1.字符文本必须编成数字,回车换行都要转义表达
Python允许两个字符串之间比较大小,因为每个字符串都有各自对应的ASCII编码,比较两个字符串的大小就是用两个字符串各自的ASCII编码作比较。
print('a'<'b') #True
print('A'<"B") #True
print('1'<"3") #True
如果作比较的两个字符串有许多位,那么会进行逐位比较,也就是说,会比较两个字符串的第一位,如果第一位相同,再比较两个字符串的第二位,哪个字符串对象的第二位的字符编码数字大,哪个字符串就更大,如果两个字符串前两个字符相等,一个字符串只有两位,而另一个字符串位数更长,那么位数更长的字符串对象更大
在Claude看见的回答是:
“在Python中,字符串比较大小是根据Unicode代码点进行的,而不是ASCII码。Unicode和ASCII有以下区别:
- Unicode是国际标准,支持全球的所有语言字符,ASCII只支持128个英文字符。Unicode有多种编码方式,常用的有UTF-8和UTF-16。
- ASCII编码是1个字节,所以最多只能有256个字符。Unicode通常是2个字节或4个字节,所以可以代表的字符范围更广,理论上可以包含100多万个字符。
- ASCII只支持英文字符,不能表示中文、日文、阿拉伯文等字符。而Unicode支持全球范围内的所有语言。
- 在Python中,字符串使用Unicode编码,每个字符对应一个Unicode代码点。字符串比较是根据代码点的大小顺序进行的。
”
通过ord()函数,可以得到字符串的UNICODE值,该函数只接受单个字符串
chr()函数则相反,可以输入一个整数也就是UNICODE值,返回对应编码的字符串
将字典中的ABC值转换成1/2/3
scores={'张三':'A','王五':'B',"刘二":'C'}
print(ord('A'))#65
print(ord('B'))#66
print(ord('C'))#67
for name in scores:
scores[name]=ord(scores[name])-(ord('A')-1)
print(scores)
可以用chr(10)来表示换行
a='a'+chr(10)+"b" print(a) ''' a b '''
直接在字符串内部表示换行,可以用【\n】来表示换行符
转义字符也经常在字符串对象内表示单引号与双引号,分别是【\’】和【\”】
在Python中输入Window文件路径,也需要用\\来表示\,否则单个\会与后面的字符进行转义
| 转义字符 | 含义 |
| \’ | 单引号 |
| \” | 双引号 |
| \\ | 反斜杠 |
| \n | 换行 |
| \t | 水平制表符 |
| \r | 回车 |
| \b | 退格(删除前一个字符) |
| \f | 换页 |
| \ooo | 八进制数表示的字符 |
| \xhh | 十六进制数表示的字符 |
2.第二十一回:各国语言千军万码,Chardet 模块一目了然
通过Python读取txt文件,一般都需要指定编码格式,否则会按照系统默认的解码方式读取,中文操作系统下一般都是GB
GB18080是目前中国国标的最新版,并且兼容以往的GB2312以及GBK,还提供了更多的字符支持
旧版Windows在保存txt文件时,选择unicode编码,那么在Python中读取时,需要指定utf-16
Python中可以通过【chardet】第三方模块,来识别文件的编码格式,chardet是char detect的缩写
chardet的detect()函数会返回一个字典,字典中分别包含文件编码,置信度以及语言,置信度也就是fonfidence为1.0表示百分百置信度
借助chardet模块读取文件的流程:
1.不指定编码,直接读取文件
2.使用chardet模块的detect()函数检测读取内容的编码,得到一个字典,然后通过字典的encoding键的值得到编码格式
3.通过chardet得到的编码格式重新读取该文件
import chardet
file='1.txt'
with open(file,'rb') as f: #指定打开方式为rb,b是binary二进制的意思
s=f.read()
print(s) #b'1\r\n2\r\n3\r\n999999999999\r\n'
d=chardet.detect(s)
print(d) #{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
e=d['encoding'] #通过字典得到编码格式的字符串
