1.单表统计与计算技巧
计算特定的列
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('data.xlsx')
sheet=wb.sheets['weather']
#如果温度小于20度,就在【凉】列显示未凉,否则显示原来的温度
df=sheet.range('A1').options(pd.DataFrame,expand='table').value #定位A1单元格,然后扩展,得到整个工作表的内容,再转换为DataFrame
df['凉暖']=None #原来的表格不存在‘凉’列,所以需要新建一列
df.loc[df['温度°C']<=20,'凉']='凉' #通过df.loc定位‘凉’列的单元格,loc需要索引名与列明,通过筛选得到索引名,然后填充‘凉’
df.loc[df['温度°C']>20,'凉']=df['温度°C'] #筛选出温度大于20的单元格,复制温度的值
print(df)在一列数据的最末尾单元格对上面的单元格进行求和,通过切片操作来完成,缺点是如果出现非数字的单元格可能会报错
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('data.xlsx')
sheet=wb.sheets['Sheet1']
df=sheet.range('A1').options(pd.DataFrame,expand='table').value
print(df.loc[:'求和','数学'].sum()) #求和是最后一行的索引名称,切片时不会包含最后一个在一列数据的最末尾单元格对上面的单元格进行求和,如果这一列中包含数值、文本、空值,可以先通过正则表达式处理数字部分
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('data.xlsx')
sheet=wb.sheets['Sheet1']
df=sheet.range('A1').options(pd.DataFrame,expand='table').value
#print(df.loc[df['英语'].astype(str).str.match('\d+(\.\d+)?'),'英语'].sum()) #筛选出包含数字的单元格
#print(df.loc[df['英语'].astype(str).str.match('\d+(\.\d+)?'),'英语'].apply(pd.to_numeric).sum()) #正则表达式提取数字单元格并进行求和
#如果某个单元格中包含数字,但也有其他的文本,上面的代码还是回报错,可以利用正则表达式,提取每个单元格的数字部分,然后进行求和
df['英语数字'] = df['英语'].astype(str).str.extract('(\d+\.?\d*)').astype(float)
print(df.loc[:'求和','英语数字'].sum())
'''
df['数学'].astype(str): 这部分将 '数学' 列的所有值转换成字符串类型。这是必要的,因为接下来的操作涉及到字符串匹配。
.str.match('\d+(\.\d+)?'): 这是一个正则表达式,用于在 '数学' 列中的每个元素上执行匹配操作。
\d+: 匹配一个或多个数字。
(\.\d+)?: 匹配零个或一个小数点后跟一个或多个数字的模式。整个模式被 ()? 包围,这表示整个小数部分是可选的。
所以这个正则表达式匹配一个整数或者一个浮点数。
df.loc[...]: .loc 方法用于访问 DataFrame 的行和列。在这种情况下,它被用来选择那些 '数学' 列中的值符合上述正则表达式的行。
, '数学': 这指定了要访问的列名。所以,整个表达式的作用是返回 '数学' 列中所有符合正则表达式(即是整数或浮点数)的行的 '数学' 列值。
总结来说,这行代码用于从 '数学' 列中筛选出所有表示整数或浮点数的值,并返回这些值所在的 '数学' 列的部分。这个表达式本身并没有修改原始的 DataFrame,它只是返回符合条件的值。'''\号表示一行尚未结束
