1.随机抽样只需一个函数,列表排序可以自定规则
for循环语句只能读取元素,而不适用于修改被循环的对象里的内容
比如一下例子中,列表元素保持不变
price=[100,200,300]
for i in price:
i=i*7
print(price) #依然是[100,200,300]
可以通过while循环来修改列表中的元素
price=[100,200,300]
i=0
while i<len(price):
price[i]=price[i]*7
i+=1
print(price) #[700, 1400, 2100]
使用for语句来实现修改列表元素的方法如下,使用该方法不是直接修改i,而是修改列表中第i个元素
price=[100,200,300]
i=0
for i in range(len(price)):
price[i]='*'
print(price)
python中,可以通过sort方法对一个列表中的元素进行排序,sort方法的key参数,可以指定一个函数名(包括自己创建的函数),作为排序的规则,key参数可以接受任何一个能够返回可用于排序的键的函数或表达式,除了函数外,还接受lambda、属性访问、操作符函数、多个键,如果想反向排列,再加一个参数【reverse=True】
#python中,可以通过sort方法对一个列表中的元素进行排序,sort方法的key参数,可以指定一个函数名,作为排序的规则
fruits=['cherry','apple','banana',]
fruits.sort(key=len) #根据列表中每个元素的长度,从小到大排序
print(fruits) #['apple', 'cherry', 'banana']
#lambda示例,使字符串列表中的元素按字母顺序排序
fruits = ["apple", "banana", "cherry", "date", "elderberry"]
fruits.sort(key=lambda x: x.lower())
print(fruits)
# 输出:['apple', 'banana', 'cherry', 'date', 'elderberry']
#属性访问
'''
在这个例子中,我们定义了一个 Person 类,具有 name 和 age 属性。我们创建了一个 people 列表,其中包含了几个 Person 对象。我们使用 lambda 表达式来指定排序的键为 name 属性,导致对象列表按照姓名的字母顺序进行排序。
'''
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
people = [
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 20)
]
people.sort(key=lambda x: x.name)
for person in people:
print(person.name, person.age)
# 输出:
# Alice 25
# Bob 30
# Charlie 20
#操作符函数
#使用了 operator.itemgetter 函数来指定排序的键为每个元素的索引为 1 的值。这将导致列表按照第二个元素的值进行排序。
import operator
numbers = [4, 2, 8, 6, 5]
numbers.sort(key=operator.itemgetter(1))
print(numbers)
# 输出:[2, 4, 5, 6, 8]
#多个键
#使用 lambda 表达式来指定排序的键为元组 (x.age, x.name)。这将导致对象列表首先按照年龄进行升序排序,如果年龄相同,则按照姓名的字母顺序进行排序。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
people = [
Person("Alice", 25),
Person("Bob", 30),
Person("Charlie", 20)
]
people.sort(key=lambda x: (x.age, x.name))
for person in people:
print(person.name, person.age)
# 输出:
# Charlie 20
# Alice 25
# Bob 30
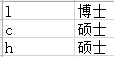
读取Excel表格,按表格的第二列的内容进行排序,表格内容如下:
import xlwings as xw
#使用xlwings将Excel文件中的名单读入到列表name中
app=xw.App()
wb=app.books.open('D:\\Python\\学习\\test.xlsx') #读取的文件,好像必须要完整的路径?
names=wb.sheets['Sheet1'].range('a1:b3').value #设置读取的范围,并返回给名为names的变量
wb.close()
app.quit()
print(names)
print('----------------')
#循环打印names中的每一个元素,每个占一行
for n in names:
print(n)
print('----------------')
def order(s):
#由于传进来的每一个元素都是一个列表,排序时取列表中的第1个元素进行计算
if s[1]=='硕士':
return 1
if s[1]=='博士':
return 2
else:
return -1
names.sort(key=order,reverse=True)
for n in names:
print(n)
以上程序最终的输出结果为:
[‘l’, ‘博士’]
[‘c’, ‘硕士’]
[‘h’, ‘硕士’]
更为简化的写法是,创建一个字典,字典内放置文本以及对应的值,然后通过函数检查字典内对应的值
import xlwings as xw
#使用xlwings将Excel文件中的名单读入到列表name中
app=xw.App()
wb=app.books.open('D:\\Python\\学习\\test.xlsx') #读取的文件,好像必须要完整的路径?
names=wb.sheets['Sheet1'].range('a1:b3').value #设置读取的范围,并返回给名为names的变量
wb.close()
app.quit()
d={'硕士':1,'博士':2}
def order(s):
t=s[1]
return d[t]
names.sort(key=order,reverse=True)
for n in names:
print(n)
除了sort(),sorted()方法也可以对列表进行排序,用法是【sorted(列表名,key,reverse)】,它可以将指定的列表复制后,对复制的新列表进行排序,不修改原列表
random.shuffle(列表名)可以对列表内容进行随机排序,相当于“洗牌”,使用前需要import random
import xlwings as xw
import random
#使用xlwings将Excel文件中的名单读入到列表name中
app=xw.App()
wb=app.books.open('D:\\Python\\学习\\test.xlsx') #读取的文件,好像必须要完整的路径?
