1.路径
绝对路径是标准的路径写法,以此电脑为出发点,
比如Windows系统下的【F:\教程\办公自动化】,或者Unix/Linux下【/home/username/documents/file.txt】
绝对路径可以确切地指示文件或目录的位置,无论当前所在的位置在哪里
相对路径是相对于当前工作目录,或另一个基准位置的路径,它描述了如何从当前位置或基准位置到达目标文件或目录,相对路径通常更短,且更易于移植,因为它们不依赖于特定的根路径
假设当前工作目录是 /home/username/documents/,一个相对路径可以是 file.txt,表示在当前工作目录中的文件 file.txt。 另一个例子,如果当前工作目录是 /home/username/,那么相对路径 documents/file.txt 表示从当前目录进入 documents 目录,然后访问文件 file.txt。
当Python解释器遇到一个相对路径时,它的起点并不是我们程序文件所在的目录,而是我们运行这个程序时系统当前的工作目录,
当我们在idle中运行程序时,idle会认为我们这个程序所在的文件夹就是当前正在使用的工作区域也就是工作目录,
但是在命令窗口运行它的时候,命令提示符前会显示一个路径,Python活在这个地址上执行解释操作
需要注意的是,如果a调用b,b里面存在相对路径,哪个b中的相对路径起点不是b所在的目录,而是a所在的路径,因此a与b如果不在同一个文件夹中,就需要注意这个问题
在Python中个【__file__】是一个内置变量,它包含当前脚本文件的路径,具体来说,它保存了当前模块(.py))的文件路径。
#在py文件的路径写入一个内容为hello的txt
from os.path import dirname
fname=dirname(__file__)+'\\'+'test.txt'
with open(fname,'w') as f:
f.write('hello')#在py文件的路径写入一个内容为hello的txt
from os.path import dirname
fname=dirname(__file__)+'\\'+'test.txt'
with open(fname,'w') as f:
f.write('hello')2.Pathlib基本用法
pathlib是Python3.4及之后版本的一个内置模块,用于处理文件系统路径,需要的是,pathlib为不同的操作系统设计了不同的path类,比如针对Windows的WindowsPath和真的Linux和MacOS等Unix风格系统的PosixPath类。
但平时仅仅使用Path类就已经足够,因为它能自动识别出程序正运行在哪个操作系统并且自动调用适用于对应操作系统的类。
执行文件操作首先要做的就是创建pathlib.Path类的对象,用Pathlib来代表要处理的文件夹、文件或者路径
.
from pathlib import Path
p1=Path(r'D:\Python\学习\test.xlsx')
print(p1.name) #获取完整的文件名 #test.xlsx
print(p1.suffix) #获取扩展名 #.xlsx
print(p1.stem) #不包含扩展名的文件名 #test
print(p1.parent) #获取文件所在的文件夹路径 #D:\Python\学习 #是一个WindowsPath对象
print(p1.drive) #文件在哪个磁盘分区 #D:
ps=p1.parents #得到一个迭代器,包含P1前面有多少个文件夹以及驱动器盘符
'''
D:\Python\学习
D:\Python
D:\
'''
#将迭代器转换成列表,列表中的任意一个元素都是一个path对象
print(list(ps)) #[WindowsPath('D:/Python/学习'), WindowsPath('D:/Python'), WindowsPath('D:/')]from pathlib import Path
p1=Path(r'D:\Python\学习\test.xlsx')
print(p1.name) #获取完整的文件名 #test.xlsx
print(p1.suffix) #获取扩展名 #.xlsx
print(p1.stem) #不包含扩展名的文件名 #test
print(p1.parent) #获取文件所在的文件夹路径 #D:\Python\学习 #是一个WindowsPath对象
print(p1.drive) #文件在哪个磁盘分区 #D:
ps=p1.parents #得到一个迭代器,包含P1前面有多少个文件夹以及驱动器盘符
'''
D:\Python\学习
D:\Python
D:\
'''
#将迭代器转换成列表,列表中的任意一个元素都是一个path对象
print(list(ps)) #[WindowsPath('D:/Python/学习'), WindowsPath('D:/Python'), WindowsPath('D:/')]如果是在Windows系统下运行,上述代码中的p1会自动转换成WindowsPath对象
文件夹没有扩展名,如果调用suffix属性,会返回空字符串,,suffix返回的扩展名包含小数点
path.parents可以创建一个迭代器,返回该文件前面的所有文件夹,可以循环遍历也可以转换成列表,遍历出来的每个元素又都是path对象
parents属性可以使我们轻松找到文件第N层上级文件夹
#通过parents属性得到前面第N层文件夹,0表示所在文件夹,再上一级文件夹就是1
print(p1.parents[0]) #返回所在文件夹 #D:\Python\学习#通过parents属性得到前面第N层文件夹,0表示所在文件夹,再上一级文件夹就是1
print(p1.parents[0]) #返回所在文件夹 #D:\Python\学习
可以通过【__file__】获取Python文件所在位置,然后拼接字符串,访问Python文件所在目录下的其他文件夹内的文件
from pathlib import Path
p=Path(__file__).parent
p=p/'新建文件夹/test.xlsx'
print(p) #D:\Python\学习\新建文件夹\test.xlsx
import xlwings as xw
app=xw.App()
wb=app.books.open(p)
#获取正常的绝对路径
print(p.resolve()) #D:\Python\学习\新建文件夹\test.xlsxfrom pathlib import Path
p=Path(__file__).parent
p=p/'新建文件夹/test.xlsx'
print(p) #D:\Python\学习\新建文件夹\test.xlsx
import xlwings as xw
app=xw.App()