在 Python 中,反斜杠 \ 是一个特殊字符,它用于多种不同的情况。其中之一是作为续行符,当在一行代码的末尾使用时,它表示该行代码在下一行继续。这在编写长代码行时很有用,可以提高代码的可读性。
result = 1 + 2 + 3 + \
4 + 5 + 6
在这个例子中,\ 表示 1 + 2 + 3 + 这行代码在下一行继续。
另外,反斜杠 \ 还用于转义字符,例如在字符串中插入特殊字符。例如,\n 表示换行符,\\ 表示文字中的反斜杠。
将DataFrame写入Excel
工作表.range(‘单元格’)=df
2.多表合并与汇总
基础的多表合并汇总案例
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('多表合并汇总.xlsx')
df_all=pd.DataFrame()
for ws in wb.sheets: #遍历工作簿中每一张工作表
df=ws.range('A1').options(pd.DataFrame,expand='table').value
#由于本次案例中,所有的df拥有相同的列标签,因此可以先通过pd.concat连接所有表格,然后通过groupby分组
df_all=pd.concat([df_all,df])
print(df_all)
print('---')
#要汇总的列是index,按加法求和的方式进行合并(注意,groupby汇忽略掉字符串的列,因为不能进行数学运算)
print(df_all.groupby(df_all.index).sum())自定义汇总方式
如果有更细致的要求,可以在groupby后面使用agg()函数,它可以指定每一列用哪种方式进行汇总
groupby对象的.agg()方法与.aggragate()方法相同,前者是后者的简写
.agg()的参数可以是字典/列表/函数
列表形式
如果是.agg()的参数是列表,那么列表里每个字符串都是针对每列要进行聚合的方式,比如
【df.groupby(‘column_name’).agg([‘sum’, ‘mean’, ‘std’])】
字典形式
如果.agg()的参数是一个字典,那么字典里列作为键,聚合方式最为名,都写成字符串形式,比如:
【aggregations = {
‘A’: ‘mean’,
‘B’: ‘sum’,
‘C’: ‘max’
}】
自定义函数
.agg()的参数也可以是自定义函数,比如:
【df.groupby(‘column_name’).agg(lambda x: max(x) – min(x))】
.agg()的函数如果是自定义函数或者python系统库中的函数,那么函数名不需要加上引号,如果是pandas自带的函数,比如sum,那么需要加上引号,写成’sum’
如果通过多张表格合并后的DataFrame,某一列都是字符串,在groupby后只想保留一个值,可以针对这一列使用min方法
ChatGPT解释:
当在Pandas的 groupby 对象中对一个字符串列使用 min 函数时,它会对每个分组中的字符串进行字典顺序排序,并返回每个分组中字典顺序最小的字符串。这里的“最小”是指在字典(或词典)排序中排在最前面的字符串。
自定义显示的列标签以及对一列进行多种统计的方法
groupby对象可以设置返回结果中,使用新的列名,如果要对某一列进行多种聚合操作,也可以使用这种方法
新的列名不需要写成字符串形式,后面跟着一个元组,元组内的列名与计算方法需要使用字符串形式
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('多表合并汇总.xlsx')
df_all=pd.DataFrame()
for ws in wb.sheets: #遍历工作簿中每一张工作表
df=ws.range('A1').options(pd.DataFrame,expand='table').value
#由于本次案例中,所有的df拥有相同的列标签,因此可以先通过pd.concat连接所有表格,然后通过groupby分组