if e.lower().startswith('gb'):
e='gb18030' #如果文件编码以gb开头,就统一使用gb18030这个目前最新的国标格式
with open(file,encoding=e) as f:
s=f.readlines()
for i in s:
print(i)
3.解读字符要看bytes对象,肃清乱码牢记八字真言
在Python中,encode() 方法用于将字符串编码为指定的字符集(如UTF-8、ASCII等)的字节序列。它的作用是将字符串转换为字节表示形式,以便在网络传输、存储或处理二进制数据时使用。
在Python中,decode() 方法用于将字节序列解码为字符串。它将字节表示形式转换为字符串形式,以便在文本处理、显示或其他操作中使用。
此处为语雀视频卡片,点击链接查看:[10.3]–第二十二回:解读字符要看bytes对象,肃清乱码牢记八字真言.mp4
a='大家好'
b=a.encode('gb18030')
print(b) #b'\xb4\xf3\xbc\xd2\xba\xc3'
print(list(b)) #[180, 243, 188, 210, 186, 195]
print(b.decode(('gb18030'))) #大家好
print(b.decode('utf-16')) #튼쎺
print(b.decode('big5')) #湮模疑
print(b.decode('utf-8')) #湮模疑 #UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb4 in position 0: invalid start byte
上一节的案例,代码可以精简成(s2=s.decode(e)):
import chardet
file='1.txt'
with open(file,'rb') as f: #指定打开方式为rb,b是binary二进制的意思
s=f.read()
print(s) #b'1\r\n2\r\n3\r\n999999999999\r\n'
d=chardet.detect(s)
print(d) #{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
e=d['encoding'] #通过字典得到编码格式的字符串
if e.lower().startswith('gb'):
e='gb18030' #如果文件编码以gb开头,就统一使用gb18030这个目前最新的国标格式
s2=s.decode(e)
print(s2)
#将任意不知道编码格式的txt文件转换成UTF-8格式
import chardet
file='某莫名其妙的文件'
with open(file,'rb') as f:
s=f.read()
d=chardet.detect(s)
e=d['encoding']
if e.lower().startswith('gb'):
e='gb18030'
s2=s.decode(e)
t=s2.encode('utf-8')
with open('已明其妙.txt','wb') as f:
f.write(t)
4.正则表达式推演千言万语,量词元字符匹配各种文章
正则表达式,英文全称是Regular Expresss,可以理解为用于描述语言的语言,可以实现灵活的文本处理
Python中使用正则表达式,可以import re
import re
text='asdhoaiud12312312sdf'
a=re.findall('正则表达式',字符串对象)
正则表达式可以像其他软件中的普通查找一样,按照指定字符查找内容
也可以设置特定的格式概念,来进行文本内容的的查找,带有【\】的表示方法可以成为元字符,比如【\d】
【\d】可以表示【一个数字字符】(而不是一个数字),如果查找连续的三位数字,可以写成【\d\d\d】,如果输入【0\d】,则表示查找0与另一个数字组合的数字,比如00、01、02等
正则表达式可以设置量词,可以表示连续出现N次,可以在某个元素后面加上花括号【{}】来表示,比如连续三个数字可以写成【\d{3}】,相当于【\d\d\d】
量词只能修饰它前面的一个元素
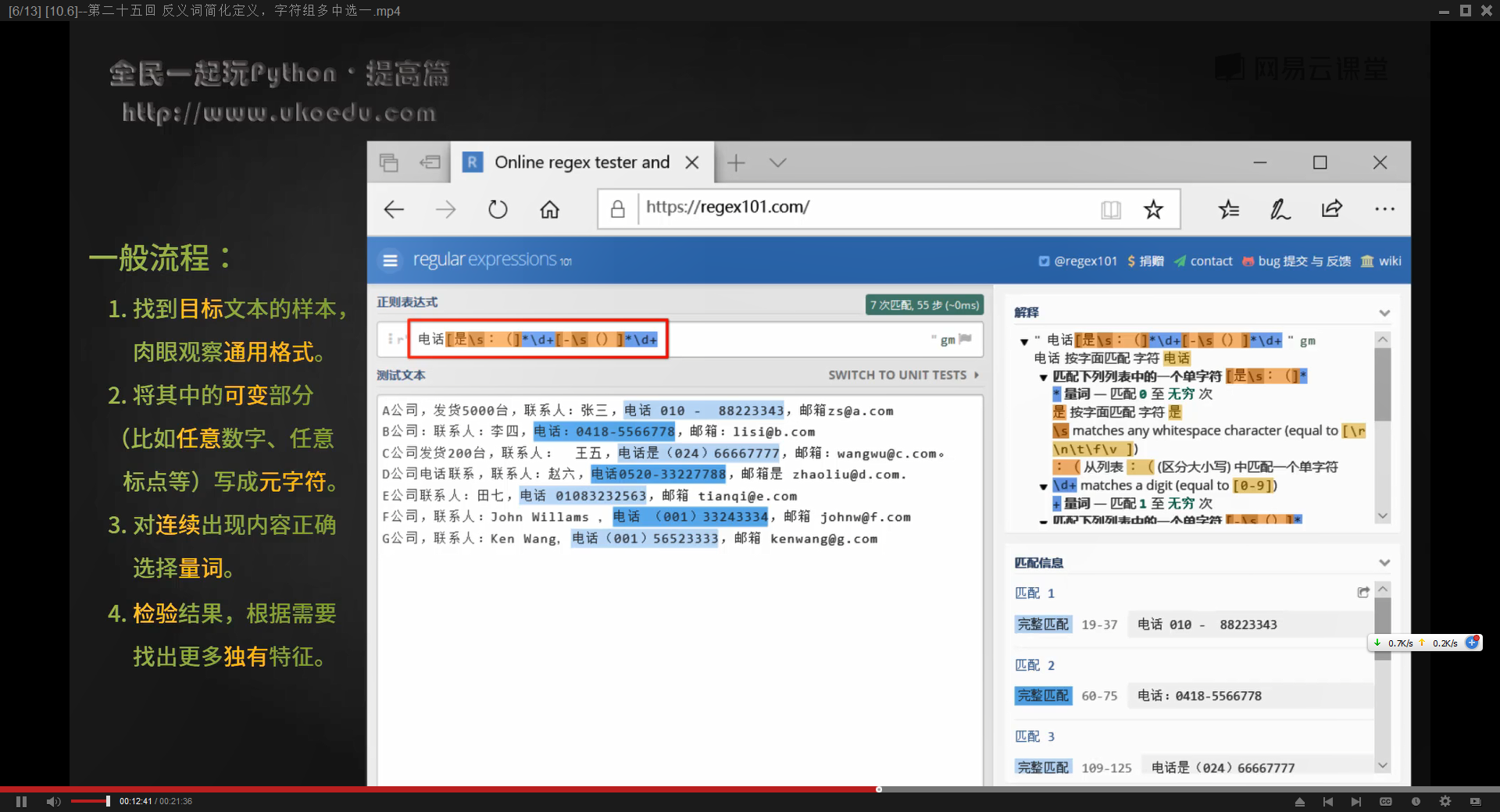
通过正则表达式查找一段文本中的所有电话号码
import re