wb=app.books.open(p)
#获取正常的绝对路径
print(p.resolve()) #D:\Python\学习\新建文件夹\test.xlsx
一个Path对象代表的只是一个文件的存储位置,而不是这个文件本身,
通过Path可以知道“去哪里找这个文件”,但若想知道此文件的内容,需要使用其他对象(比如文件对象、xlwings的工作簿对象等)
如果想要查看path对象代表的路径或者文件地址是否真的在磁盘上存在,可以通过Path.exists()方法来判断,返回True或False
3.按名称搜索文件
在path模块的基础上,可以很方便的实现文件搜索,比如搜索出所有的Excel文件,文件名包含某某关键词,甚至创建时间是某个日期之后,
pathlib模块中,Path对象的glob()方法用于生成当前目录下符合特定模式的文件和目录的迭代器,迭代器内的每一个元素都是path对线
该方法接受一个字符串参数,这个字符串定义了需要匹配的文件和目录的模式,它支持3个通配符,星号【*】和问号【*】和方括号【[]】,星号匹配任意数量的字符(包括0个),问号只匹配一个字符,
方括号表示字符集,可表示方括号内任意一个字符,或者[0-9]表示0到9的任意一个数字,【^】号表示否定的意思,【^0-9】表示非数字
比如,【*.*】表示任意多字符+小数点+任意多字符
需要注意的是【*.*】不代表匹配所有的文件,比如有的文件没有扩展名就匹配不出来,文件夹因为没有扩展名也不会被匹配
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
files=p.glob('*') #匹配当前目录下的所有文件与文件夹,不包含子文件夹
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('*.*') #匹配当前目录下的文件夹与文件夹名字
for i in list(files): #glob方法返回的是一个迭代器
print(i)
print('当前目录下所有的txt文件')
txtfiles=p.glob('*.txt')
for i in list(txtfiles):
print(i) #D:\Python\学习\新建文件夹\test.txt
#'如果想要在当前目录以及所有的子文件夹内进行搜索,需要使用**这个通配符'
print('找出当前目录以及所有子文件夹内所有的txt文件')
alltxt=p.glob('**/*.txt')
for i in alltxt:
print(i)
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
files=p.glob('*') #匹配当前目录下的所有文件与文件夹,不包含子文件夹
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('*.*') #匹配当前目录下的文件夹与文件夹名字
for i in list(files): #glob方法返回的是一个迭代器
print(i)
print('当前目录下所有的txt文件')
txtfiles=p.glob('*.txt')
for i in list(txtfiles):
print(i) #D:\Python\学习\新建文件夹\test.txt
#'如果想要在当前目录以及所有的子文件夹内进行搜索,需要使用**这个通配符'
print('找出当前目录以及所有子文件夹内所有的txt文件')
alltxt=p.glob('**/*.txt')
for i in alltxt:
print(i)
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
files=p.glob('**/*d*') #匹配文件夹以及子文件夹内所有名字带有d的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('?????.*') #匹配文件名5个字符扩展名不限的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('**/?????.*') #匹配文件名5个字符扩展名不限的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
files=p.glob('**/*d*') #匹配文件夹以及子文件夹内所有名字带有d的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('?????.*') #匹配文件名5个字符扩展名不限的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
files=p.glob('**/?????.*') #匹配文件名5个字符扩展名不限的文件
for i in list(files): #glob方法返回的是一个迭代器
print(i)
4.搜索子文件夹及按属性搜索
pathlib模块中Path对线感到rglob()方法是用于进行递归的全局搜索,它可以帮助你在一个目录以及其所有子目录中,查找符合特定pattern的文件和目录,rglob()方法返回一个生成器,生成匹配到的Path对象。
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
#使用rglob()方法搜索Path对象中所有以txt结尾的文件
txtInP=p.rglob('*.txt')
for i in txtInP:
print(i)from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
#使用rglob()方法搜索Path对象中所有以txt结尾的文件
txtInP=p.rglob('*.txt')
for i in txtInP:
print(i)
rglob与glob的区别在于:
glob()方法仅在当前文件夹(Path对象所表示的目录)中搜索,
rglob()方法则是在当前文件夹以及其所有子文件夹中递归地搜索符合条件的文件地址(包括Windows系统下的隐藏文件夹)
如果要通过rglob()方法搜索Path对象 所有子文件夹 中 名字带有 指定文字 的子文件夹 下的内容,写法可以是【/子文件夹名/匹配内容】
from pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
#使用rglob()方法搜索名字带有“学习”的子文件夹中的所有txt文件
txtInP=p.rglob('学习\*.txt')
for i in txtInP:
print(i) #D:\Python\学习\新建文件夹\新建文件夹\学习\新建文本文.txtfrom pathlib import Path