df_all=pd.concat([df_all,df])
print(df_all)
print('---')
#要汇总的列是index,按加法求和的方式进行合并
print(df_all.groupby(df_all.index).agg(
温度求和=('温度°C','sum'),温度最小=('温度°C','min')
))仍和数值与nan(空值)相加都等于nan,如果使用自定义函数对某一列进行运算,而某一列又包含nan,可能会返回预期之外的结果
因此在运算之前,可以先判断是不是nan,如果是nan,就不进行计算
import pandas as pd
def 平方和(data):
total = 0
for i in data:
if not pd.isna(i):
total += i*i
return total
# 假设df是一个已经定义的DataFrame,并且'列标签'是其中的一列
# 平方和(df['列标签'])
在groupby对象中,想要使用自定义函数或python系统库中的函数,函数的写法不带引号,如果使用pandas中的函数,函数名需要加上引号也就是字符串形式
不通过pandas,将表格读取成字典
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('多表合并汇总.xlsx')
dic_all={}
for ws in wb.sheets: #遍历工作簿中每一张工作表
#如果以字典的形式进行读取,就忽略列标签这一行,从内容行开始读取,所以起始单元格不是A1而是A1
rng=ws.range('A2').expand('table').value
for row in rng: #row代表一行
if row[0] not in dic_all: #将每一行的第一个单元格作为键,先检查这一行的第一个单元格是否在字典中作为键存在,如果没有,就新建一个键
dic_all[row[0]]=row[1:]
else:
if row[3] is not None:
dic_all[row[0]][2]+=row[3]3.数据表比对
此处为语雀视频卡片,点击链接查看:[3.13]–第二十三回 数据表比对.mp4
最基础的表格对比方法,只取两张表格相同的内容,可以通过pandas的merge方法,
默认情况下,merge采用内连接的形式,即两张表格的连接键上都有匹配的行时(键和内容都相同),才会出现在最后的匹配结果中,如果链接键在一张表上存在,而另一张表上不存在,那么不匹配的行将不会出现在最后的匹配结果中。
pd.merge(df1,df2)
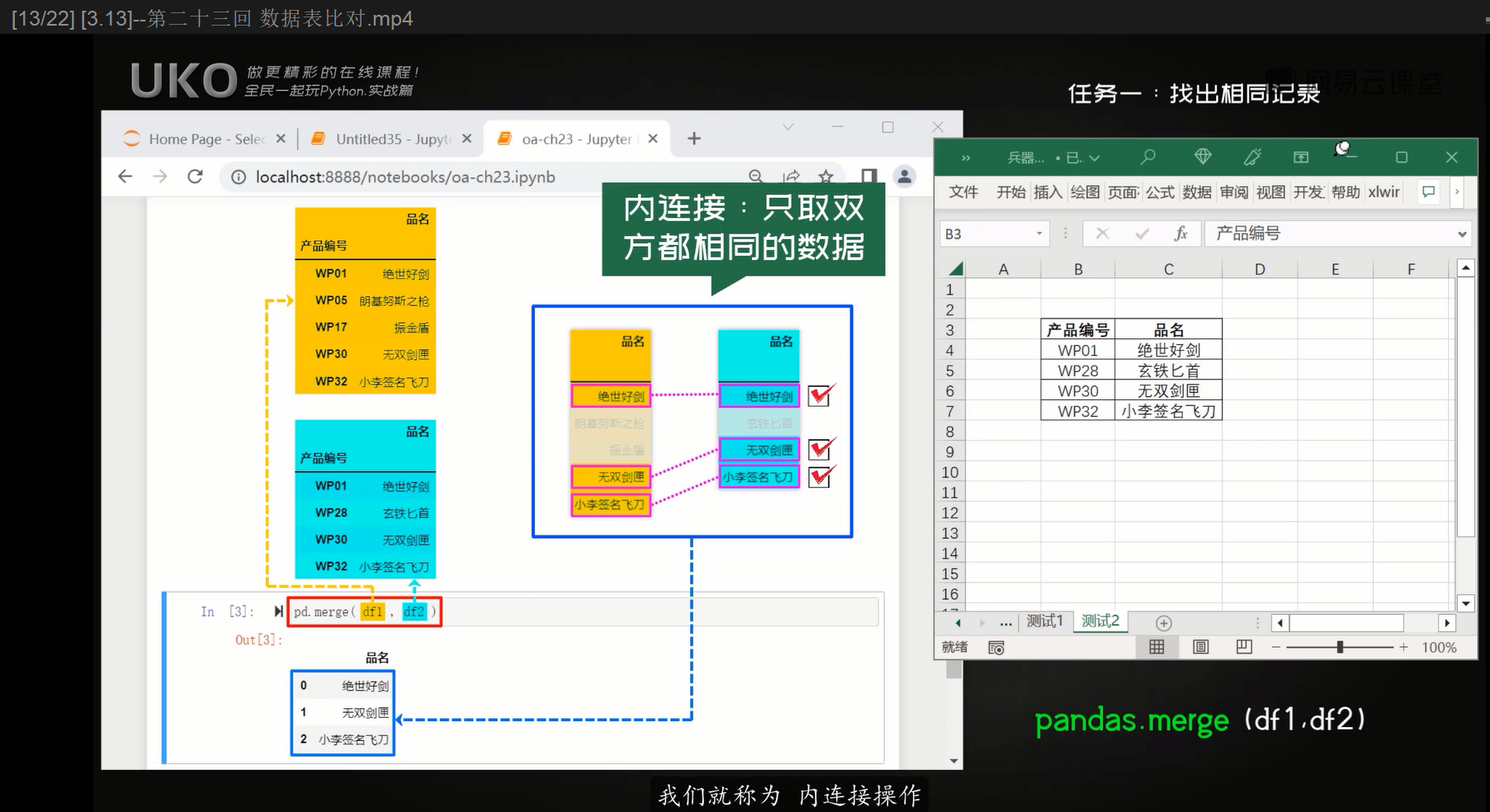
Pandas的merge方法的连接方式主要有(以下所说的‘键’指的是列标签):
- 内连接【how=’inner’】:只保留两个DataFrame中 共同键和共同值一致 的 行 (把两张df名字相同的列标签的列放在一起作比较)(在实际测试中,如果左右两个DataFrame相同的键和相同列标签下的值都一致(可能右边df有左边df没有的列标签),那么行会出现在匹配结果中,如果右边df有的列标签左边的列标签没有,或反之,这些额外的列标签也会出现在匹配结果中)
- 外连接【how=’outer’】:保留两个DataFrame中所有的键,不管它们是否匹配,如果某个键在一个DataFrame中个存在而在另一个中不存在,那么该键在结果中将以NaN填充缺失的值
我们可以通过查看合并结果中NaN的分布情况,来知道这一行数据来自左边表格还是右边表格,如果一行数据是全的,表示这一行数据来自左右两边表格,除了用肉眼观察,还可以设置参数【indicator=True】,这样以来,在匹配结果的表格中,会多出一个名为 _merge 的新列,这个列会显示每一行数据是如何被合并的。left_only: 这一行数据只来自左边的 DataFrame(即在右边的 DataFrame 中找不到对应的匹配项)。both: 这一行数据在左右两个 DataFrame 中都有对应的匹配项。