text='123-456789 10086 北京市海淀区中关村南大街1号 456-789123 20000 上海市浦东新区陆家嘴环路8号 789-123456 510000 广州市天河区体育西路191号 234-567891 710000 西安市碑林区友谊西路127号 567-891234 610000 成都市武侯区人民南路四段27号 891-234567 530000 南宁市青秀区民族大道136号 345-678912 430000 武汉市江汉区解放大道686号 678-912345 310000 杭州市西湖区文一西路969号 912-345678 210000 南京市玄武区中山东路300号'
a=re.findall('\d{3}-\d{6}',text)
print(a) #['123-456789', '456-789123', '789-123456', '234-567891', '567-891234', '891-234567', '345-678912', '678-912345', '912-345678']
print(type(a)) #<class 'list'>
表示量词的{}里面可以填写两个参数,前一个参数表示最少连续的次数,后一个参数表示最多连续的次数,比如我要查找一段文本中所有的2位数与3位数,可以写成【\d{2,3}】,但在Python中,还要考虑到转义字符,所以\要写成\\
import re
text='5 45 673 8123 98147 9 2638 527 7462 4181 94 89261 782 65123 1 3579 623 82 2936 71846'
a=re.findall('\d{2,3}',text)
print(a) #不设置单词边界,会截取所有的符合条件的数字
#['45', '673', '812', '981', '47', '263', '527', '746', '418', '94', '892', '61', '782', '651', '23', '357', '623', '82', '293', '718', '46']
b=re.findall('\\b\\d{2,3}\\b',text) #设置了单词边界,还要考虑到转义字符,所以\要写成\\
print(b) #['45', '673', '527', '94', '782', '623', '82']
如果喜欢取消字符串对象内\的转义字符的效果,可以在字符串对象前面加上【r’】,比如上述代码可以改成【b=re.findall(r’\b\d{2,3}\b’,text)】
此外,花括号{}的第二个参数可以留空,表示最大长度没有限制
还需要注意的是,正则表达式匹配出来的结果,是互不重叠的
比如,用正则表达式【\d\d\d】来匹配【123456789】,可以得到【123】【456】【789】,但是包括【234】【456】等连续三位数字纳入匹配结果
5.量词匹配多多益善,正则引擎本性贪
如果想用正则表达式搜索连续出现一次或一次以上的字符,可以使用加号【+】,
比如搜索连续的数字,可以写成【\d{1,}】也可可以写成【\d+】,
为了避免歧义,使用+号的写法,正则表达式会使用“贪婪搜索”模式,如果某次匹配方案可以返回多个匹配结果,那就取最长的一个,比如用【\d+】来匹配233,理论上符合条件的返回结果也可以包含【2,3,3】,但返回的匹配结果却是【233】
与加号【+】类似,正则表达式还提供了问号【?】,用来代表指定元素不出现或出现一次(最多连续出现1次),相当于【字{0,1}】
需要注意的是,查找单个字符加上?,比如【\d?】,在查找结果中还会返回空字符串,因为?表示可有可无,【*】同样也会出现这种情况
星号【*】可以用来表示指定元素不出现或出现任意次数,相当于【字{0,}】
在实际应用案例中,如果要查找格式为000-000000的电话号码,可以写成【\d+-\d+】,但假如原始文本中的个别电话号码还包含空格,为了将含有空格的电话号码也给查找进来,可以写成【\d+ ?- ?\d+ 】,如果空格出现的次数不固定,也可以将问号替换成星号,写成【\d+ *- *\d+】
【\s】可以表示一个空白字符,比如空格、缩进、换行等
【\w】可以用来表示任意可以用来组成单词的字符,包括字母和数字等,但不包括标点符号空格等,在Python3中可以表示汉字、日文等
【.】可以表示任意字符(是否代表换行符要看是否设置了“单行模式”)
6.反义词简化定义,字符组多中选一
正则表达式中,【[]】可以表示一个字符集合,可以匹配里面的任意一个字符
[abc]可以用来表示a或者b或者c
[a-z]可以用来表示从a到z的所有小写字母
[a-zA-Z]可以表示a到z的所有大小写字母
[0-9a-z]查找0到9或者a到z的字符