p=Path(r'D:\Python\学习\新建文件夹') #根据路径创建一个Path对象
#使用rglob()方法搜索名字带有“学习”的子文件夹中的所有txt文件
txtInP=p.rglob('学习\*.txt')
for i in txtInP:
print(i) #D:\Python\学习\新建文件夹\新建文件夹\学习\新建文本文.txt
Path对象有一个方法是stat(),可以用来获取文件或目录的元数据,返回其文件大小(字节为单位)、创建时间、修改时间等。
from pathlib import Path
p=Path(r'D:\Python\学习\test.xlsx') #根据路径创建一个Path对象
print(p.stat())
#os.stat_result(st_mode=33206, st_ino=8444249301840351, st_dev=2685363464, st_nlink=1, st_uid=0, st_gid=0, st_size=9877, st_atime=1688539310, st_mtime=1688539310, st_ctime=1687070476)
'''
`os.stat_result` 对象是 `stat()` 方法的返回值,它包含了文件或目录的元数据。以下是您提供的 `os.stat_result` 示例中各个字段的解释:
- `st_mode`:文件的模式(权限和类型)。在这个例子中,值为 `33206`,它表示文件的权限和类型。
- `st_ino`:文件的 inode 号。在这个例子中,值为 `8444249301840351`。这是文件在文件系统中的唯一标识符。
- `st_dev`:包含文件的设备 ID。在这个例子中,值为 `2685363464`。这表示文件所在的存储设备。
- `st_nlink`:文件的硬链接数。在这个例子中,值为 `1`。这表示有多少个目录项指向该文件。
- `st_uid`:文件所有者的用户 ID。在这个例子中,值为 `0`。
- `st_gid`:文件所有者的组 ID。在这个例子中,值为 `0`。
- `st_size`:文件大小(以字节为单位)。在这个例子中,值为 `9877`,表示文件大小为 9877 字节。
- `st_atime`:最后访问时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1688539310`。
- `st_mtime`:最后修改时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1688539310`。
- `st_ctime`:创建时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1687070476`。*注意:在 Unix 系统上,`st_ctime` 通常表示最近一次元数据更改的时间,而不是创建时间。*
值得注意的是,某些字段(如 `st_uid` 和 `st_gid`)可能在不同的操作系统上具有不同的意义。在 Windows 系统上,这些字段可能没有实际意义。'''from pathlib import Path
p=Path(r'D:\Python\学习\test.xlsx') #根据路径创建一个Path对象
print(p.stat())
#os.stat_result(st_mode=33206, st_ino=8444249301840351, st_dev=2685363464, st_nlink=1, st_uid=0, st_gid=0, st_size=9877, st_atime=1688539310, st_mtime=1688539310, st_ctime=1687070476)
'''
`os.stat_result` 对象是 `stat()` 方法的返回值,它包含了文件或目录的元数据。以下是您提供的 `os.stat_result` 示例中各个字段的解释:
- `st_mode`:文件的模式(权限和类型)。在这个例子中,值为 `33206`,它表示文件的权限和类型。
- `st_ino`:文件的 inode 号。在这个例子中,值为 `8444249301840351`。这是文件在文件系统中的唯一标识符。
- `st_dev`:包含文件的设备 ID。在这个例子中,值为 `2685363464`。这表示文件所在的存储设备。
- `st_nlink`:文件的硬链接数。在这个例子中,值为 `1`。这表示有多少个目录项指向该文件。
- `st_uid`:文件所有者的用户 ID。在这个例子中,值为 `0`。
- `st_gid`:文件所有者的组 ID。在这个例子中,值为 `0`。
- `st_size`:文件大小(以字节为单位)。在这个例子中,值为 `9877`,表示文件大小为 9877 字节。
- `st_atime`:最后访问时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1688539310`。
- `st_mtime`:最后修改时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1688539310`。
- `st_ctime`:创建时间(以秒为单位,自 epoch(1970-01-01 00:00:00 UTC)起)。在这个例子中,值为 `1687070476`。*注意:在 Unix 系统上,`st_ctime` 通常表示最近一次元数据更改的时间,而不是创建时间。*
值得注意的是,某些字段(如 `st_uid` 和 `st_gid`)可能在不同的操作系统上具有不同的意义。在 Windows 系统上,这些字段可能没有实际意义。'''
st_atime/st_mtime/st_ctime返回的数字代表从1970年1月1日0点到该时间点所经历的秒数,可以通过datetime模块中的datetime的fromtimestamp()方法转换成正常的日期格式
from datetime import datetime
dt=datetime.fromtimestamp(1688539310)
print(dt) #2023-07-05 08:41:50
print(dt.year) #2023
print(dt.month) #7
print(dt.day) #5
print(dt.hour) #8
print(dt.minute) #41
print(dt.second) #50from datetime import datetime
dt=datetime.fromtimestamp(1688539310)
print(dt) #2023-07-05 08:41:50
print(dt.year) #2023
print(dt.month) #7
print(dt.day) #5
print(dt.hour) #8