names=wb.sheets['Sheet1'].range('a1:b3').value #设置读取的范围,并返回给名为names的变量
wb.close()
app.quit()
random.shuffle(names)
for n in names:
print(n)
random.sample(列表,数量)可以从指定列表中,随机抽取指定数量元素,并放在一个列表中返回,而且在返回的结果中,各个元素的顺序也是随机的,值得注意的是,即使抽取一个元素,random.sample()返回的也是一个列表(长度为1)
2.zip函数轻松合并列表,range对象竟然无视内存
以下程序可以实现,从给定的姓氏与名字列表中,随机生成姓名列表
from random import sample,randint
姓=['李','陈','黄','宋','瓦',]
名=['灵','悦','愉','茉','黛','清','风','知','礼']
#名=名*2 #如果名字中需要叠字,那么可以将列表中的每个字重复,然后让程序从有重复字的名字列表中抽取名字
名单=[]
'''
通过join()方法连接字符串,随机抽取一个姓,随机抽取1个或二个名'''
i=0
while i < 20:
姓名=''.join(sample(姓,1)+sample(名,randint(1,2)))
if 姓名 not in 名单: #避免重复,只有在得到新的姓名组合时才添加进列表
名单.append(姓名)
i+=1 #只有在每次得到一个新的姓名组合后才+1
print(名单)
#['黄灵黛', '黄悦灵', '陈知', '瓦清悦', '李灵悦', '李悦', '李礼', '黄风悦', '瓦风悦', '陈茉', '宋黛', '宋风知', '黄风愉', '宋茉', '李灵', '陈悦知', '陈知黛', '瓦悦清', '瓦茉', '李知']
zip()方法可以将两个或多个列表,相同位置的元素拼合,得到一个新的列表,列表中的每个元素都是元组,元组中包含每个指定列表中对应位置的元素,新列表的长度取决于之前所有个列表中最短列表的长度
更准确的说法是,zip()返回的,是一个迭代器(iterator),“迭代”或者说“iterate”可以理解为“按某种顺序逐个访问”,比如用for循环遍历一个列表内的每个元素,那么这个for循环的过程就可以被称作迭代的过程,因为列表支持使用for循环对里面的元素进行逐个访问,因此也可以将列表看做可迭代对象,包括列表、字典‘字符串等容器都可以被“迭代”,因此Python中的所有容器都属于“可迭代对象”,可迭代对象不仅仅包括各种“容器”,好包括range、zip等其他各种类型
姓=['李','陈','黄','宋','瓦',]
名=['灵','悦','愉','茉','黛','清','风','知','礼']
#名=名*2 #如果名字中需要叠字,那么可以将列表中的每个字重复,然后让程序从有重复字的名字列表中抽取名字
名单=zip(姓,名)
for n in 名单:
print(n)
#返回结果
'''
('李', '灵')
('陈', '悦')
('黄', '愉')
('宋', '茉')
('瓦', '黛')
'''
print('-----------------')
姓=['李','陈','黄','宋','瓦',]
名=['灵','悦','愉','茉','黛','清','风','知','礼']
#名=名*2 #如果名字中需要叠字,那么可以将列表中的每个字重复,然后让程序从有重复字的名字列表中抽取名字
名单=zip(姓,名)
for n in 名单:
print(''.join(n))
'''
李灵
陈悦
黄愉
宋茉
瓦黛'''
range返回的并非“列表”而是一个“range”对象,直接print,只会显示起始值(从0开始)到结束值,比如range(10)返回的是range(0, 10),可以使用for循环遍历range对象中的每个数值,也可以通过list()方法将range对象转换为列表。
值得注意的是,x=list(range(1000000000000))可能会挤满计算机的内存,但x=range(1000000000000)
却能正常运行,甚至提取其中任意一个元素,比如print(x[100])会返回100
3. 生成式长得帅跑得快,迭代器拿时间换空间
“列表生成式”是专门用来生成列表的表达式,它的运算速度比普通循环更快
在已有一个列表的情况下,想要得到基于第一个列表每个数值乘以10的第二个列表,也就是说第二个列表中每个元素是第一个列表中对应位置的元素的10倍,第一个方法是
l1=[100,200,300]
l2=[]
for i in l1:
l2.append(i*10)
print(l2)
由于非常常用,Python为此提供了更精简的写法,先将要填入列表的内容填入方括号,然后将循环规则(不包含冒号)写入方括号,这样就得到了一个列表生成式
需要注意的是,最外面必须要是方括号,因为要生成的是一个列表,在方括号中,要先写循环结果,后写循环规则
l1=[100,200,300] l2=[i*10 for i in l1] print(l2) #案例2 from math import sin l1=[100,200,300] l2=[sin(i) for i in l1] print(l2)
for循环不仅仅能遍历列表,可以遍历任何可迭代对象,因此列表生成式也具有同样的功能
a=[i/10 for i in range(1,100)]
print(a)
#相当于以下for循环
for i in range(1,100):
a.append(i/10)
#运行后得到的结果是[0.1,0.2......9.9]
for循环能用的语法,生成式里都可以使用
