFrame对象的详细信息,这个方法提供DataFrame的总览,包括列的数据类型、非空值的数量、内存使用情况等。
通常包含以下信息:
1.数据的类(通常是pandas.DataFrame)
2.索引的范围和类型
3.列的数量和名称
4.每一列的数据类型(dtype)
5.非空值的数量(每一列)(显示为 多少 non-null)
6.内存使用情况
<class 'pandas.core.frame.DataFrame'>
Index: 10 entries, 房源1 to 房源10
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 平米均价 10 non-null int64
1 面积 10 non-null int64
2 房屋总价 10 non-null int64
3 挂牌时间 10 non-null object
4 卧室数量 10 non-null int64
5 客厅数量 10 non-null int64
6 卫生间数量 10 non-null int64
7 交易时间 10 non-null object
8 楼层信息 10 non-null object
dtypes: int64(6), object(3) #不同类型的数据分别有多少列
memory usage: 800.0+ bytes
Nonedf.info()返回的是<class ‘NoneType’>
.describe()函数可以生成DataFrame的描述性统计信息,这个函数通常只对数值型列进行操作,返回以下统计量:
1.count:非空元素的数量
2.mean:平均值
3.std:标准差
4.min:最小值
5、25%:第一四分位数 (寻找第一四分位数,会先将一组数字从小到大排列,然后取出这组数字中位于25%这个位置的数值,这个数值小于这组数字钟其他4分之三的数值)
6、50%:中位数(第二四分位数)
7、75%:第三四分位数
8.max:(最大值)
平米均价 面积 房屋总价 卧室数量 客厅数量 卫生间数量
count 10.000000 10.000000 1.000000e+01 10.000000 10.00000 10.000000
mean 69567.800000 179.900000 4.889995e+06 4.500000 2.20000 2.300000
std 186393.595108 154.551286 1.095213e+07 5.562773 1.47573 1.159502
min 5175.000000 44.000000 5.162960e+05 1.000000 1.00000 1.000000
25% 9424.500000 104.750000 1.091350e+06 2.250000 1.25000 2.000000
50% 11960.500000 157.000000 1.387964e+06 3.000000 2.00000 2.000000
75% 13128.500000 173.500000 2.226428e+06 4.000000 2.00000 2.750000
max 600000.000000 600.000000 3.600000e+07 20.000000 6.00000 5.000000df.describe()返回的是<class ‘pandas.core.frame.DataFrame’>
.head()可以抽取DataFrame中最前面的几行数据,不填写参数默认返回前5行
.tail()可以抽取DataFrame最末尾的几行数据,不填写参数默认范围最后5行
庞大的DataFrame数据集在Print时经常显示不完整,如果洗碗看见完整的的DataFrame,可以通过set_option函数来进行,字面意思是设定选项,【pd.set_option(‘display.max_rows’,None)】,在None的位置可以填写其他任意非负整数,表示显示多少行,显示结果为自定义数值除以二得到X,然后显示df中前x行与后x行,比如参数写20,print时会展示DataFrame中前10行与最后10行数据
import pandas as pd
pd.set_option('display.max_rows',None) #None表示不限制最大行数在代码中插入【pd.reset_option(‘display.max_rows’)】可以重置设置,恢复成默认显示效果
.drop()函数删除行列
.drop()函数可以删除DataFrame中指定的行列,返回一个新的DataFrame,而不是修改旧的DataFrame,如果想要直接修改原来的df,可以设置参数【inplace=True】
删除列
默认删除会根据行索引来删除,如果想要删除特定的列,需要在参数中设置axis=1(该参数默认为0,删除特定的行)。
如果删除特定的单列,可以写成【df2=df1.drop(‘列标签’,axis=1)】
如果删除多个指定的列标签,可以写成【df2=df.drop([‘列标签1′,’列标签2’],axis=1)】,注意多个列标签要放在中括号内
删除行
删除特定的行,df.drop()内可以填写index索引名称,表示删除所有index为该字符串的行【df=df.drop(‘索引名称’)】
如果不知道索引名称,只知道要删除的内容处在第几行,可以先根据行号获取索引名称,然后再删除,
代码可以写成【df2=df1.drop(df1.index[0])】,index[0]别是第一行(一个索引对象index本质上就是一个一维数组或者说一维列表,加上方括号和序号就表示下标为序号的特定元素,也就获得了索引名称)
可以通过花式索引的写法删除多行多列,【drop([花式索引列表],axis=0/1)】,
比如【df.drop([‘索引1′,’索引2′,’索引3’])】的功能是根据索引index来删除多行,
如果要删除多列,可以设置axis=1,比如df.drop([‘列标签1′,’列标签2’],axis=1,inplace=True)
根据条件删除行
根据特定的条件删除行
思路是,先根据特定条件筛选出要删除的行,再得到他们的index,再将这个index交给drop函数
import pandas as pd
pd.set_option('display.max_rows',None)
#从数据表中,删除列标签下房屋总价小于1千万的房源的行
df=pd.read_excel('房源数据.xlsx',index_col=0)
#先筛选出房屋总价小于1千万的房源,得到他们的index索引名称
d=df[df['房屋总价']<10000000].index