[0-9]可以表示任意一个数字,相当于【\d】
[a-z][0-9]可以表示任意字母+数字的组合
[^abc]可以用来表示任何非abc的字符
[a-z]+可以表示连续的小写字母
[a-c]表示小写字母从a到c
如果要在字符集和中放入一个【-】号,应该将其放在方括号中的第一位,否则会报错,因为放在中间表示相邻两个字符之间的范围
在字符集合中,【+*:。】等没有特殊含义,只代表它们本身
截取一段X字符开始,Y字符结束之前的字符串,可以写成XXX[^y]+,表示XXX开始加上连续非y的字符串
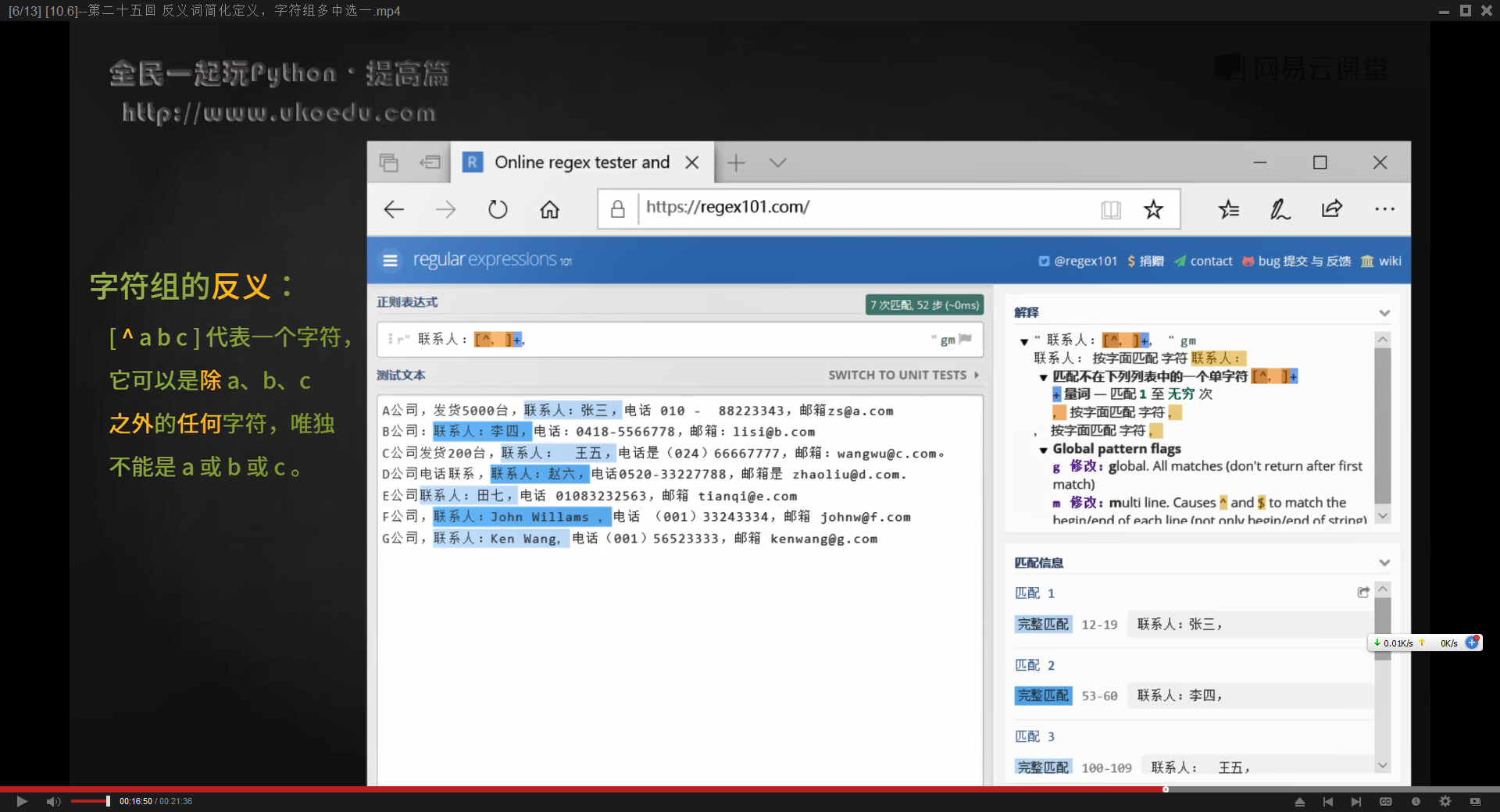
提取一段中文中的句子,不包含标点,可以写成:
[^,。!?:、“”]+
上述写法表示查找连续出现的字符,但这些字符不包含上述的集合中的标点符号
需要注意的是,只有当【^】出现在方括号中的第一个位置,才有not的含义,否则只能代表一个普通字符
\D 反斜杠加上大写D可以表示所有非数字的字符,相当于[^0-9]
\S 反斜杠加上大写S表示所有非空白字符(空格、换行等)
\W 表示所有非文字的任意字符
需要记住的是,一个方括号无论多长都只代表一个字符
7.加问号实现懒惰搜索,捕获组抽取局部信息
此处为语雀视频卡片,点击链接查看:[10.7]–第二十六回 加问号实现懒惰搜索,捕获组抽取局部信息.mp4
英文括号或者说半角圆括号【()】可以用来捕获,用英文括号将正则表达式中的某一部分括起来,该部分就会作为一个捕获结果单独返回
一个正则表达式可以有多个捕获组,设置了捕获组后,除了返回正则表达式完整的匹配结果,捕获组内的内容也会被作为一个结果返回
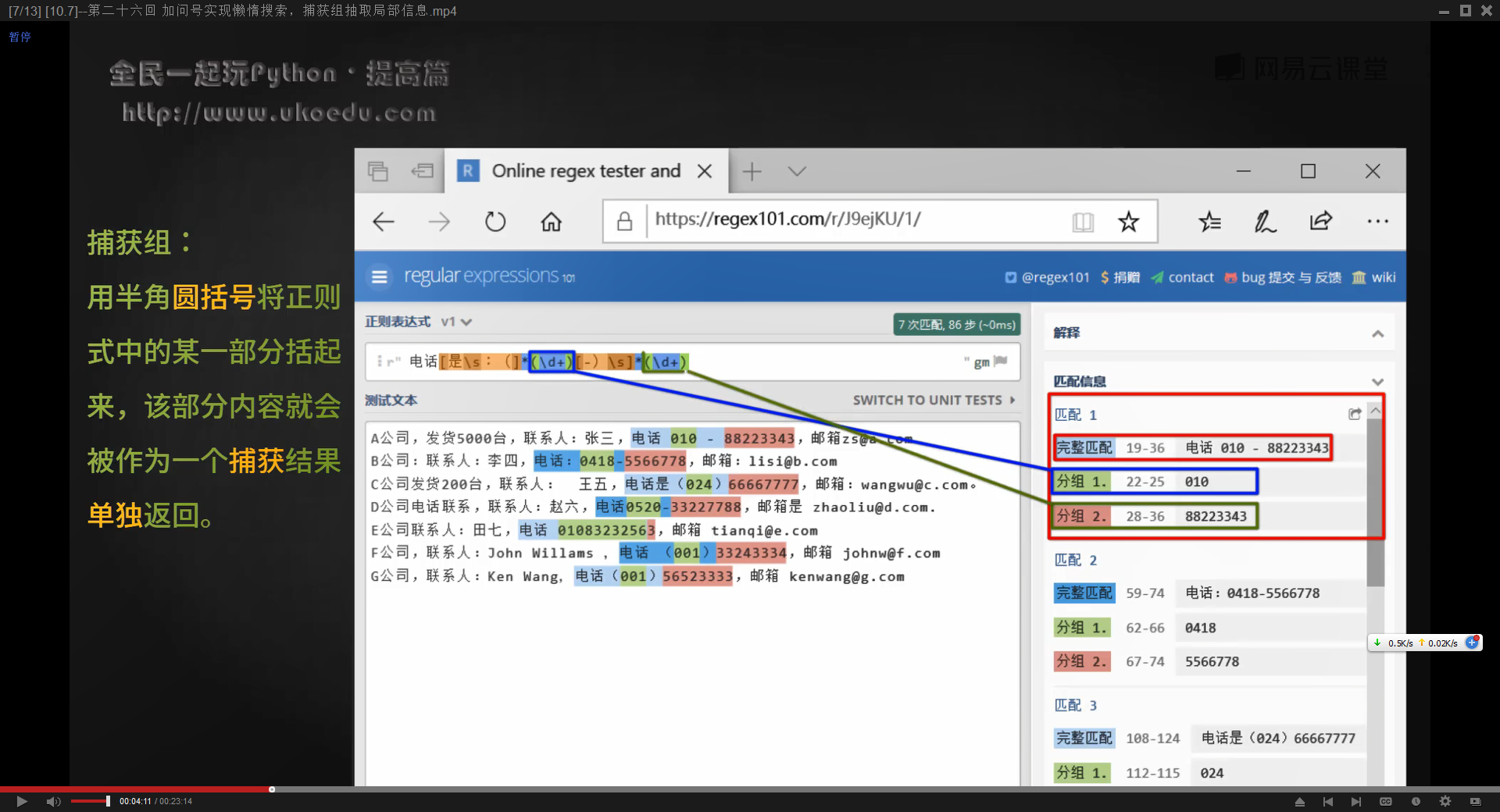
如果在Python中使用捕获组,它的用法与普通正则表达式相同,但是在re.findall()方法返回的列表中,只包含捕获组的内容而不包含其他位置的匹配字符
如果正则表达式内只有一个捕获组,那么会返回一个列表,列表中每个元素(字符串)对应每个捕获组的内容
如果正则表达式中有多个捕获组,则返回结果的列表中,每一项都是一个元组,每个元组内,包含正则表达式中各个捕获组的内容(字符串)
Python中3个单引号的组合,可以用来放置多行字符串【s=”’包含换行的大段文本内容”’】,这种写法也常被称作注释语句
import re
#text='5 45 673 8123 98147 9 2638 527 7462 4181 94 89261 782 65123 1 3579 623 82 2936 71846'
text='北京市海淀区中关村南大街1号 456-789123 20000 上海市浦东新区陆家嘴环路8号 789-123456 510000 广州市天河区体育西路191号 234-567891 710000 西安市碑林区友谊西路127号 567-891234 610000 成都市武侯区人民南路四段27号 891-234567 530000 南宁市青秀区民族大道136号 345-678912 430000 武汉市江汉区解放大道686号 678-912345 310000 杭州市西湖区文一西路969号 912-345678 210000 南京市玄武区中山东路300号'
a=re.findall(r'\d+-(\d+)',text)
print(a) #['789123', '123456', '567891', '891234', '234567', '678912', '912345', '345678']
a=re.findall(r'(\d+)-(\d+)',text)
print(a) #[('456', '789123'), ('789', '123456'), ('234', '567891'), ('567', '891234'), ('891', '234567'), ('345', '678912'), ('678', '912345'), ('912', '345678')]
for 区号,本地号 in a: #解包
print(区号,本地号)
'''
456 789123
789 123456
234 567891
567 891234
891 234567
345 678912
678 912345
912 345678'''
由于贪婪搜索会返回所有匹配结果中最长的一个,因此使用时需要格外注意,比如,提取一段文本中所有放在书名号中的文本,新手第一反应可能写成《(.*)》,但是却会发现返回结果中,起点是一本书的左书名号,终点是另一本书的右书名号
所以正确的写法应该是《[^》]*》,也就是被书名号包含的 不包含右书名号的连续字符