with open('1.txt','r') as f:
原始文本列表=f.readlines()
整理后列表=[s.split(',') for s in 原始文本列表[1:]] #从第二行开始读取,每行内容以逗号进行分割
关键信息= [x[0],float(x[5]),int(x[6].strip() for x in 整理后列表] #仅获取其中个别列的数据,并针对性的进行格式化
print(关键信息)
此处为语雀视频卡片,点击链接查看:[9.4]–第十四回 生成式长得帅跑得快,迭代器拿时间换空间.mp4
在 Python 中,next() 是一个内置函数,用于从迭代器中获取下一个元素。它允许您逐步访问迭代器中的元素,一次获取一个,允许使用next()逐个访问的统称为“迭代器”,但最好使用for循环访问迭代器,因为next不仅写法繁琐,而且最后一次访问时会有异常。
next()和for都只能向后逐个读取,不能回头读取前面的元素,所以迭代器中的元素一旦被读取过,就再无法重新读取。
有两种方式可以编写迭代器,第一种是定义一个类,然后使用next等等方法,,这种方法生成的迭代器就叫做“普通迭代器”iterator,例如zip对象,第二种方法是使用yieled关键字或圆括号生成式写出的代码,也叫做迭代器,但因为写法比较特殊,所以算作迭代器中的子类,叫做生成器(generator),例如x for x in [1,2,3]
可迭代对象包括:常见容器(列表、字典、集合等)、range对象、迭代器(iterator)以及其他可迭代对象
迭代器(包含子类生成器)以及其他可迭代对象,一般不允许通过下标的方式直接引用指定位置的元素,而必须使用nexy()函数从第一个开始逐个找到后面的元素,而且与其他可迭代对象不一样的地方时,迭代器、生成器里面所有的元素都只能访问一次,一旦访问一次,就不能回头重新找到它,用完之后,必须重新定义一边,才能重新使用
4.字典也有生成式,却拿空间换时间
可以使用dict()方法将一个列表转换成字典,但是被转换的列表必须是每个元素都包含两个数据的列表,才可以直接构造字典对象,否则无法转换
a=[['a',100],['b',200],['c',300]] d=dict(a) print(d)
另一个将列表转换为字典的方法是,先用zip()方法合并两个列表每个位置对应的元素,虽然zip()方法生成的对象不是列表,但依然可以被dict()所转换
zip()的功能是:将多个可迭代对象(包括列表、元组、字符串)内的对应位置的元素打包成一个个元组,并返回一个由这些元组所组成的迭代器
a=['a','b','c']
b=[1,2,3]
d=dict(zip(a,b))
print(d) #{'a': 1, 'b': 2, 'c': 3}
.count()方法可以统计一个可迭代对象中,某个元素在里面出现了多少次,比如:
fruits = ('apple', 'banana', 'orange', 'apple', 'grape', 'apple')
count = fruits.count('apple')
print(count) # 输出: 3
以下代码通过zip、count以及dict方法,实现对列表中每个元素出现次数的统计,并且将每个单独的元素与其出现的次数生成一个字典
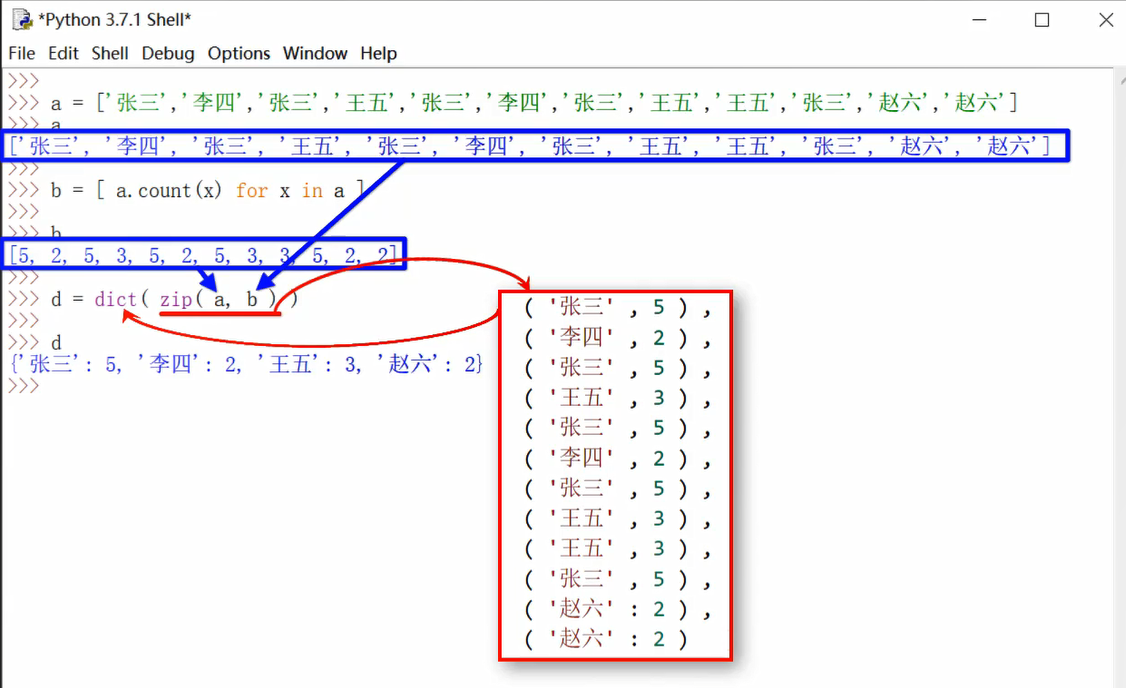
i=['l','h','c','c']
b=[i.count(n) for n in i] #每次遍历列表中的元素,都返回该元素在列表中出现的次数,最后将每个元素出现的次数生成一个列表
print(b) #[1, 1, 2, 2]
d=dict(zip(i,b)) #将两个列表进行zip,然后通过zip对象生成字典,字典会去除重复建,每个键只保留一个
print(d) #{'l': 1, 'h': 1, 'c': 2}
.fromkeys()是字典类对象的方法,用于创建一个新的字典,给它一个列表作为参数,它会将列表中的每个元素,作为字典中的键放置在字典中,如果不设置默认值,那么在新生成的字典中,所有的键对应的值都是None,
需要注意的是,直接使用fromkeys()并不会对字典对象本身的内容进行改变,而是需要将其赋值给其他的对象,就算对一个已有内容的字典使用formkeys方法,返回的结果也不会包含该字典已有的内容,所以fromkeys方法一般都是针对空字典{}进行使用
fromkey方法无法将一个二维列表转换成字典,二维列表指的是,列表中的每个元素也都是列表,在fromkeys看来,所有的列表都是一维列表,如果在fromkeys的方法中填入二维列表作为参数,那么二维列表中的单个列表元素会作为字典的键,但Python中又规定只允许使用不可变对象作为字典的键,而列表属于可变对象,因此程序会报错
a=['a','b','c','d']
d={}
d=d.fromkeys(a) #需要进行赋值,才能修改d的内容
print(d) #{'a': None, 'b': None, 'c': None, 'd': None}
可以直接对一个空字典,也就是两个花括号,使用.fromkeys()方法
a=['a','b','c','d']
d={}.fromkeys(a) #直接对一个空字典使用.fromkeys()方法
print(d)
可以给指定新字典的默认值,只需要给.fromkeys()方法加入第二个参数
a=[1,2]
b={}.fromkeys(a,'v')
print(b) #{1: 'v', 2: 'v'}
fromkeys方法经常被用来创建一个初始字典,然后再使用循环等结构,修改每个键对应的值