print(dt.minute) #41
print(dt.second) #50
使用rglob()方法搜索文件夹内小于10KB的文件
from pathlib import Path
p=Path(r'D:\Python\学习') #根据路径创建一个Path对象
files=p.rglob('*.*') #将该文件价内所有文件地址Path对象存储成一个迭代器
for f in files: #遍历迭代器
s=f.stat() #获取元素属性
if s.st_size<1000: #如果元素的大小属性小于1000字节
print(f.name,s.st_size) #输出文件名与文件的字节数
'''
>>> runfile('D:/Python/学习/a.py', wdir='D:/Python/学习')
a.py 286
b.py 19
test.txt 5
app.xml 811
core.xml 593
sharedStrings.xml 605
workbook.xml 777
printerSettings1.bin 220
printerSettings2.bin 220
sheet2.xml 919
sheet1.xml.rels 322
sheet2.xml.rels 322
workbook.xml.rels 839
.rels 588
b.cpython-310.pyc 144
detect.txt 0
test.txt 5
demo.txt 0
新建文本文.txt 0'''from pathlib import Path
p=Path(r'D:\Python\学习') #根据路径创建一个Path对象
files=p.rglob('*.*') #将该文件价内所有文件地址Path对象存储成一个迭代器
for f in files: #遍历迭代器
s=f.stat() #获取元素属性
if s.st_size<1000: #如果元素的大小属性小于1000字节
print(f.name,s.st_size) #输出文件名与文件的字节数
'''
>>> runfile('D:/Python/学习/a.py', wdir='D:/Python/学习')
a.py 286
b.py 19
test.txt 5
app.xml 811
core.xml 593
sharedStrings.xml 605
workbook.xml 777
printerSettings1.bin 220
printerSettings2.bin 220
sheet2.xml 919
sheet1.xml.rels 322
sheet2.xml.rels 322
workbook.xml.rels 839
.rels 588
b.cpython-310.pyc 144
detect.txt 0
test.txt 5
demo.txt 0
新建文本文.txt 0'''
使用rglob()方法查找指定文件夹内最后修改时间早于指定日期的文件
from pathlib import Path
from datetime import datetime
p=Path(r'D:\Python\学习') #根据路径创建一个Path对象
#查找指定文件夹内修改时间早于2023年7月1日的文件
files=p.rglob('*.*') #将该文件价内所有文件地址Path对象存储成一个迭代器
for f in files:
s=f.stat()
dt=datetime.fromtimestamp(s.st_mtime) #将元素的最后修改日期的数字转换成正常的日期
if dt<datetime(2023,7,1,0,0,0): #如果文件的最后修改时间早于2023年7月1日0时0分0秒
print(f.name,dt)
'''
Python 3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.5.0 -- An enhanced Interactive Python. Type '?' for help.
PyDev console: using IPython 8.5.0
Python 3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)] on win32
runfile('D:/Python/学习/a.py', wdir='D:/Python/学习')
b.py 2023-03-28 08:03:40.251688
[Content_Types].xml 1980-01-01 00:00:00
app.xml 1980-01-01 00:00:00
core.xml 1980-01-01 00:00:00
sharedStrings.xml 1980-01-01 00:00:00
styles.xml 1980-01-01 00:00:00
workbook.xml 1980-01-01 00:00:00
printerSettings1.bin 1980-01-01 00:00:00
printerSettings2.bin 1980-01-01 00:00:00
theme1.xml 1980-01-01 00:00:00
sheet1.xml 1980-01-01 00:00:00
sheet2.xml 1980-01-01 00:00:00
sheet1.xml.rels 1980-01-01 00:00:00
sheet2.xml.rels 1980-01-01 00:00:00
workbook.xml.rels 1980-01-01 00:00:00
.rels 1980-01-01 00:00:00
b.cpython-310.pyc 2023-03-28 08:03:43.190802'''from pathlib import Path
from datetime import datetime
p=Path(r'D:\Python\学习') #根据路径创建一个Path对象
#查找指定文件夹内修改时间早于2023年7月1日的文件
files=p.rglob('*.*') #将该文件价内所有文件地址Path对象存储成一个迭代器
for f in files:
s=f.stat()
dt=datetime.fromtimestamp(s.st_mtime) #将元素的最后修改日期的数字转换成正常的日期
if dt<datetime(2023,7,1,0,0,0): #如果文件的最后修改时间早于2023年7月1日0时0分0秒
print(f.name,dt)
'''
Python 3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.5.0 -- An enhanced Interactive Python. Type '?' for help.