import re
text='''
在那个周末的黄昏,我坐在图书馆的角落,沉浸在书香的海洋中。我四处张望,目光扫过书架上排列整齐的各种书籍,我看到了一些熟悉的书名。
首先映入眼帘的是《百年孤独》,马尔克斯的魔幻现实主义巨作,每一个读过的人都会被他创造的世界深深吸引。紧接着,我看到了《红楼梦》,它是中国古代四大名著之一,人物性格鲜明,情节丰富,充满了人生的哲理。
我注意到了《活着》,余华的作品让人深思,讲述了一个普通人在生活中的苦难和坚韧。我也看到了《三体》,刘慈欣的科幻小说给读者带来了全新的宇宙视野和人类未来的深刻思考。
此外,还有许多其他值得一读的书籍,《白鹿原》、《围城》、《哈利·波特》系列、《挪威的森林》、《骆驼祥子》、《简爱》、《1984》、《哈姆雷特》……每一本书都像一个新的世界,等待着我去探索。
我拿起一本《悲惨世界》,准备沉浸在雨果创造的那个时代,感受其中的人性光辉与社会的黑暗。在阅读的过程中,我体验到了另一个生活,感受到了书中人物的喜怒哀乐。
书是知识的海洋,是智慧的灯塔。每当我走进这个世界,我都会深深地感到,我们可以通过阅读,了解这个世界,理解自己,也能更好地理解他人。这个世界是如此广阔,而书就是我们的指南,引导我们去探索和认识。
'''
a=re.findall(r'《.*》',text)
print(a) #['《百年孤独》,马尔克斯的魔幻现实主义巨作,每一个读过的人都会被他创造的世界深深吸引。紧接着,我看到了《红楼梦》', '《活着》,余华的作品让人深思,讲述了一个普通人在生活中的苦难和坚韧。我也看到了《三体》', '《白鹿原》、《围城》、《哈利·波特》系列、《挪威的森林》、《骆驼祥子》、《简爱》、《1984》、《哈姆雷特》', '《悲惨世界》']
a=re.findall(r'《[^》]*》',text)
print(a) #['《百年孤独》', '《红楼梦》', '《活着》', '《三体》', '《白鹿原》', '《围城》', '《哈利·波特》', '《挪威的森林》', '《骆驼祥子》', '《简爱》', '《1984》', '《哈姆雷特》', '《悲惨世界》']
a=re.findall('《([^》]*)》',text) #['百年孤独', '红楼梦', '活着', '三体', '白鹿原', '围城', '哈利·波特', '挪威的森林', '骆驼祥子', '简爱', '1984', '哈姆雷特', '悲惨世界']
print(a)
由于上述写法显得有些复杂,正则表达式又提供了懒惰搜索,在量词【*+?{}】后面加上问号【?】时,如果有多个匹配结果,返回最短的那一个匹配结果
上述案例中,也可以写成《.*?》,在星号后面加上问号,找到第一个也就是最短的一个匹配结果后,就返回,但这种写法在某些情况下也会出现意想不到的错误,返回错误的匹配结果
8.反斜线上转义来,今日方知我是我
此处为语雀视频卡片,点击链接查看:[10.8]–第二十七回 反斜线上转义来,今日方知我是我.mp4
由于正则表达式中的一些字符有特殊的含义,如果只想利用正则表达式查找该字符本身的内容,就涉及到正则表达式内部的转义,
在Python中,转义字符是反斜线【\】,在正则表达式中亦是如此,只需要在特殊含义的字符前加上反斜线【\】,后面的符号就只代表它本身
正则表达式中合法的语句,放到Python中又可能不合法,因为可能涉及到字符串的转义并且导致混乱
在正则表达式中【\b】是一个特殊的元字符,用于表示单词边界,它可以用来匹配单词开始和结束的位置,又称“单词分界线”,即一边是文字字符,另一边是非文字字符(如空格)的位置,它的返回结果是空字符串
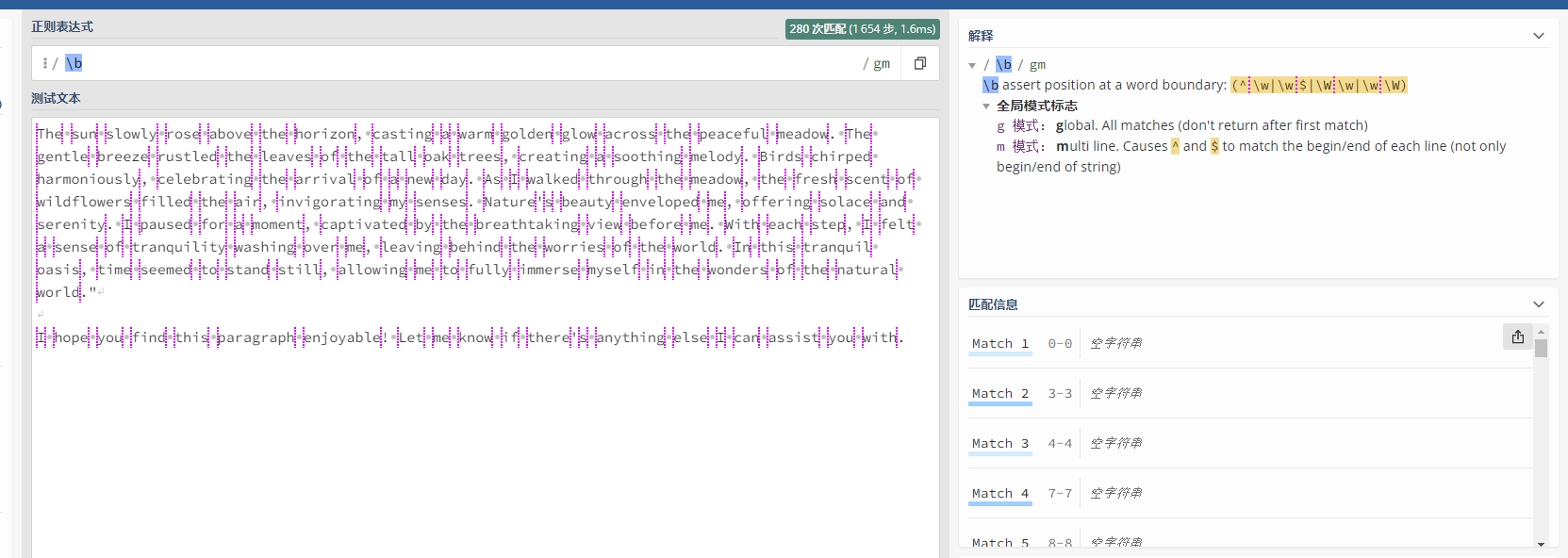
利用这个特性,如果想要提取标点符号(含空格)之间的文本内容,正则表达式就可以写成【\b\w+\b】,尤其是一段英文文本中,就直接提取出了全部的英文单词
为字符串对象的单引号前面加上【r】,可以让该字符串对象中的反斜线【\】失去转义功能
需要注意的是,如果使用了【r】,反斜线【\】不能出现在字符串中最后一个位置,否则会引发Python的报错
另一个需要知道的点是,就算使用了【r】,但如果Python中的字符串对象以双引号【””】作为开始和结束,然后如果正则表达式中出现了双引号,还是需要在双引号前面加上反斜线,写成【\”】