如果想要筛选出匹配结果中,数据来自两张表的行,只需要【df[df[‘_merge’]==’both’]】,如果只想要得到,只有左边数据表才有的数据,可以使用【df[df[‘_merge’]==’left_only’]】
- 左连接【how=’left’】:保留左边DataFrame中所有的键,与右边DataFrame的键进行匹配,如果右边DataFrame中没有匹配的键,则相应的位置用NaN填充
(使用场景是,如果右边的DataFrame,有着左边DataFrame没有的列标签(或相反),使用左连接的方式,可以在保留左边数据表所有内容的同时,将右边DataFrame中额外的列标签的列加入到匹配结果中)
- 右连接【how=’right’】:与左连接相反
上述方法只会将两边DataFrame中的列进行比较,忽略两张DataFrame的index
许多情况下,两张DataFrame拥有相同的列,但是这个相同的列在两张DataFrame中有着不同的列标签名,因此可以通过left_on和right_on来让merge方法知道,两张DataFrame中不同列标签名字的列其实是同一列,
此外,由于merge方法经常会忽略DataFrame的index,可以通过设置【left_on=df1.index,right_on=df2.index】,让两张数据表的index也加入到匹配与匹配结果中(ChatGPT说不行,需要通过【left_index=True,right_index=True】)
import pandas as pd
import xlwings as xw
from pprint import pprint
wb=xw.Book('table/房源数据.xlsx')
df1=wb.sheets['Sheet1'].range('A1').options(pd.DataFrame,expand='table').value
df2=wb.sheets['Sheet2'].range('A1').options(pd.DataFrame,expand='table').value
print(pd.merge(df1,df2,how='inner',left_on=df1.index,right_on=df2.index))纠正:left_on与right_on的作用是,根据两边特定的列寻找共同点,其他列标签的名字都会加上_x或_y
更新:以下代码的作用是,只根据两张数据表的index寻找共同点,只要两张数据表都拥有相同的index,即使相同列标签下的数值不同,这样的行也会出现在匹配结果中,此外,还会将两张数据表的所有列都放在匹配结果中,左边数据表的列标签名结尾会加上_x,右边数据表的列标签名会加上_y
【df3=pd.merge(df1,df2,left_on=df1.index,right_on=df2.index)】
left_on和right_on的参数可以是一个列表,列表里各自是不同的列标签,表示只有两边df的两列的内容一致时,才出现在匹配结果中
在使用 Pandas 的 merge 方法合并两个 DataFrame 时,如果两个 DataFrame 中有相同名字但不是用来合并的列,Pandas 会自动为这些列添加后缀 _x 和 _y 来区分它们。其中 _x 后缀会添加到左边 DataFrame(left)的列名后,而 _y 后缀会添加到右边 DataFrame(right)的列名后。
例如,如果 df1 和 df2 都有一个名为 C 的列,但这个列不是用来合并的列,在合并后的结果 DataFrame 中,这个列将会出现为 C_x 和 C_y,分别代表 df1 中的 C 列和 df2 中的 C 列。
如果你不希望出现这样的后缀,或者想使用其他后缀,可以使用 merge 方法的 suffixes 参数。这个参数接收一个包含两个字符串的元组,分别用于左右 DataFrame 的列名后缀。例如:
result = pd.merge(df1, df2, left_on='A', right_on='B', suffixes=('_left', '_right'))