需要注意的是,通过for循环来遍历字典中的内容,每次读取只会得到每一个键,并不会得到值,想要通过for循环得到每个键的值,可以使用以下代码:
d={"a":1,"b":2,"c":3}
for i in d:
print(d[i])
另一个方法是,for i in 字典.values():
通过.fromkeys()方法得到列表中每个元素出现的次数,并创建一个子弹
a=[1,1,2,2,2,3,3,3]
d={}.fromkeys(a,0)#通过列表a创建字典,后者的每个元素所做字典的键,每个键的默认值为0
for k in d:
d[k]=a.count(k) #字典中每个键的值 等于 列表中每个元素出现的次数
print(d) #{1: 2, 2: 3, 3: 3}
如果formkeys的第二个参数是一个列表,也就是生成的新字典都以这个列表作为默认的值,根据前面所学的内容,这个作为默认参数的列表会得到一个内存地址,而新字典中每个键的默认值都指向同一个内存地址,如果修改列表,意味着该字典所有的键的值都会改变,因为它们都指向同一个内存地址,因此Python官方建议,不要使用可变对象比如列表作为默认值。
字典生成式
与列表生成式一样的原理
d={x:x*x for x in a}
传统写法:
stock_data = [
['AAPL', 135.52, 133.43, 134.16, 135.37, 1000000, '2023-05-19'],
['GOOGL', 2426.31, 2415.52, 2422.89, 2424.98, 750000, '2023-05-19'],
['AMZN', 3280.94, 3256.43, 3265.79, 3278.39, 500000, '2023-05-19'],
['MSFT', 248.15, 246.91, 247.52, 248.06, 900000, '2023-05-19'],
['TSLA', 605.12, 595.50, 600.00, 602.89, 600000, '2023-05-19']
]
d={}
for i in stock_data: #遍历列表中每一个列表,i会是列表中的小列表
d[i[0]]=i[6] #左边,小列表中的第一个值作为字典的键,列表中第7个值作为值
print(d) #{'AAPL': '2023-05-19', 'GOOGL': '2023-05-19', 'AMZN': '2023-05-19', 'MSFT': '2023-05-19', 'TSLA': '2023-05-19'}
字典生成式的写法:
stock_data = [
['AAPL', 135.52, 133.43, 134.16, 135.37, 1000000, '2023-05-19'],
['GOOGL', 2426.31, 2415.52, 2422.89, 2424.98, 750000, '2023-05-19'],
['AMZN', 3280.94, 3256.43, 3265.79, 3278.39, 500000, '2023-05-19'],
['MSFT', 248.15, 246.91, 247.52, 248.06, 900000, '2023-05-19'],
['TSLA', 605.12, 595.50, 600.00, 602.89, 600000, '2023-05-19']
]
#字典生成式
d={x[0]:x[5] for x in stock_data} #for之前,左边是小列表的键与小列表的值的位置,右边是循环方法
print(d) #{'AAPL': 1000000, 'GOOGL': 750000, 'AMZN': 500000, 'MSFT': 900000, 'TSLA': 600000}
通过字典生成式的方法,来统计列表中每个元素出现的次数,并生成字典
传统写法:
a=['a','b','c','d','e','e']
d={}
for i in a:
d[i]=a.count(i)
print(d)
字典生成式的写法
a=['a','b','c','d','e','e']
d={i:a.count(i) for i in a} #遍历列表中每个元素,以每个元素作为键,加上冒号表示字典,冒号右边是次数统计,for 之后是循环规则
print(d) #{'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 2}
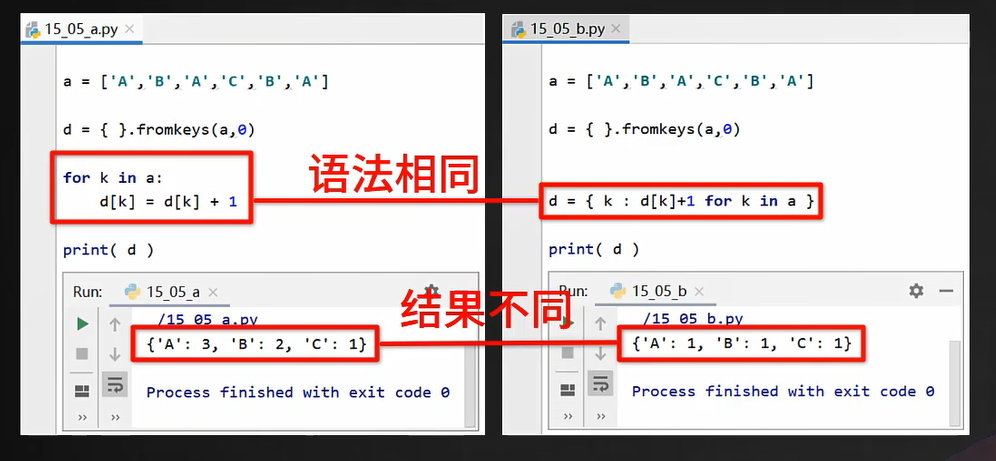
列表生成式允许if判断语句,字典生成式同样也支持,如果有if,需要放在for后面
只找出出现2次及以上的元素放入字典中
传统写法:
a=['a','b','c','d','e','e']
d={}
for i in a:
if a.count(i)>=2:
d[i]=a.count(i)
print(d) #{'e': 2}
字典生成式写法a:
a=['a','b','c','d','e','e']
d={i:a.count(i) for i in a if a.count(i)>=2}
print(d) #{'e': 2}
字典生成式与列表生成式,与传统的for循环并不完全相等
5.字典元素任遍历,元组赋值巧解包
字典.values()可以得到包含该字典的所有值的一个可迭代对象,class ‘dict_values’,在早期Python版本中,它属于列表,但它不支持索引,因此现在已经不再是列表,也不支持使用next()函数,因此也不是迭代器,之所以它可以被看做是可迭代对象,因为支持使用for循环来遍历
字典.values()返回的对象属于dictview类型
统计一个列表中,出现X次数的元素有多少个,然后生成字典