import re #text='5 45 673 8123 98147 9 2638 527 7462 4181 94 89261 782 65123 1 3579 623 82 2936 71846' text=''' The sun slowly rose above the horizon, casting a warm golden glow across the peaceful meadow. The gentle breeze rustled the leaves of the tall oak trees, creating a soothing melody. Birds chirped harmoniously, celebrating the arrival of a new day. As I walked through the meadow, the fresh scent of wildflowers filled the air, invigorating my senses. Nature's beauty enveloped me, offering solace and serenity. I paused for a moment, captivated by the breathtaking view before me. With each step, I felt a sense of tranquility washing over me, leaving behind the worries of the world. In this tranquil oasis, time seemed to stand still, allowing me to fully immerse myself in the wonders of the natural world. ''' a=re.findall(r'\b\w+\b',text) #为字符串对象的单引号前面加上【r】,可以让该字符串对象中的反斜线【\】失去转义功能 print(a) #['The', 'sun', 'slowly', 'rose', 'above', 'the', 'horizon', 'casting', 'a', 'warm', 'golden', 'glow', 'across', 'the', 'peaceful', 'meadow', 'The', 'gentle', 'breeze', 'rustled', 'the', 'leaves', 'of', 'the', 'tall', 'oak', 'trees', 'creating', 'a', 'soothing', 'melody', 'Birds', 'chirped', 'harmoniously', 'celebrating', 'the', 'arrival', 'of', 'a', 'new', 'day', 'As', 'I', 'walked', 'through', 'the', 'meadow', 'the', 'fresh', 'scent', 'of', 'wildflowers', 'filled', 'the', 'air', 'invigorating', 'my', 'senses', 'Nature', 's', 'beauty', 'enveloped', 'me', 'offering', 'solace', 'and', 'serenity', 'I', 'paused', 'for', 'a', 'moment', 'captivated', 'by', 'the', 'breathtaking', 'view', 'before', 'me', 'With', 'each', 'step', 'I', 'felt', 'a', 'sense', 'of', 'tranquility', 'washing', 'over', 'me', 'leaving', 'behind', 'the', 'worries', 'of', 'the', 'world', 'In', 'this', 'tranquil', 'oasis', 'time', 'seemed', 'to', 'stand', 'still', 'allowing', 'me', 'to', 'fully', 'immerse', 'myself', 'in', 'the', 'wonders', 'of', 'the', 'natural', 'world']
9.括号分组有 “复” 同享,多行模式首尾分明
正则表达式中,+号可以表示至少出现一个或连续的对象,如果想要表示一组对象连续出现多次,可以将要连续出现多次的对象放入圆括号()内,然后后面写上加号【+】
比如【(123)+】可以匹配出123,也可以匹配出123123、123123123等