PyDev console: using IPython 8.5.0
Python 3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)] on win32
runfile('D:/Python/学习/a.py', wdir='D:/Python/学习')
b.py 2023-03-28 08:03:40.251688
[Content_Types].xml 1980-01-01 00:00:00
app.xml 1980-01-01 00:00:00
core.xml 1980-01-01 00:00:00
sharedStrings.xml 1980-01-01 00:00:00
styles.xml 1980-01-01 00:00:00
workbook.xml 1980-01-01 00:00:00
printerSettings1.bin 1980-01-01 00:00:00
printerSettings2.bin 1980-01-01 00:00:00
theme1.xml 1980-01-01 00:00:00
sheet1.xml 1980-01-01 00:00:00
sheet2.xml 1980-01-01 00:00:00
sheet1.xml.rels 1980-01-01 00:00:00
sheet2.xml.rels 1980-01-01 00:00:00
workbook.xml.rels 1980-01-01 00:00:00
.rels 1980-01-01 00:00:00
b.cpython-310.pyc 2023-03-28 08:03:43.190802'''
5.文件拷贝与编程思路
from pathlib import Path
import shutil
print('复制不同扩展名的文件到不同扩展名的文件夹')
root=Path(r'D:\Python\学习') #文件所处的目录
for f in root.rglob('*.*'): #遍历文件夹中的所有文件
p=root/f.suffix[1:] #根目录+文件扩展名拼接得到一个文件夹目录,[1:]是为了截取文件扩展名不包含小数点的部分
p.mkdir(exist_ok=True) #创建文件夹,设置exist_ok=True表示如果出现同名文件夹则自动处理,不设置该参数可能会报错
try:
shutil.copy(f,p) #把 f文件 拷贝到 p文件夹 中
#shutil模块的copy()方法,接收字符串作为参数,也接受Path对象作为参数
except shutil.SameFileError: #如果触发SameFileError就直接pass
passfrom pathlib import Path
import shutil
print('复制不同扩展名的文件到不同扩展名的文件夹')
root=Path(r'D:\Python\学习') #文件所处的目录
for f in root.rglob('*.*'): #遍历文件夹中的所有文件
p=root/f.suffix[1:] #根目录+文件扩展名拼接得到一个文件夹目录,[1:]是为了截取文件扩展名不包含小数点的部分
p.mkdir(exist_ok=True) #创建文件夹,设置exist_ok=True表示如果出现同名文件夹则自动处理,不设置该参数可能会报错
try:
shutil.copy(f,p) #把 f文件 拷贝到 p文件夹 中
#shutil模块的copy()方法,接收字符串作为参数,也接受Path对象作为参数
except shutil.SameFileError: #如果触发SameFileError就直接pass
pass
需要注意的是,在上面的代码中,程序拷贝完根目录中的文件后,还会前往程序创建的目标文件夹中进行文件操作,所以会触发异常
因为rglob()方法返回的是一个生成器,为了解决这个问题,可以先将rglob()返回的内容通过list()方法转换成列表,这样就是对列表中的内容进行循环,而列表一开始就包含了原始的文件目录内的每一个文件的路径,不会纳入新创建文件夹中的文件
改进后的代码如下:
from pathlib import Path
import shutil
print('复制不同扩展名的文件到不同扩展名的文件夹')
root=Path(r'D:\Python\学习') #文件所处的目录
src_files=list(root.rglob('*.*'))
for f in src_files:
p=root/f.suffix[1:]
print(f)
p.mkdir(exist_ok=True)
shutil.copy(f,p)from pathlib import Path
import shutil
print('复制不同扩展名的文件到不同扩展名的文件夹')
root=Path(r'D:\Python\学习') #文件所处的目录
src_files=list(root.rglob('*.*'))
for f in src_files:
p=root/f.suffix[1:]
print(f)
p.mkdir(exist_ok=True)
shutil.copy(f,p)
解决之前异常的另一个简单的方法是,将复制到的目标文件夹改成其他路径
此处为语雀视频卡片,点击链接查看:[2.8]–第八回 文件更名复制技巧及其在同名文件处理中的应用.mp4
6.文件的移动、更名,以及最新版文件的筛选方法
从一个文件夹内复制出所的xlsx文件到目标文件夹,如果存在同名文件,则保留修改日期最新的
#从一个文件夹中复制所有的xlsx文件到目标文件夹,如果存在同名文件,则保留最新修改的
'''大致的实现过程是,先创建一个空字典,然后搜索所有的xlsx文件,然后将xlsx文件名作为键,文件地址作为值'''
from pathlib import Path
import shutil
src_dir=Path(r'D:\Python\学习\新建文件夹')
tgt_dir=Path(r'D:\Python\学习\目标文件夹')
d={}