#统计列表中,出现N个的分别有几个元素,将统计结果生成字典,键对应次数,值对应元素数量
a=['a','b','c','d','e','e'] #列表
d={i:a.count(i) for i in a} #生成一个字典,得到每个元素以及每个元素出现的次数
print(d) #{'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 2}
f=list(d.values()) #将上面字典的所有值转换成一个列表,也就是每个元素出现的次数
print(f) #[1, 1, 1, 1, 2]
d2={k:f.count(k) for k in f} #用字典生成式生成一个字典,左边是单个元素出现的次数,右边是出现这个次数的元素有多少个
print(d2) #{1: 4, 2: 1}
统计一个列表中,出现次数最多的元素是哪些
#统计列表中,出现次数最多的元素出现了是哪些,并且出现了多少次,生成字典
a=['a','b','c','d','e','e','f','f'] #列表
d={i:a.count(i) for i in a} #先用字典生成式得到每个元素出现的次数
print(d) #{'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 2, 'f': 2}
m=max(d.values()) #获取字典中所有的值,通过max()得到最大的值是哪一个
d2={i:d[i] for i in d if d[i]==m} #利用字典生成式,遍历字典中每个元素,如果值等于m,那就将这对键值放入新的字典
print(d2) #{'e': 2, 'f': 2}
字典.values()可以返回字典中所有的值
字典.keys()可以返回字典中所有的键
字典.items()也可以返回一个dictview,其中每个元素都是一个元组,每个元组包含字典中的一个键和值,如果直接print,那么显示效果是【dict_items([(‘e’, 2), (‘f’, 2)])】,但可以通过for循环取出里面的元组【for i in d2.items():print(i)】,可以逐一得到每个元组(原字典的键与值)
通过字典的.items()得到该字典的所有键值:
p={"name":"lingjie","age":"25"}
for i in p.items():
print(i[0],i[1])
更精简的写法:
p={"name":"lingjie","age":"25"}
for x,y in p.items():
print(x,y)
'''
输出结果:
name lingjie
age 25
'''
反向字典,也就是键值互换
p={"name":"lingjie","age":"25"}
p2={y:x for x,y in p.items()} #让xy等于字典的键值,然后让y等于键,x等于值
print(p2) #{'lingjie': 'name', '25': 'age'}
解包
Python中的解包指的是,将可迭代对象()元组、字典、列表、集合等),将里面的元素直接拿出来赋值给其他变量,比如上面的反向字典案例,让xy得到了字典中的元组的两个值
a,b=(1,2)
解包操作可以在for循环中使用,for a,b in 字典.items()相当于让a与b得到字典的键值
解包操作时,等号右边甚至可以不需要括号,实现一条语句将多个值赋给多个变量,这种操作也被称为“多元赋值语句”,但需要注意的是,等号左右两边的元素数量需要一致:
a,b=1,2
这种方法也可以交换两个变量之间的值:a,b=b,a
解包操作的右边也可以是一个字符串:a,b,c=’甲乙丙’
如果解包操作等号右边是字典,那么等号左边的变量将被赋值字典的键
一般来说,解包操作中等号左右两边的数量要保持一致,如果不一致,在python2中肯定会报错,但是Python3中,如果左边的变量数量少于右边的值的数量,可以为左边其中任意位置的一个变量前加上*号,
在其他的变量都被赋值完成之后,最后一个被加上*号变量将得到右边剩余所有的值(列表),即使剩余1个元素,也会被作为一个列表返回给加上*号的变量,
如果*号的变量位置在中间,那么左边第一个变量会被赋值左边第一个值,左边最后一个变量会被赋值右边最后一个值,右边中间剩余的变量会被赋值给左边加*号的变量yi
x,y,*z=100,200,233,666 print(x) #100 print(y) #200 print(z) #[233, 666]
一组分数中,去掉一个最高分,去掉一个最低分,计算平均值:
a=66,233,3,4,5,6,7 最低分,*有效分,最高分=sorted(a) #对a列表内的数值进行从小到大排序,然后解包,最低分与最高分得到列表开头与末尾的值,中间的有效分得到剩下所有的数值 print(最低分) print(最高分) print(有效分) 平均分=sum(有效分)/len(有效分) #对列表进行求和,然后处于列表中的元素数量,得到列表的平均值 print(平均分)
6.集合运算统计名单变动,Counter与chain简化数
Python中集合的3个重要特性是:
不允许出现重复元素/元素排列无特定顺序/只能包含不可变类型的元素
只能包含不可变类型的元素意味着,集合的元素可以是字符串、数值、元组,但不能是列表或另外一个集合
可以通过set()方法将一个列表/元组/字典转换成集合,如果将字典转换成集合,那么集合中只会包含字典中所有的键,此外,zip、range等可迭代对象也能通过set()方法转换成集合
将一个列表转换成集合再转换回列表,可以去除原始列表中的重复值