圆括号另一个常用功能是文本的捕获,就是在匹配到的搜索结果中只截取里面的一部分返回,在一个匹配结果里,即使一对括号能匹配多段内容,但也会只会保留最后一个匹配结果,作为这个捕获组的结果
也就是说,正则表达式中,写了几个圆括号,返回结果中,就会得到几个捕获组
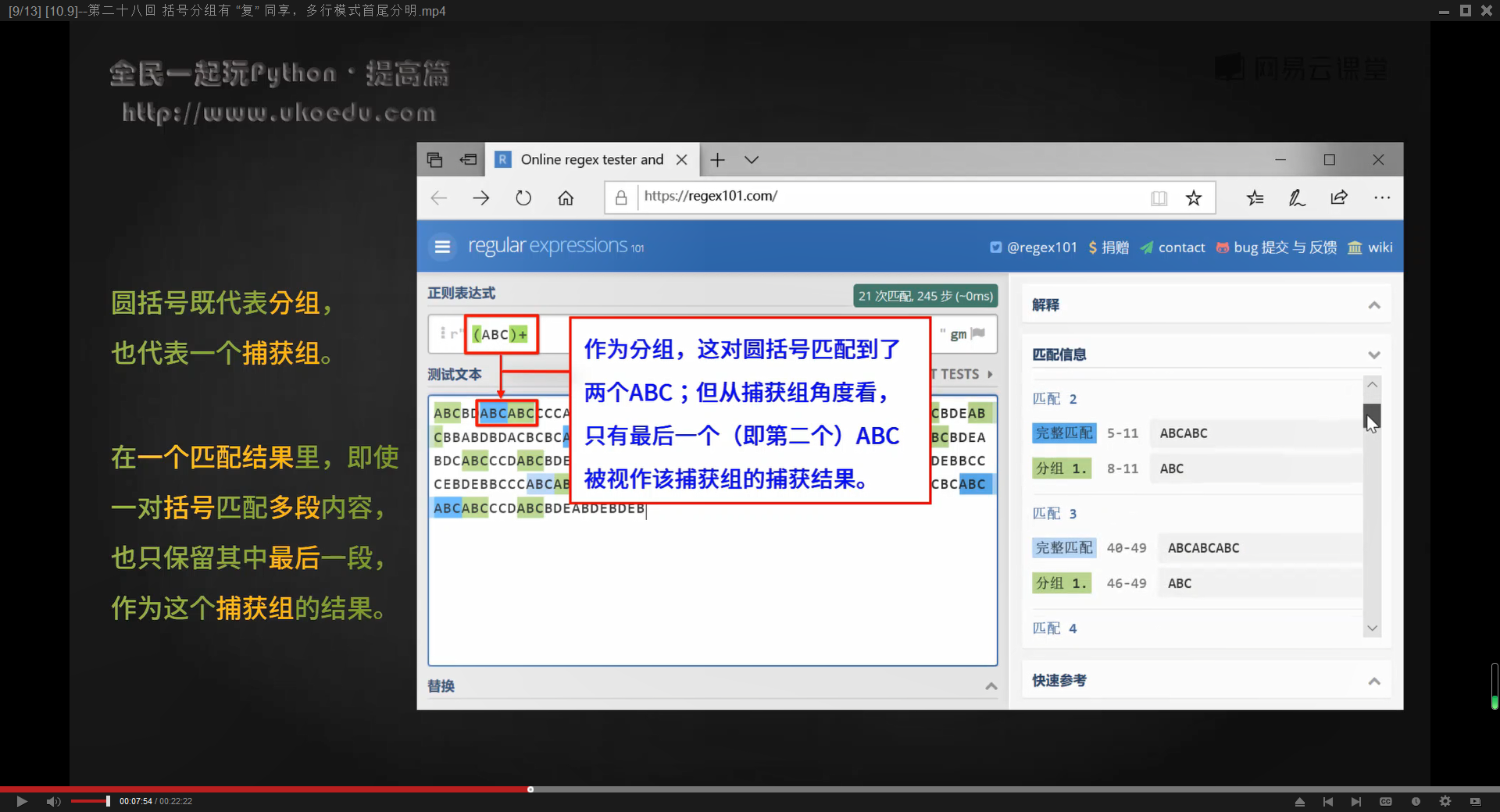
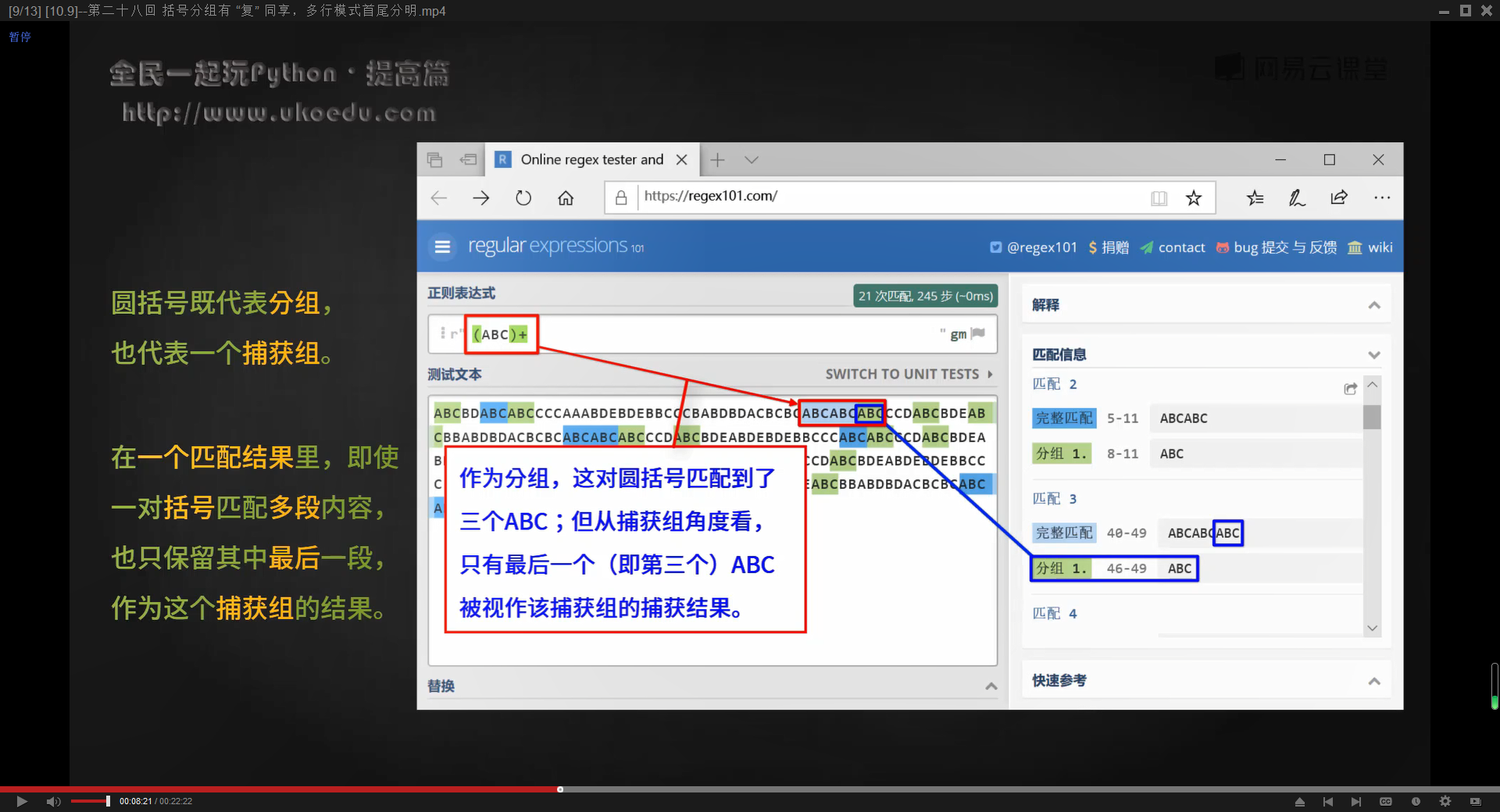
由于()在Python中既可以代表捕获组,也可以代表分组,如果正则表达式中设置了【()】作为捕获组,那么在Python的re模块中,返回的列表里只有捕获组的内容
可以消除()的捕获组功能,让它实现分组,需要在()内的开头写上【?:】,比如(?:abc)
import re
text='''
abcabcdeabcasabcabcabc'''
a=re.findall('(abc)+',text)
print(a) #['abc', 'abc', 'abc']
a=re.findall('(?:abc)+',text)
print(a) #['abcabc', 'abc', 'abcabcabc']
正则表达式中【^】代表行首位置,【$】代表行尾位置,有一个前提是,被匹配的文本必须是多行模式,否则【^】代表整个文本对象的起始位置【$】代表整个文本对象的结尾位置(默认)
在Python的re模块中,要将被匹配的文本对象设置为多行模式,要在re.findall()中加入一个参数【re.MULTILINE】,比如【a.findall(r’^\s*\w{5},\s*\w{5}。\s*$’,text,re.MULTILINE)】
通过正则表达式来匹配一段文本中的五言绝句:^\s*\w{5},\s*\w{5}。\s*$
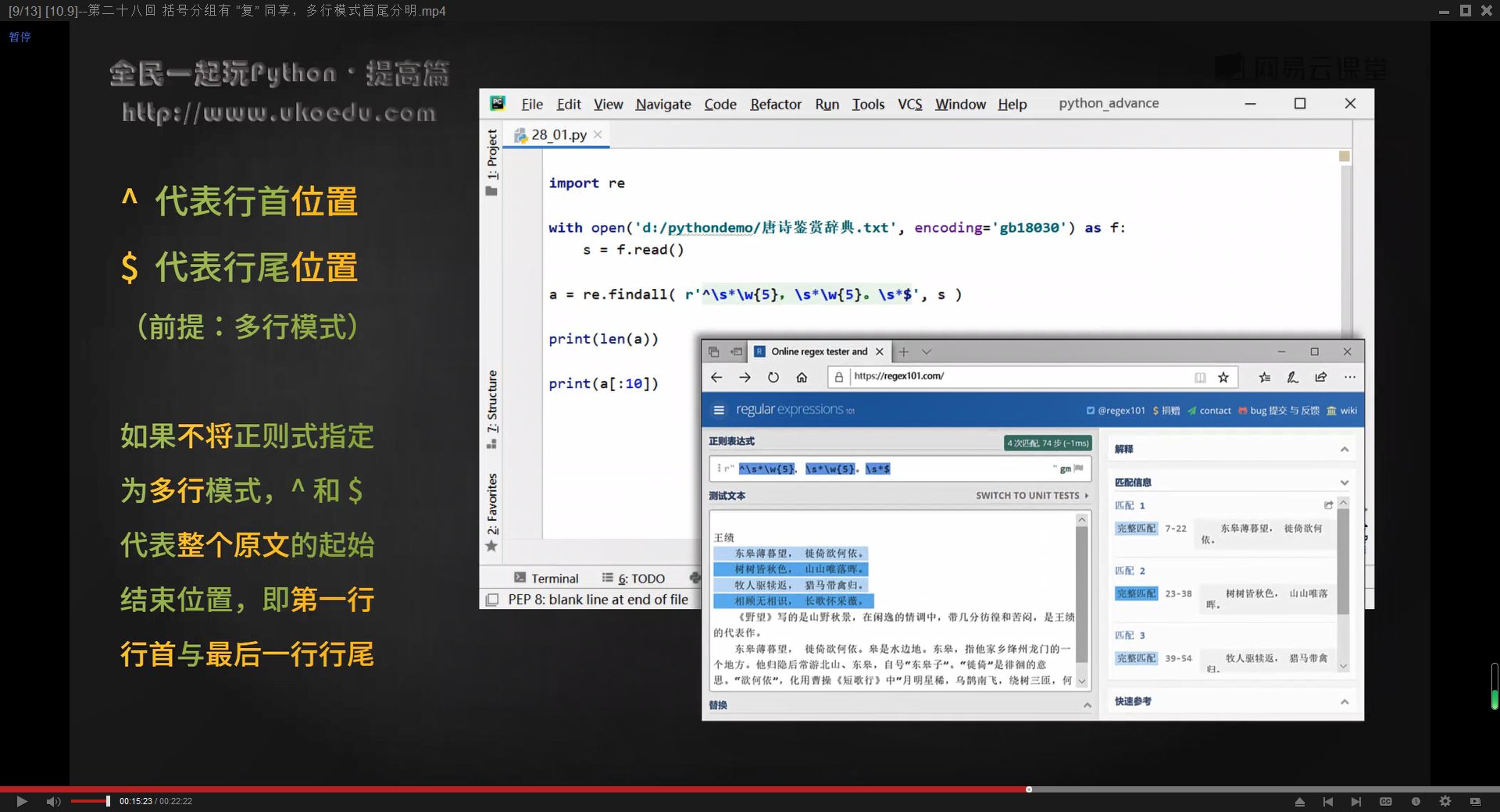
re模块中的常用匹配模式
| 完整性是 | 简写形式 | 含义与用途 |
| re.ASCII | re.A | 让\w\W\b\B\d\D\s\S仅匹配ASCII字符,而不匹配unicode字符(比如中文) |
| re.IGNORECASE | re.L | 忽略大小写,比如[A-Z]也会匹配小写字符 |
| re.MULTILINE | re.M | 多行模式,^和$代表每一行的行首和行尾 |
| re.DOTALL | re.S | 单行模式,即点号【.】可以匹配换行符 |
前面的代码中,只能匹配出示例文本中的诗句,如果要将整首诗作为结果返回,可以将诗句作为一个对象,然后通过正则表达式搜索连续的诗句,需要注意的是,这种情况下,每一行诗句的结尾,还有一个换行符【\n】
所以用正则表达式匹配出一整首诗,写法是:(?:^\s*\w{5},\s*\w{5}。\s*$\n)+
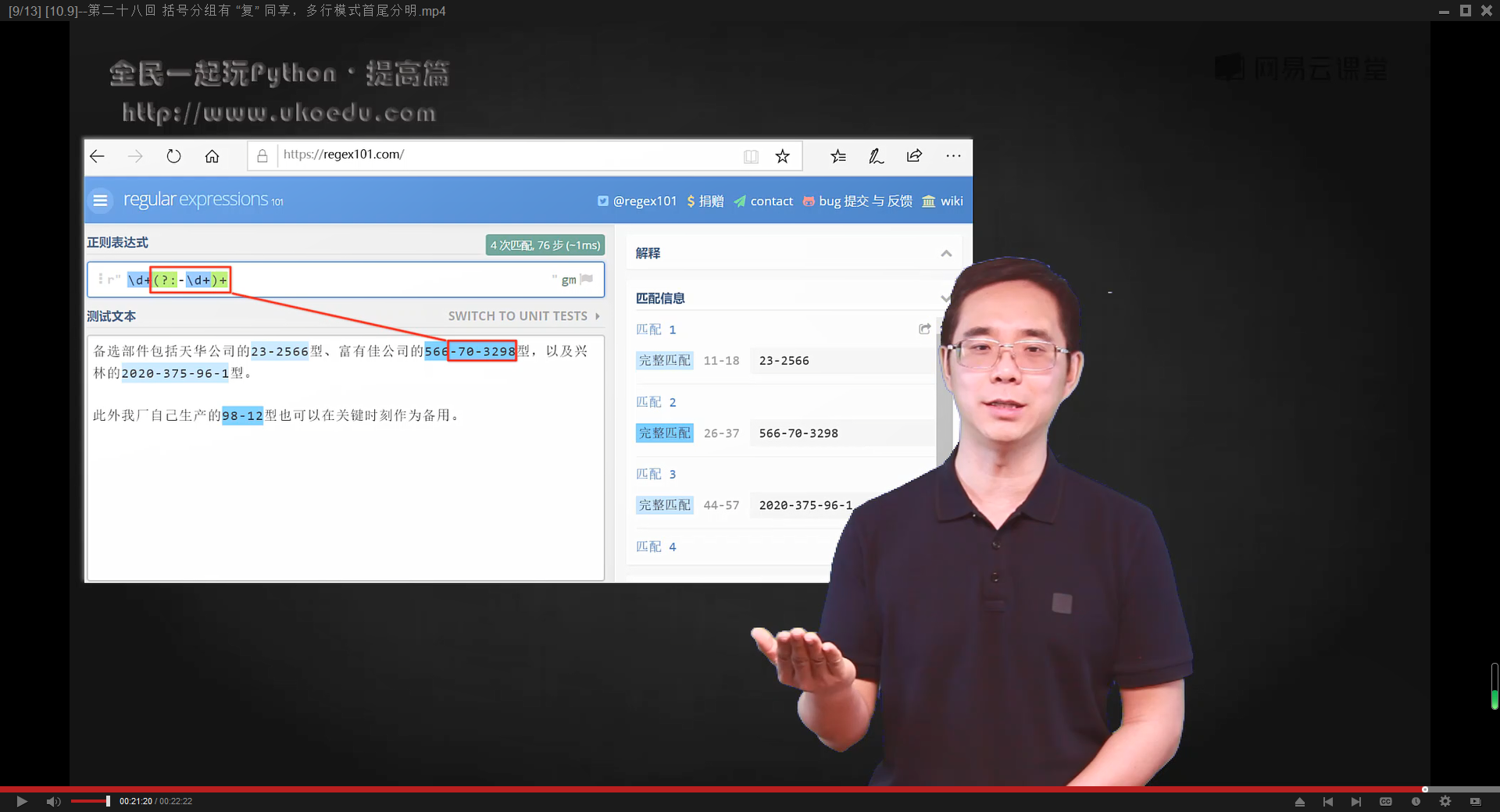
通过正则表达式匹配一段文本中的产品型号(产品型号格式是:连续数字-连续数字-连续数字):
\d+(?:-d+)+
10. 单行模式只管小数点,网抓图片仍是字节流
此处为语雀视频卡片,点击链接查看:[10.10]–第二十九回 单行模式只管小数点,网抓图片仍是字节流.mp4
正则表达式中,【|】符号可以表示“或者”,也就是说,它会匹配左边或右边的表达式,可以在分组中使用它
比如,【a|b】可以匹配a或b,【(tool|match|finder)】可以匹配出tool、match、finder,【gr(a|e)y】可以匹配出gray或者grey。
11.环视上下文精确定位,正则配循环所向无敌
此处为语雀视频卡片,点击链接查看:[10.11]–第三十回 环视上下文精确定位,正则配循环所向无敌.mp4
正则表达式可以实现环视,也就是匹配到符合条件的结果后,观察其前面与后面是否也符合要求,如果符合就返回结果,类似于匹配一段内容后再截取想要的内容
可以在匹配结果后面加上【(?=后面的内容)】
比如有,从一大堆数字中(123,123%,23.233%),提取百分数但不包含百分号,可以写成【\d+\.\d+(?=%)】或者【[.\d]+(?=%)】
其中【\.】是对小数点进行转义,让小数点只匹配小数点,
在方括号[]中,特殊字符会失去特殊意义,比如方括号中的小数点【.】仅代表小数点,此外,方括号中内的字符类没有顺序要求,只要存在方括号内的元素都会被匹配
环视分类
| 顺序肯定型 | (?=匹配结果后面必须是什么) |
| 顺序否定型 | (?!匹配结果后面禁止什么内容) |
| 逆序肯定型 | (?<=匹配结果前面必须是什么) |
| 逆序否定型 | (?<!匹配结果前面不能是什么内容) |