for f in src_dir.rglob('*.xlsx'):
#如果文件名不存在字典的键值中,或者文件的修改时间
if f.stem not in d.keys() or f.stat().st_mtime>d[f.stem].stat().st_mtime:
d[f.stem]=f #将文件名存储为字典的键,文件的Path对象存储为对应的值
for f in d.values():
shutil.copy(f,tgt_dir)#从一个文件夹中复制所有的xlsx文件到目标文件夹,如果存在同名文件,则保留最新修改的
'''大致的实现过程是,先创建一个空字典,然后搜索所有的xlsx文件,然后将xlsx文件名作为键,文件地址作为值'''
from pathlib import Path
import shutil
src_dir=Path(r'D:\Python\学习\新建文件夹')
tgt_dir=Path(r'D:\Python\学习\目标文件夹')
d={}
for f in src_dir.rglob('*.xlsx'):
#如果文件名不存在字典的键值中,或者文件的修改时间
if f.stem not in d.keys() or f.stat().st_mtime>d[f.stem].stat().st_mtime:
d[f.stem]=f #将文件名存储为字典的键,文件的Path对象存储为对应的值
for f in d.values():
shutil.copy(f,tgt_dir)
Path对象可以执行replace()方法,,可以将文件用的另一个地址并换上一个名字
需要注意的是,目标地址必须得加上新文件名的扩展名,否则会提示找不到文件
from pathlib import Path
f=Path(r'D:\Python\学习\新建文件夹\test.xlsx')
t=Path(r'D:\Python\学习\目标文件夹\replace.xlsx')
f.replace(t) #将t移动到t,并且修改名字from pathlib import Path
f=Path(r'D:\Python\学习\新建文件夹\test.xlsx')
t=Path(r'D:\Python\学习\目标文件夹\replace.xlsx')
f.replace(t) #将t移动到t,并且修改名字
将一个文件夹内(包括子文件夹)里的所有xlsx文件移动到一个新的文件夹中
from pathlib import Path
source=Path(r'D:\Python\学习\新建文件夹')
target=Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
f_tgt=target/f.name
f.replace(f_tgt)from pathlib import Path
source=Path(r'D:\Python\学习\新建文件夹')
target=Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
f_tgt=target/f.name
f.replace(f_tgt)
如果要将“移动”改为“复制”,可以使用以下代码:
from pathlib import Path
import shutil # 引入shutil库用于文件复制
source = Path(r'D:\Python\学习\新建文件夹')
target = Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
f_tgt = target / f.name
shutil.copy2(f, f_tgt) # 使用shutil.copy2来复制文件from pathlib import Path
import shutil # 引入shutil库用于文件复制
source = Path(r'D:\Python\学习\新建文件夹')
target = Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
f_tgt = target / f.name
shutil.copy2(f, f_tgt) # 使用shutil.copy2来复制文件
如果要移动所有的xlsx文件到一个新的文件夹,文件移动后,文件名还要加上它们之前所处文件夹的名字,可以使用以下代码:
from pathlib import Path
source=Path(r'D:\Python\学习\新建文件夹')
target=Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
#这行使用格式化字符串(f-string)生成新的文件名。f.stem 是文件名(不包括后缀),f.parent.stem 是文件的父文件夹
n=f'{f.stem}_{f.parent.stem}{f.suffix}'
f_tgt=target/n
f.replace(f_tgt)from pathlib import Path
source=Path(r'D:\Python\学习\新建文件夹')
target=Path(r'D:\Python\学习\目标文件夹')
for f in source.rglob('*.xlsx'):
#这行使用格式化字符串(f-string)生成新的文件名。f.stem 是文件名(不包括后缀),f.parent.stem 是文件的父文件夹
n=f'{f.stem}_{f.parent.stem}{f.suffix}'
f_tgt=target/n
f.replace(f_tgt)
Path对象的replace还可以实现文件的批量改名,
比如为文件夹内每个文件的名字加上它们的修改日期
from pathlib import Path # 导入Path类,用于创建和处理路径对象
from datetime import datetime # 导入datetime模块,用于处理日期和时间
source=Path(r'D:\Python\学习\新建文件夹') # 定义源文件夹路径
# 循环遍历源文件夹及其子文件夹中的所有文件
for f in source.rglob('*.*'):