a=['中国','美国','意大利']
b=['cn','usa','it']
c=zip(a,b) #zip()的功能是将两个列表对应位置的元素打包成一个元组,所有的元组合并成一个zip可迭代对象
print(c) #<zip object at 0x000001D4A69EF8C0>
s=set(c)
print(s) #{('美国', 'usa'), ('意大利', 'it'), ('中国', 'cn')}
Python中的集合可以用来计算交集/差集/并集
交集:
a={1,2,3}
b={2,3,3}
c=a&b # 【&】符号取交集,也就是两个集合中都有的元素
print(c) #{2, 3}
如果两个集合之间没有相同的元素,那么取交集后会得到一个空集合,但是因为空花括号{}表示一个空字典,因此空集合会被set()来表示:
判断变量a是否属于空集合:
if a==set():
或者
if len(a)==0:
又或者直接写成 if a:
并集:
并集运算符【|】
a={1,2,3}
b={2,3,3}
c=a|b # 【|】符号取并集,取得a与b中所有出现过的元素(会过滤掉重复的元素)
print(c) #{2, 3}
差集:
差集运算符【-】
可以得到【-】号前面的变量有,而右边的变量没有的元素
a={1,2,3}
b={2,3,6}
c=a-b # 【-】符号取差集,取得左边变量有,而右边变量没有的元素
print(c) #{2, 3}
通过上月在职员工名单与本月在职名单的列表,得到离职员工与新员工的列表
import xlwings as xw
app=xw.App() #创建一个Excel应用程序对象
wb=app.books.open('names.xlsx') #指定工作簿
ws=wb.sheets[0] #指定工作表
n1=ws.range('a2:a39').value #得到工作表中第一列数据
n2=ws.range('b2:b35').value
#获取离职员工列表
#取差集,也就是上月有但本月没有的员工
离职员工=set(n1)-set(n2)
#获取本月新员工列表
#取差集,本月有,但上月没有的员工
新员工=set(n2)-set(n1)
ws.range('c2').options(transpose=True).value=list(离职员工)#将集合转换成列表,然后设置transpose以一列的方式从指定的单元格位置开始写入
ws.range('d2').value=list(新员工) #如果有名.options(transpose=True),那么这个列表会以横排的方式从指定的单元格开始写入
wb.save('names.xlsx')
wb.close()
app.quit()
集合的其他方法与运算符
| 方法/运算符 | 作用 | 示例 |
| add | 向集合内添加元素 | s.add(元素) |
| remove | 从集合内删除指定数值的元素 | s.remove(x) |
| pop | 让集合删除并返回该元素(由Python决定删除哪个元素,不能由程序员空值) | x=s.pop() |
| clear | 移除集合内所有元素 | s.clear() |
| issubset | 判断本集合是否是另一个集合的子集,也就是另一个集合是否包含本集合的所有元素,返回True或False | a.issubset(b) |
| <= | 同issubset | a<=b |
| issuperset | 判断本集合是否是另一个集合的父集,也就是本集合是否包含另一个集合的所有元素 | a.issuperset(b) |
| >= | 同issuperset | a>=b |
| union | 返回本集合与其他集合的并集 | a.union(b,c,d) |
| intersection | 返回本集合与其他集合的交集 | a.intersection(b,c) |
| difference | 返回本集合与其他集合的差集 | a.difference(b,c) |
| isdisjiont | 判断本集合与其他集合的交集是否为空(即不 相交) | a.isjiont(b) |
Python内置了collections库,其中的Counter是一个计数器,可以用它来得到一个可迭代对象中每个元素出现的次数,返回的是一个类似字典的Counter类型的对象,用法与字典完全相同
from collections import Counter
a=['apple','banana','apple']
b=Counter(a)
print(b) #Counter({'apple': 2, 'banana': 1})
两个Counter对象之间可以直接相加,相同键的值会进行求和,其他键也会被放入相加的结果中
两个Counter对象之间也可以相减,但是如果其中一个元素相减后得到的值为负数,就不会出现在相减后的结果中,也就是说Counter减法中,只保留正数的结果,减数中出现了被减数中没有的元素,该元素也不会出现在结果中,因为0-任何正数都是负数
Counter对象也可以通过【&】与【|】符号做交集与并集运算
max()函数在处理二维列表时,并不会取出每一个单独的元素作比较,而是将二维列表中的每个小列表的第一个元素取出来作比较,返回第一项最大的子列表,如果第一项都相同,则顺次比较第二项,以此类推
a=[[1,5],[3,4],[2,1,3]] print(max(a)) #[3, 4] 所有子列表中第一个二元素最大的是[3,4]
通过列表生成式,得到二维列表中数值最大的元素
a=[[1,5],[3,4],[2,1,3]] b=[max(x) for x in a] #得到每个子列表中的最大的值,返回一个新列表 print(b) #[5, 4, 3] c=max(b) print(c) #5 第二次比较