这样,在合并结果中,原本属于 df1 的列将使用 _left 后缀,而属于 df2 的列将使用 _right 后缀。
4.高亮显示与字典比对技巧
此处为语雀视频卡片,点击链接查看:[3.14]–第二十四回 高亮显示与字典比对技巧.mp4
5.全表搜索与排序
此处为语雀视频卡片,点击链接查看:[3.15]–第二十五回 全表搜索与排序.mp4
如果想要对表格中的特定数字操作,比如,如果表格中某个数值小于6,就加上66666,代码可以是(注意,如果存在字符串内容的列会报错):
import pandas as pd
import xlwings as xw
from pprint import pprint
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
wb=xw.Book('table/data.xlsx')
ws=wb.sheets['weather']
df=ws.range('a1').options(pd.DataFrame,expand='table').value
#print(df)
for col in df.columns:
df.loc[df[col]<6,col]=df.loc[df[col]<6,col]+1
print(df)查找数值小于6的单元格并修改单元格颜色:
import pandas as pd
import numpy as np
import xlwings as xw
from pprint import pprint
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
wb=xw.Book('table/data.xlsx')
ws=wb.sheets['weather']
df=ws.range('a1').options(pd.DataFrame,expand='table').value
#print(df)
#查找数值小于6的单元格并修改单元格颜色
for col in df.columns:
df[col]=pd.to_numeric(df[col],errors='coerce') #尝试将每一列转换为数字格式,无法转换的将变成nan
rows,cols=np.where(df.values<6) #得到数值小于6的单元格的行号和列好
for i in range(len(rows)):
ws.range(rows[i]+2,cols[i]+2).color=0x00ff00 #+2是因为在当前Excel表格中,+2才能得到行号和列号的实际位置
根据列标签进行排序
由于是调用Excel官方的API,相当于使用了Excel【数据】选项卡中的【排序】,KEY1和KEY2相当于排序一依据和次要关键字,Header=True相当于勾选了‘数据包含标题’,Orientation=True相当于‘选项’中的‘按列排序’(Excel默认的方式)
import pandas as pd
import numpy as np
import xlwings as xw
from pprint import pprint
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
wb=xw.Book('table/data.xlsx')
ws=wb.sheets['weather']
#查找数值小于6的单元格并修改单元格颜色
rng=ws.range('a1').expand()
rng.api.Sort(Key1=ws.range('C1').api,Key2=ws.range('D1').api,Header=True,Orientation=1)
#其他排序参数
#Order1=1/2 主关键字 升序/降序 排序
#Order2=1/2 次关键字 升序/降序 排序
#MatchCase=True/False 区分大小写
SortMathod=1/2 按字母(拼音)排序/按笔画排序
6.单元格格式处理