# 获取文件的最后修改时间(以unix时间戳形式),并转换为datetime对象
ct=datetime.fromtimestamp(f.stat().st_mtime)
print(ct) # 打印文件的最后修改时间
# 根据文件的最后修改时间重命名文件,新的文件名格式为:原文件名_月份日数.后缀
n=f'{f.stem}_{ct.month}月{ct.day}日{f.suffix}'
f_tgt=f.parent/n # 定义新的文件路径,将新的文件名加入到原文件所在的文件夹中
f.replace(f_tgt) # 将原文件重命名为新的文件名from pathlib import Path # 导入Path类,用于创建和处理路径对象
from datetime import datetime # 导入datetime模块,用于处理日期和时间
source=Path(r'D:\Python\学习\新建文件夹') # 定义源文件夹路径
# 循环遍历源文件夹及其子文件夹中的所有文件
for f in source.rglob('*.*'):
# 获取文件的最后修改时间(以unix时间戳形式),并转换为datetime对象
ct=datetime.fromtimestamp(f.stat().st_mtime)
print(ct) # 打印文件的最后修改时间
# 根据文件的最后修改时间重命名文件,新的文件名格式为:原文件名_月份日数.后缀
n=f'{f.stem}_{ct.month}月{ct.day}日{f.suffix}'
f_tgt=f.parent/n # 定义新的文件路径,将新的文件名加入到原文件所在的文件夹中
f.replace(f_tgt) # 将原文件重命名为新的文件名
7.文件压缩与解压
Python自带zipfile模块,可以创建与读取zip文件,设置压缩密码以及zip包中特定文件的信息
ZipFile()可以创建一个压缩包对象,第一个参数要设置压缩包路径,还要设置mode参数,r表示读取(如果压缩包不存在会报错),w表示创建,a表示向压缩包内添加文件,x则表示以独占模式创建压缩包文件,如果文件已存在,将引发 FileExistsError。
ZipFile对象的write()方法可以向这个压缩包对象内添加文件
ZipFile对象在操作完毕后,需要关闭【对象.close()】
最简单最基本的用法:
from zipfile import ZipFile
zip_f=ZipFile(r'D:\Python\学习\新建文件夹\test.zip',mode='w')
zip_f.write(r'D:\Python\学习\新建文件夹\test.txt')
zip_f.close()from zipfile import ZipFile
zip_f=ZipFile(r'D:\Python\学习\新建文件夹\test.zip',mode='w')
zip_f.write(r'D:\Python\学习\新建文件夹\test.txt')
zip_f.close()
如果要将整个文件夹的文件添加到压缩文件(当然也可以通过设置比如*.xlsx只添加xlsx文件),可以先用Path对象的遍历文件夹功能,将每个文件逐一添加到zip对象中,最后不要忘记关闭zip对象
from zipfile import ZipFile
from pathlib import Path
zip_f=ZipFile(r'D:\Python\学习\新建文件夹\testa.zip',mode='w')
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)
zip_f.close()from zipfile import ZipFile
from pathlib import Path
zip_f=ZipFile(r'D:\Python\学习\新建文件夹\testa.zip',mode='w')
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)
zip_f.close()
默认情况下,zipfile模块只把指定文件弄成一个压缩包,压缩包的体积可能会比原来的文件还要打,但也可以指定压缩算法
可以在创建ZipFile()对象时,通过compression来设置压缩算法,最常用的算法编号为8,那就设置【compression=8】也可以写成【comression=ZIP_DEFLATED】,如果不写成数字,而是写预定义常量名,那么在最开始导入模块的那行代码中要写成类似于这样【from zipfile import ZipFile,ZIP_DEFLATED】
| 数字编号 | 预定义常量名 | 压缩算法 |
| 0 | ZIP_STORED | 不压缩,仅打包 |
| 8 | ZIP_DEFLATED | 最常用的zip压缩算法 |
| 12 | ZIP_BZIP2 | BZIP2算法,体积小但压缩速度慢 |
| 14 | ZIP_LZMA | LZMA算法,体积比bzip2更小,主要适用于7zip |
操作zipfile对象时经常忘了被关闭,导致文件没有保存或者被锁定,因此可以使用with结构的写法,自动执行close()操作。
from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
with ZipFile(r'D:\Python\学习\新建文件夹\with.zip',mode='w',compression=8) as zip_f:
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
with ZipFile(r'D:\Python\学习\新建文件夹\with.zip',mode='w',compression=8) as zip_f:
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)
代码中的 with 语句是 Python 的上下文管理协议,这种用法也被称为上下文管理器。上下文管理器允许你设置一段代码的前置和后置操作,比如在访问文件、网络连接或其他资源时,你可以确保无论什么情况,这些资源总是被正确关闭。