更精简的写法:
a=[[1,5],[3,4],[2,1,3]] b=max([max(x) for x in a]) print(b) #5
Python中有一个itertools模块,其中有一个函数是itertools.chain,可以将多个可迭代对象连接在一起,形成一个新的单一的迭代器,它按照它们在参数中出现的顺序依次返回元素
也就是说,itertools.chain可以将二维列表转换成一维列表
from itertools import chain list1 = [1, 2, 3] list2 = [4, 5, 6] tuple1 = (7, 8, 9) x=chain(list1,list2,tuple1) print(x) #<itertools.chain object at 0x00000122B4CCCFA0> 返回一个chain类型的可迭代对象 x=list(x) #可以转换成列表 print(x) #[1, 2, 3, 4, 5, 6, 7, 8, 9]
通过itertools模块中的chain来得到二维列表中数值最大元素的方法
from itertools import chain list1 = [1, 2, 3] list2 = [4, 5, 6] li=[list1,list2] x=list(chain(*li)) #解包写法,相当于chain(li[0],li[1]) print(x) #[1, 2, 3, 4, 5, 6] print(max(x)) #得到最大值6
当你调用chain(*li)时,*li使用了解包的写法,这里的*li是一个包含两个列表list1和list2的列表。
解包操作*li将li中的元素拆分开,相当于chain(list1,list2),chain函数是Itertools模块中的一个函数,它的作用将多个可迭代对象连接在一起,返回一个迭代器,按照它们在参数中出现的顺序依次输出元素。
在上述例子中,chain(list1,list2)会将list1和list2连接在一起,产生一个包含list1和list2所有元素的迭代器,接着,通过list()函数继昂这个迭代器转换成列表,赋值给x
7.拷贝容器细分深与浅,可变对象难做默认值
如果函数的参数默认值是可变对象(列表、集合、字典等),该默认值在程序运行之初的“编译阶段”就已经被创建, 并一直保留在内存中
所以每次调用函数,修改的都是同一个默认值对象
最好的方法,就是不使用可变对象作为函数的默认值
def add_End(t=[]): #创建一个函数,默认参数是一个空列表
t.append('END') #为参数加上一个'END'元素
return t
if __name__=="__main__":
x=add_End()
print(x) #['END']
y=add_End()
print(y) #['END', 'END'] #返回2个END
z=add_End()
print(z) #['END', 'END', 'END'] #返回3个END
#每次调用函数,用的都是同一个内存拷贝,而不是创建一个空的list对象,所以调用了同样的函数,但返回的结果却不一致
新手常见的错误还有误将浅拷贝当做深拷贝
a=['a','b','c'] b=a #a与b指向同一个内存地址 a[1]=1 #修改a列表中的元素,因为指向同一个内存地址,因此b也发生了改变 print(b) #['a', 1, 'c']
。copy()方法属于浅拷贝,浅拷贝可以解决上面的问题,但并不完全,如果a中的一个元素是列表,该类问题还是会出现
a=['a','b','c']
b=a.copy() #复制a的内容到新的内存地址并链接到b
a[0]=1 #修改a后b不会发生变化
print(b) #['a', 'b', 'c']
print('-----------------')
a=['a',['b','c'],'d']
b=a.copy()
a[1][0]='test' #修改a列表里的小列表里的第一个元素,b也跟着发生变化,因为小列表指向的都是同一个内存地址
print(b) #['a', ['test', 'c'], 'd']
Python自带的copy模块中有一个deepcopy,不仅能拷贝列表的第一层,还能拷贝列表的子列表甚至子列表的子列表
from copy import deepcopy a=['a',['b','c'],'d'] b=deepcopy(a) a[1][0]='test' #修改a子列表中的第一个元素 print(a) #['a', ['test', 'c'], 'd'] #a被改变 print(b) #['a', ['b', 'c'], 'd'] #b保持不变
深拷贝不仅对列表有效,对所有嵌套的容器都能使用,包括字典等
a={"a":[1,2],"b":[10,11]}
b=a.copy()
b['b'][0]=6 #修改b字典中b键的值的第一个元素
print(a) #{'a': [1, 2], 'b': [6, 11]} #a跟着被改变
print(b) #{'a': [1, 2], 'b': [6, 11]}
from copy import deepcopy
a={"a":[1,2],"b":[10,11]}
b=deepcopy(a)
b['b'][0]=6 #修改b字典中b键的值的第一个元素
print(a) #{'a': [1, 2], 'b': [10, 11]} #a没有跟着被改变
print(b) #{'a': [1, 2], 'b': [6, 11]}
一些新手可能会通过乘法制作二维列表