print(d)
#将筛选出来的要删除的索引名称合计index交给drop函数
df.drop(d,inplace=True)
print(df)
'''
Index(['房源1', '房源2', '房源4', '房源5', '房源6', '房源7', '房源8', '房源9', '房源10'], dtype='object', name='房源编码')
#df中只剩下了总价大于1千万的房源
平米均价 面积 房屋总价 挂牌时间 卧室数量 客厅数量 卫生间数量 交易时间 楼层信息
房源编码
房源3 600000 600 36000000 2021-11-16 20 6 5 2022-04-10 7层/共29层
'''添加行与列
常用的插入列的方法
为DataFrame添加新的一列非常简单,只要写【df[‘新的列标签名’]=要添加的数据】即可,
比如【df[‘新列’]=’T’】,可以新增一列,并且这一列的内容全都是T,
需要注意的是,新列的赋值要么像上面那样,只有一个元素,该列所有内容都用它来填充,要么是一个列表,列表长度必须要与DataFrame的行数相同,否则会又诸如ValueError: Length of values (2) does not match length of index (10)这样的报错
.insert()在特定位置插入列
【.insert()】函数可以在DataFrame中的指定位置插入一列,不指定位置都是将新建列放在最后
注意,insert()函数会直接修改DataFrame,并且返回None,不需要在参数中填写inplace=True,一般也不需要用它给变量赋值
该函数的语法是:【df.insert(loc=整数,,column=列标签名,value=值,allow_duplicates=True/False)】
其中loc表示插入的位置,从0开始计数,参数为0表示将新建的列放在第一列
value参数可以是单个值(标量)、序列或数组
allow_duplicates表示是否允许重复,默认为False
示例代码【df.insert(0,’新列’,’内容’)】
通过.loc()插入行
语法是df.loc[‘索引名称’]=这一行的内容,比如【df.loc[‘索引名称’]=[0,0,0,0,0,0,0,0,0]】
注意,新建行的长度,一定要与DataFrame的宽度一致,否则会报错
.append()合并两个DataFrame
#该函数已经有FUTURE WARNING,未来可能会被放弃
.append()函数可以将一个df的内容添加至另一个df的最后,相当于合并两个DataFrame
pd.concat()合并两个DataFrame
最简单的写法是【result = pd.concat([df1, df2])】
df1=pd.read_excel('房源数据.xlsx',index_col=0)
df2=pd.read_excel('房源数据.xlsx',index_col=0)
df3=pd.concat([df1,df2])修改行列的顺序
修改列序(根据特定列标签得到一个新的DataFrame)
修改列标签排列顺序的第一个方法是,先创建一个列表,将df中的列标签按自定义顺序排好位置,
然后【df=df[[自定义顺序的列表]]】
注意:有两个方括号
提示:可以通过【df.columns】得到df的所有列标签的列表
示例:【df=df[[ ‘交易时间’, ‘楼层信息’,’平米均价’, ‘面积’, ‘房屋总价’, ‘挂牌时间’, ‘卧室数量’, ‘客厅数量’, ‘卫生间数量’]]】
事实上,以上代码的功能是:从原始的df中选择指定的列标签,得到一个新的DataFrame,再赋值给一个df,但如果填写完整的列标签,只是更改列标签的顺序,并且赋值给原来的df,这行代码就实现了更改列标签顺序的效果
修改行序
赋值新的index
可以直接让DataFrame的Index属性等于一个新的列表数组,这样可以一次性的改掉所有索引
比如【df.index=range(0,10)】,
注意自定义序列或列表数组的长度要和DataFrame原有Index的长度一致,否则会出现类似语音【ValueError: Length mismatch: Expected axis has 10 elements, new values have 9 elements】这样的报错,错误信息中包含了原始index的长度和新数组的长度
.reindex()调整Index与列序
.reindex()的columns参数可以改变列序,指定index参数可以改变行序,fill_value参数可以指定如何处理缺失值
df.reindex(columns=[新列序],fill_value)
df.reindex(index=[新行序],fill_value)
.reindex()函数可以修改DataFrame或Series的索引 和或 列,这个方法返回一个数据结构(通常是一个新对象),它包含与原始数据相同的数据,但可能有不同的行或列标签,或两者都有
.reindex()常见的应用场景有:
对索引重新排序:df=df.reindex(sorted(df.index))
对其不同索引的数据结构,用df1的index替换掉df2的index:df2.reindex(df1)
添加/删除行或列
通过reindex,你可以轻松地添加缺失的行或列(这些行或列将填充NaN或指定的填充值)
#添加d行并且内容都是NaN
df = pd.DataFrame([1, 2, 3], index=['a', 'b', 'c'])
new_index = ['a', 'b', 'c', 'd']
df=df.reindex(new_index)
print(df)使用其他的填充方法:.reindex()还允许你使用不同的方法来填充缺失的值,如向前填充(‘ffill’)或向后填充(’bfill’)
import pandas as pd
df = pd.DataFrame([1, 2, 3], index=[0, 2, 4])
new_index = [0, 1, 2, 3, 4]
df=df.reindex(new_index, method='ffill')
print(df)
'''
0
0 1
1 1
2 2
3 2
4 3'''.shape可以直接获取DataFrame的行数与列数
【df.shape】可以返回一个元组,第一个数字是DataFrame的行数,第二个数字是列数
如果只是想获得DataFrame的行数,可以使用【df.shape[0]】,列数同理
1 thought on “Python办公自动化【3】(实战篇数据分析之Pandas精讲(上))”