range对象的font对象可以修改字体的 颜色/粗体/斜体/字体/字号
range.font也是一个xlwings.Font对象
rng.font.color=(r,g,b)
rng.font.bold=True/False
rng.font.name=’微软雅黑’
rng.font.size=16
rng.color=(r,g,b) #设置背景色
设置下划线和对齐方式需要调用api
rng.api.Font.Underline=True #设置下划线(原生对象首字母需要大写)
rng.api.HorizontalAlignment=-4131 或者写成 xw.constants.HAlign.xlHAlignLeft(Left可以改Right)(记不住数值可以写这个) #水平方向向左端对齐
rng.api.VerticalAlignment=-4160 数值可以写成xw.constants.VAlign.xlVAlignTop(Top可以改Bottom) #垂直方向顶端对齐
如果想要都居中对齐,可以把两个最后一个单词改成Center
如果想要清空格式,可以写:
Range.clear_formats() #清空格式
Range.clear_contents() #清空内容
Range.clear() 格式与内容全部清空
想要修改行高与列宽,可以通过xlwings中的column_width和row_height属性,默认情况向,列宽的单位是字符的个数,行高的单位则是像素(所以两个参数设置成同一个数字并不会变成正方形的单元格)
range.column_width=10
range.row_height=10
想要修改边框线,则需要调用api
rng.api.Borders.Weight=1
rng.api.Borders.LineStyle=1 #线型
rng.api.Borders.Color=0xffffff #修改边框线颜色,调用api,颜色数值必须是16进制格式,因为api无法识别Python元组
7.合并单元格处理
此处为语雀视频卡片,点击链接查看:[3.17]–第二十七回 合并单元格处理.mp4
如果多个单元格合并在了一起,Excel会认为,只有第一个单元格有内容,其他都是空单元格读取成DataFrame,那些合并在一起的单元格拆分后除了第一个外都会变成None
在pandas中,如果想要将空单元格的内容等于上面的单元格的值,可以使用ffill()
df[‘列标签’]=df[‘列标签’].ffill()
range对象可以通过merge()方法合并成一个单元格
range()对象的merge_area属性可以返回该单元格所属的合并单元格范围,可以通过下标形式提取合并单元格中的第几个单元格,比如ws.range(‘b1’).merge_area[0]
merge_cells属性可以判断一个单元格是否已经跟其他单元格合并在了一起,range.merge_cells返回的是True/False
ummerge()可以拆分单元格
8.工作表插入图片
pictures图片管理员(容器)
picture图片对象
可以通过pictures.add()来添加图片
标准写法:ws.pictures.add(r’文件路径’)
推荐写法:将文件路径作为一个Path对象,然后通过Path对象来插入
from pathlib import Path
img=r'文件路径'
ws.pictures.add(img)add()方法的参数:
anchor=ws.range(‘A1’) #插入图片的位置
width和height可以设置插入图片的宽高
width=ws.range(‘A1’).width,height=ws.range(‘A1’).height #将图片调整成适应单元格的大小,如果都是高度大于宽度,直接指定高度即可,如果宽高都设置参数可能导致图片变形
left和top参数可以设置图片插入的任意位置
update()方法可以图片的替换
delete()方法可以对图片进行删除操作
2 thoughts on “Python办公自动化【4】(Excel自动化(下))”