对一维列表使用乘法,可以使里面的元素重复多少次
a=[1,2] b=a*2 print(b) #[1, 2, 1, 2]
对二维列表使用上述的乘法,看起来能起到同样的效果,但是,如果修改了二维列表中的第一个子列表,另一个被复制出来的子列表中的内容也会跟着改变,因为它们都被指向了同一个内存地址,因此这种用法是不规范的
a=[1,2] b=a*2 print(b) #[1, 2, 1, 2] c=[b]*2 print(c) #[[1, 2, 1, 2], [1, 2, 1, 2]] c[0][0]=6 print(c) #[[6, 2, 1, 2], [6, 2, 1, 2]] #修改第一个子列表,第二个子列表也会跟着改变
通过id()可以查看列表或子列表的内存地址
通过列表生成式生成二维列表
b=[[0,0,0] for i in range(2)] print(b) #[[0, 0, 0], [0, 0, 0]] 通过列表生成式生成二维列表 #实现同样功能但更精简的代码 b=[[0]*3 for _ in range(2)] #写成_因为它没有任何意义只是用来控制循环次数 print(b) #[[0, 0, 0], [0, 0, 0]]
8.Numpy玩转二维结构,Pandas搞定统计分析
Numpy之核心结构:ndarray
ndarray是N-dimensional array(N 维度 数组)的缩写
可以使用array()将列表等容器转换为ndarray类型的数组
import numpy as np x=[1,2,3] a=np.array(x) print(a) #[1 2 3] print(type(a)) #<class 'numpy.ndarray'>
将ndarray数据看做矩阵,可以进行整体的数学运算
import numpy as np x=[1,2,3] a=np.array(x) print(a) #[1 2 3] print(type(a)) #<class 'numpy.ndarray'> b=a*3 #进行数学运算而不是复制3次列表 print(b) #[3 6 9]
import numpy as np x=[1,2,3] a=np.array(x) print(a) #[1 2 3] print(type(a)) #<class 'numpy.ndarray'> b=a*3 #进行数学运算而不是复制3次列表 print(b) #[3 6 9] c=b*2-a #两个array对象之间也可以进行数学运算 print(c) #[ 5 10 15]
列表=array对象.tolist() 可以将一个array对象转换成Python中的普通列表
不仅仅是加减乘除,array对象还可以进行其他数学运算,比如求平方: array对象**2
import math模块后,不能调用math模块中的某些方法来进行更高级的运算,因为某些方法要求输入的参数是数字而不是其他对象
但是Numpy模块本身,就已经提供了许多函数对数组进行统计运算,比如np.log(ndarray对象)或者np.sin(ndarray对象)等,
除了各种数学计算还属外,Numpy还提供了各种统计函数
| 函数名 | 函数功能 |
| sum | 计算总和 |
| mean | 计算平均值 |
| average | 计算加权平均值 |
| std | 计算标准差 |
| var | 计算方差 |
| min | 取最小值 |
| max | 取最大值 |
| argmin | 返回最小值元素所在的下标位置 |
| argmax | 返回最大值元素所在的下标位置 |
| ptp | 计算极差(最大值与最小值之间的差) |
| median | 计算中位数 |
| corrcoef | 计算相关系数 |
| percentile | 计算百分位数 |
import numpy as np x=[10,100,60] a=np.array(x) print(np.max(a)) #100 得到最大值
ndarray对象可以通过reshape()方法从一维对象转换为二维对象,在转换时数字要匹配元素数量(比如20个元素的ndarray对象可以转换为2行10列,但不能转换成6行1列),否则会报错
二维对象还可以进行reshape成另一个二维对象
对二维对象使用统计方法,就像对一维对象使用统计方法一样
ndarray对象.T 可以进行行列转置,也就是行变成列,列变成行
import numpy as np a=np.arange(20) #得到一个拥有20个数值元素的ndarray对象 print(a) #[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] b=a.reshape(2,10) #转换成2行10列,或者说分成2组,每组10个对象 print(b) ''' [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19]]''' c=b.reshape(1,20) #二维数组还可以再重新reshape() print(c) #[[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]] print(np.max(b)) #返回19 #二维数组使用统计方法,就像对一维数组使用统计方法一样 d=c.T #转置,行变成列,列变成行 print(d) ''' [[ 0] [ 1] [ 2] [ 3] [ 4] [ 5] [ 6] [ 7] [ 8] [ 9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19]]'''