with 语句后面跟着一个表达式(在这个例子中是 ZipFile(…)),这个表达式需要返回一个实现了上下文管理协议的对象(也就是实现了 __enter__ 和 __exit__ 方法的对象)。ZipFile 类就实现了这个协议。
在 with 语句中的代码块被执行之前,会调用对象的 __enter__ 方法。在这个例子中,__enter__ 方法会打开一个 ZIP 文件。
在 with 语句中的代码块被执行之后,无论代码块是否正常完成或引发了异常,都会调用对象的 __exit__ 方法。在这个例子中,__exit__ 方法会关闭 ZIP 文件。这就确保了文件总是被正确关闭,即使在代码块中发生了错误。
所以,你的代码相当于以下的代码:
from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
zip_f = ZipFile(r'D:\Python\学习\新建文件夹\with.zip',mode='w',compression=8)
try: # 尝试执行一些操作
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)
finally: # 无论前面的操作是否成功,都执行关闭文件的操作
zip_f.close()from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
zip_f = ZipFile(r'D:\Python\学习\新建文件夹\with.zip',mode='w',compression=8)
try: # 尝试执行一些操作
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p)
finally: # 无论前面的操作是否成功,都执行关闭文件的操作
zip_f.close()
但是,使用 with 语句可以使代码更简洁,更易读,也更安全。
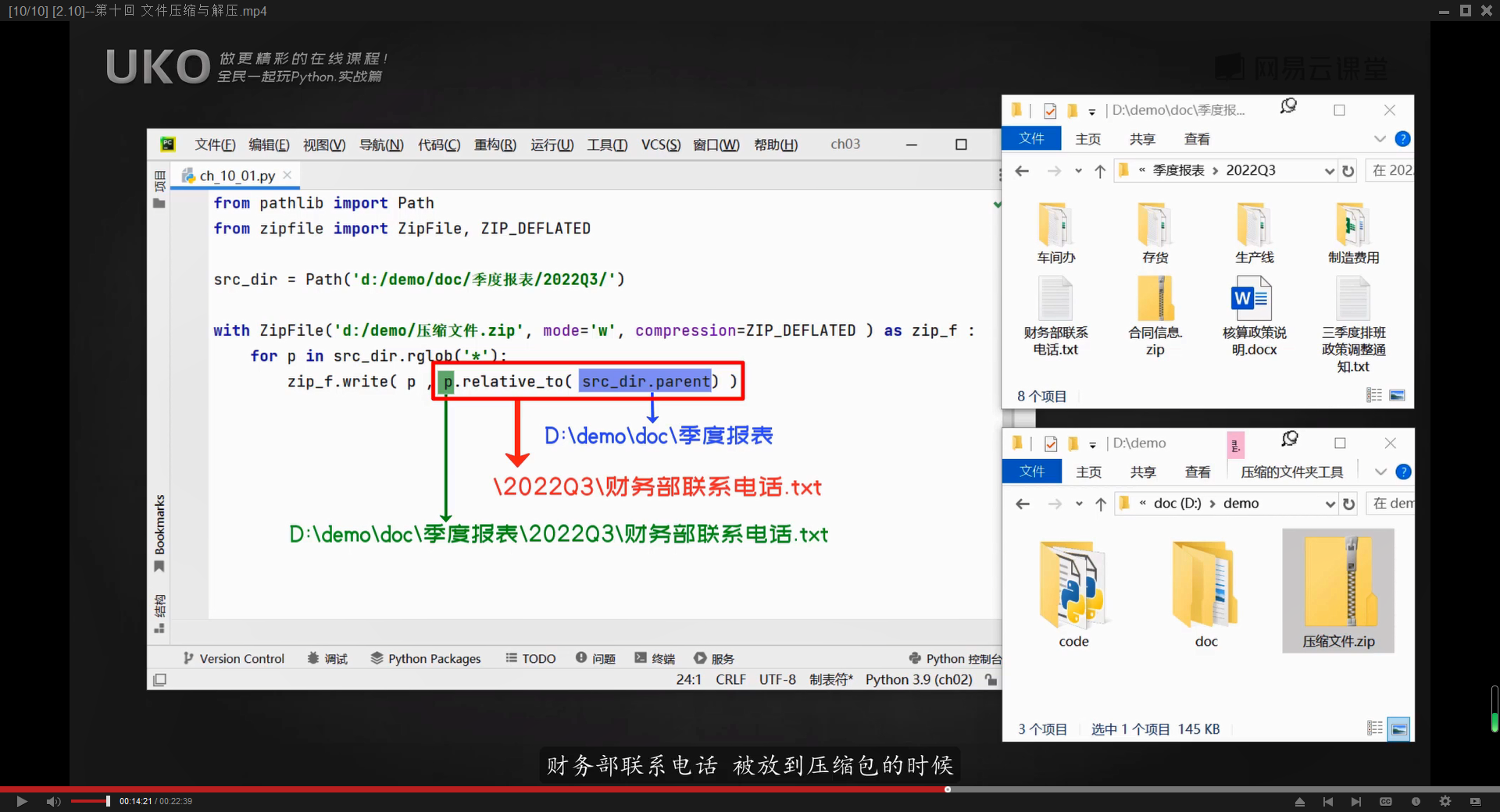
一般情况下,zipfile创建的压缩包,里面的的文件的路径,与它被压缩之前所处的文件路径一样,所以经常需要点开很多次文件夹草能找到压缩文件,这是因为,给压缩包对象里添加文件时,填写的是文件在资源管理器中所处的路径,这样压缩包内添加的,也是这个文件的路径。
只要往write()方法中添加一个新的参数就能解决这个问题
from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
with ZipFile(r'D:\Python\学习\新建文件夹\压缩文件.zip',mode='w',compression=8) as zip_f:
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p,p.relative_to(src_dir.parent)) #压缩文件路径.relative_to(根目录.parent)from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
with ZipFile(r'D:\Python\学习\新建文件夹\压缩文件.zip',mode='w',compression=8) as zip_f:
src_dir=Path(r'D:\Python\学习\目标文件夹')
for p in src_dir.rglob('*'):
zip_f.write(p,p.relative_to(src_dir.parent)) #压缩文件路径.relative_to(根目录.parent)
relateve_to()方法可以返回 一个路径对于另一个路径的相对路径
zipfile模块解压文件非常简单,只要【zip对象.extractall(‘解压路径’)】即可
Zip_File对象的namelist()方法可以返回一个列表,列表中会返回压缩包内所有文件和文件夹的路径的全名,
我们可以通过namelist()方法在不解压文件的时候就知道压缩包里的内容
ZipFile还有个read()方法可以直接读取压缩包内指定文件的内容,但读取txt文件,需要指定编码格式
压缩对象.read(‘文件路径’).decode(‘编码格式’),如果压缩文件带有密码,可以在read()方法中添加pwd=”参数设置压缩包密码
一个麻烦的地方时,zipfile模块解压自己创建的压缩包会正常,但是解压其他压缩软件创建的压缩包,解压出的文件的文件名可能会乱码,namelist()返回也是乱码,因为zipfile模块默认使用utf-8编码,而其他压缩软件可能使用压缩文件当时操作系统的编码
标准的zip文件,默认只支持CP437代码页,以及UTF编码,所以对于中文以及其他编码,解压出来就是乱码,因此我们想在namelist()中看见正确的文件名,就必须先试用CP437编码页,进行一个编码,然后,再使用中文编码方案比如GBK进行解码才行
from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
zf=ZipFile(r'D:\Python\学习\新建文件夹\压缩文件.zip')
for f in zf.namelist():
print(f.encode('cp437').decode('gbk'))from zipfile import ZipFile,ZIP_DEFLATED
from pathlib import Path
zf=ZipFile(r'D:\Python\学习\新建文件夹\压缩文件.zip')
for f in zf.namelist():
print(f.encode('cp437').decode('gbk'))
但上面的代码也仅仅是正常查看文件目录,如果想要按正常显示解压出来,可能就比较麻烦
zipfile的速度很慢,如果要操作大量文件,可以使用Python直接调用第三方工具进行解压
1 thought on “Python办公自动化【1】(文件的本质与文件操作)”