因此,如果前面的例子中,找出非百分比的数字,可以写成【[.\d]+(?![\d%.])】,注意,不仅仅是把【?=】改成【?!】这么简单,而是设置匹配结果后面不能是百分号小数点或者数字,否则会匹配出23.233%中的23.23
顺序和逆序可以搭配起来使用,比如:
(?<=\.)\d+(?=%) 找出介于小数点与百分号之间的数字
逆序环视内不能写入加号星号等表示量词的字符,顺序环视则可以使用,逆序环视要写在左边,顺序环视写在右边
12.有Word之替换,无案牍之劳形
此处为语雀视频卡片,点击链接查看:[10.12]–第三十一回 有Word之替换,无案牍之劳形.mp4
可以通过正则表达式,实现文本的替换,甚至对原始的文本结构进行重新排序
如果要进行排序,那么要被更改顺序的部分要用括号括起来,从左往右数,第一个左括号内的内容为编号1,第二个左括号的内容为编号2,然后在替换内容的地方,输入反斜杠加编号,比如【\1】代表编号1,用英文逗号隔开,替换的内容中也能穿插进自定义的内容
比如,原始文本为【+21-1314】,正则表达式写成【\+(\d+)-(\d+)】,替换的内容写成【\2,\1】,替换的结果就是【+21-1314】
Python中的re模块,替换的函数是sub(),该函数有3个必选参数,第一个参数是要查找的内容,第二个参数是替换内容,第三个参数是原始文本对象,还有2个可选参数,count表示限制替换的次数,flags参数用于指定正则表达式的匹配模式(多行模式/单行模式/全局模式等)
sub()函数不会修改原始的字符串对象,而是返回一个修改后的结果作为一个新的字符串返回
还需要注意的是,由于正则表达式中会写入转义字符,因此要在字符串对象前面加入r或者把\写成\\
import re
# 替换所有匹配的字符串
print(re.sub('abc', '123', 'abc abc abc')) # 输出:123 123 123
# 只替换前两个匹配
print(re.sub('abc', '123', 'abc abc abc', count=2)) # 输出:123 123 abc
13.反向引用代表重复,Python正则功能良多
此处为语雀视频卡片,点击链接查看:[10.13]–第三十二回 反向引用代表重复,Python正则功能良多.mp4
正则表达式可以反向引用,比如,用于查找两个重复出现的字符
(\w)\1 后面的【\1】表示1号捕获组的内容,首先将一个字符放入捕获组,然后匹配捕获组的内容以及1号捕获组的内容,相当于两个连续的重复的字符
通过正则表达式查找一段英文文本中,相同字母开始与结束的单词【\b(w)\w+\1\b】
查找重复出现的标点符号【(\W)\1】,正则表达式中,【\W】表示非单词字符
查找并替换重复出现的标点符号,比如将两个句号替换成1个句号,可以查找【(\W)\1】,然后替换成【\1】
Python中的re模块常用函数
findall 查找所有符合正则式的字符串
sub 执行正则表达式替换功能
search 查找第一个符合正则式的字符串(返回一个match对象)
match 检查字符串前端是否符合正则式,或者说开头的字符是否符合正则表达式的匹配,不匹配会返回None
compile 预编译正则式以提高效率
Pattern对象 代表一个正则式,可执行各种操作
Match对象 代表一个匹配结果,可用各种方法解读
import re text=''' 123,123%,23.233%''' a=re.search(r'\d+',text) print(a) #<re.Match object; span=(1, 4), match='123'>
import re text='''123,123%,23.233%''' a=re.match(r'\d+',text) print(a) #<re.Match object; span=(0, 3), match='123'>
match应用案例,判断网站注册页面用户输入的用户名是否合法,要求只能包含:小写字母、数字、逗号、点号、下划线
#只能在单行模式的情况下使用
import re
user_name=input('请输入用户名')
m=re.match(r'^[a-z\d,_、]+$',user_name) #【^】与【$】分别代表字符串的开头和结尾
if m:
print('用户名可以使用')
else:
print('用户名不合法')
https://www.yuque.com/llj2/it/pioy92mbp3xytmqn?singleDoc# 《全民一起玩Python【3】(字符串与正则表达式)》